Introduction
Enterprise generative AI adoption has moved well past the curiosity phase - 71% of organizations now regularly use GenAI in at least one business function, according to McKinsey's 2025 State of AI survey. Yet more than 80% of those same organizations report no measurable EBIT impact from their investments.
The gap between deployment and value comes down to execution, not technology.
For enterprises in Oil & Gas, Healthcare, Manufacturing, Retail, and the Public Sector, GenAI implementation spans data architecture, infrastructure decisions, compliance frameworks, legacy integrations, and organizational change - all at once. Treating it as a plug-and-play software rollout is the fastest path to a stalled pilot.
This guide is for CIOs, CTOs, and digital transformation leaders who have moved past evaluation and need a structured, phase-by-phase roadmap: from readiness assessment through production deployment and long-term operations - with the operational detail to act on it.
Key Takeaways
- Enterprise GenAI requires organizational, data, and infrastructure readiness before any model is selected or deployed
- A phased approach - discovery, PoC, pilot, production, operations - separates working deployments from abandoned ones
- Governance, RBAC, and compliance controls must be embedded at the architecture level, not retrofitted afterward
- Gartner estimates 30% of GenAI projects won't survive past PoC - post-deployment validation keeps yours out of that group
- Change management and user adoption are implementation deliverables, not afterthoughts
Is Your Enterprise Ready? Prerequisites Before Adopting Generative AI
Most enterprises do not have binary readiness - they have partial readiness across several dimensions. Proceeding without understanding those gaps is how projects stall mid-pilot or fail a compliance audit when it matters most.
Organizational Readiness
Two questions define organizational readiness:
- Does someone own the outcome? Executive sponsorship without a clear mandate is insufficient. There must be a named individual accountable for AI outcomes - not just the technology delivery, but the business result.
- Does your team have the skills to execute? IBM's enterprise AI research identifies limited AI skills as a barrier for 33% of enterprises. Before scoping any project, assess your team honestly across data engineering, ML operations, and AI governance - then commit to whether you'll upskill, hire, or partner externally before the project starts.
Use cases must tie to measurable business objectives. "Exploring AI capabilities" is not a business objective. "Reducing claims processing cycle time by 30%" is.
Data and Compliance Readiness
Data readiness is the most underestimated prerequisite in enterprise AI. Gartner's survey of 1,203 data management leaders found that 63% lack - or aren't sure they have - the right data management practices for AI. Gartner predicts 60% of AI projects unsupported by AI-ready data will be abandoned through 2026. A model that works in a sandbox on clean sample data will break in production against messy, siloed enterprise data - and that gap is what kills pilots.
Regulatory requirements vary by sector:
| Sector | Key Compliance Obligations |
|---|---|
| Healthcare | HIPAA minimum-necessary rules for PHI; clinical data governance |
| Public Sector | OMB M-24-10 Chief AI Officer designation; rights-impacting AI controls |
| Retail | CCPA sensitive personal information rights; PII handling restrictions |
| Energy / Manufacturing | Operational safety data controls; IP and process data governance |
| EU-touching operations | EU AI Act GPAI obligations; EDPB anonymity standards for AI models |

Non-negotiables before proceeding:
- Data access approvals are unresolved → stop
- Regulatory compliance obligations are undefined → stop
- No executive-level accountability for AI governance → stop
Building the Foundation: Infrastructure, Data, and Governance
Infrastructure Architecture
The deployment model decision - cloud-native, on-premises, or hybrid - needs to be made early, because it affects everything downstream. Roughly 50% of financial services, healthcare, and government organizations expect to primarily use dedicated on-premises or colocation infrastructure for GenAI over the next 18 months, according to an IDC analysis of regulated industries.
Production-grade systems must be infrastructure-agnostic. Gartner warns that 50% of enterprises will face delayed AI upgrades or rising maintenance costs by 2030 due to unmanaged GenAI technical debt from vendor lock-in. Cybic's architecture is designed to operate across AWS, Azure, and Google Cloud precisely to avoid this: no rigid ecosystem dependencies, no locked-in upgrade paths.
Data Platform Requirements
Before any model selection begins, the data foundation must be in place:
- Governed data platform: Snowflake or Databricks are common anchors; the key is that data lineage, access policies, and quality controls are enforced at the platform level
- Clean enterprise integrations: Reliable connectors to ERP, CRM, and Health Information Systems; not one-off extracts
- Resolved data ownership: Who approves access to which datasets, documented and enforced
Cybic's data engineering work consistently begins with a data landscape audit and gap analysis - this step identifies whether the organization actually has AI-ready data before any model work begins.
Model Selection
Model selection is an architectural decision. Each option involves real trade-offs that affect cost, control, and performance:
- General-purpose LLMs (OpenAI, Anthropic): Fast to deploy, strong out-of-the-box performance, but require careful data privacy review - confirm that your prompts and completions are not used for model training by the provider
- Open-weight models (LLaMA, Mistral): Greater control over deployment and data handling; better fit for on-premises or air-gapped environments; require more internal operational capability
- Fine-tuned domain-specific models: Highest performance on specialized tasks (clinical notes, legal contracts, engineering specifications); higher up-front cost and longer build time

Evaluate models on representative enterprise data before committing. Benchmark scores on public datasets tell you little about how a model performs on your documents, your workflows, and your edge cases.
Governance Architecture
Governance embedded at design time costs far less than retrofitting controls after deployment. The minimum requirements are:
- RBAC: Role-based access controls enforced at the data and model layer
- Encryption: Data protected in transit and at rest
- Auditability: Every AI-driven action logged and traceable
- Data use policy: A firm, documented commitment that proprietary enterprise data will not be used to train third-party models
Fragmentation is one of the most common governance failures in enterprise AI: multiple teams running isolated projects on separate tools, with no unified audit trail. Cybic's Drava platform addresses this by connecting data, automation logic, and AI models within a single governed system - giving compliance teams the visibility they need without blocking engineering velocity.
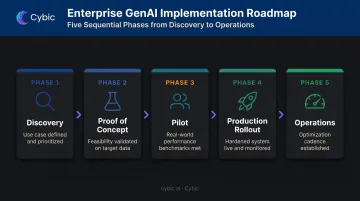
How to Implement Generative AI in Your Enterprise: A Phase-by-Phase Guide
Moving too fast from idea to deployment without validation gates is the leading cause of pilot failure. Each phase below has defined outputs and exit criteria - skipping them is what puts you in Gartner's 30% abandonment statistic.
Phase 1: Discovery and Use Case Definition
Goal: Identify high-impact, low-risk use cases aligned to business priorities - not the most technically interesting ones.
Required outputs before moving forward:
- Problem statement approved by the business sponsor
- Data inventory with confirmed access approvals
- Success metric framework with defined thresholds
High-impact/low-risk starting points: document summarization, internal knowledge retrieval, workflow routing. These validate the infrastructure and governance model before you tackle customer-facing or decision-making applications.
Phase 2: Proof of Concept
Goal: Controlled feasibility test on a clean, representative dataset.
Define exit criteria before the PoC begins: accuracy thresholds, latency requirements, compliance checkpoints. Without pre-defined gates, PoCs drift into months of inconclusive testing.
McKinsey's research shows GenAI projects most frequently take 1–4 months from launch to production; highly customized or proprietary models are 1.5x more likely to take 5+ months.
Phase 3: Pilot Deployment
Goal: Bring the validated model into a limited real-world environment with a defined user group.
Key outputs:
- Deployment checklist signed off by security and compliance
- User feedback logs treated as product metrics - not anecdotal input
- Risk mitigation plan for identified failure modes
- Shadow KPIs running alongside existing processes
The pilot environment must use production-representative data and infrastructure. A PoC that runs on clean, curated data and isolated infrastructure tells you almost nothing about production performance.
Phase 4: Production Rollout
Goal: Harden the system for full operational deployment.
Before promoting to production, confirm:
- Service-level objectives (SLOs) defined and tested
- Rollback procedures documented and rehearsed
- Observability dashboards live
- Change-control logs active
- Runbooks in place for operations teams
Production is the beginning of operations, not the finish line.
Phase 5: Operations and Continuous Optimization
Goal: Sustain and improve system performance over time.
AI systems degrade without active oversight. Operational requirements:
- Model drift monitoring: Automated detection of performance degradation
- Retraining schedules: Defined triggers for when retraining is initiated
- Performance dashboards: Accessible to both technical and business owners
- Named owner: A specific person responsible for weekly metric reviews

Most enterprise value from GenAI is captured in this phase, not at launch.
Post-Deployment Validation: Confirming Your System Is Working
Deployment is not validation. Before broad rollout, three distinct checks are required.
Functional Validation
Confirm the system produces accurate, consistent outputs within the defined use case parameters. Test across edge cases, high-load scenarios, and - if applicable - multilingual inputs. The NIST GenAI Profile recommends comparing outputs against known ground-truth data to assess accuracy, quality, and reliability.
Performance and Safety Benchmarks
- Establish baseline metrics for accuracy, latency, and escalation rates
- Run red-teaming exercises to surface failure modes before users encounter them (the EU AI Act requires adversarial testing for GPAI models with systemic risk)
- Confirm RBAC, audit logging, and data protection controls are live - not just configured in a staging environment
User Adoption Validation
A technically correct system that employees don't use delivers no value. Treat low adoption as a deployment signal - the friction point is almost always in the rollout, not the technology itself.
In the first 30 days, focus on:
- Measuring early adoption rates against defined baselines
- Gathering structured user feedback through surveys or brief interviews
- Identifying specific workflow steps where drop-off or workarounds occur
Common Enterprise GenAI Adoption Pitfalls and How to Fix Them
Governance Added as an Afterthought
Security controls and compliance frameworks get bolted on after deployment - creating gaps that expose the organization to breaches or regulatory violations.
Define RBAC, data handling policies, and auditability requirements before a single model is deployed. The IBM 2024 data breach report puts the global average breach cost at $4.88M. Governance-by-design costs a fraction of that.

The Pilot-to-Production Gap
A PoC performs well in a controlled environment but fails under real-world data volumes, system integrations, and concurrent users.
Design the pilot on production-representative data and infrastructure from day one. Pre-define performance SLOs that must be met before production promotion - and treat any SLO miss as a hard stop before production promotion.
Low User Adoption After Deployment
The system is technically functional but sees minimal use - low ROI follows, and executive skepticism is rarely far behind.
Treat adoption as an implementation deliverable, not an afterthought. That means:
- Assigning a named adoption lead from the start
- Building AI capabilities into existing workflows, not alongside them
- Creating a structured feedback loop at launch - not a survey three months later
Pro Tips for Successful Enterprise GenAI Adoption
Start with use cases that are high-impact and low-risk. Document summarization, internal knowledge retrieval, and workflow routing are faster to validate and easier to govern than customer-facing or decision-making applications. Early wins build organizational confidence and create the operational track record needed to fund larger deployments.
Treat model selection as an architectural decision. The choice of LLM affects data privacy, cost, latency, and compliance posture for the life of the system. Evaluate on representative enterprise data before committing, and confirm the model can operate within your data residency and governance constraints.
Know when to bring in an engineering-led implementation partner. If your team lacks production GenAI deployment experience, enterprise-grade governance expertise, or integration depth with legacy systems, bringing in a specialist prevents costly rework. Cybic, for example, embeds governance at the architecture level from day one - integrating AI systems directly into existing enterprise infrastructure and compliance requirements rather than retrofitting controls after the fact.
Frequently Asked Questions
How long does enterprise generative AI implementation typically take?
McKinsey's research shows most GenAI projects take 1–4 months from launch to production. Highly customized or proprietary models are 1.5x more likely to take 5+ months. Full enterprise rollouts involving complex integrations and regulated data can extend to 6–9 months when compliance validation is included.
What data infrastructure do we need before adopting generative AI?
The minimum: governed data pipelines, a reliable data platform (Snowflake or Databricks are common), and clean integrations to enterprise systems like ERP and CRM. Data access approvals must be resolved before any model work begins - unresolved access issues will stop a project mid-implementation.
How do enterprises ensure data security and compliance when deploying generative AI?
Implement RBAC at the data and model layer, ensure encryption in transit and at rest, and confirm all AI-driven actions are logged and auditable. Verify that proprietary enterprise data is contractually excluded from third-party model training - confirm this with the model provider before deployment, not after.
What is the difference between a GenAI pilot and a full production deployment?
A pilot is a limited real-world test with a defined user group and shadow KPIs running alongside existing processes. Production requires SLOs, observability dashboards, rollback procedures, change-control logs, and full operational governance - none of which exist in a pilot. Promoting a system before it meets defined SLOs is the primary cause of production failures.
How do we measure ROI from enterprise generative AI initiatives?
Track these against baselines established during discovery:
- Reduction in manual task hours
- Cycle time improvements
- Cost per transaction
- User adoption rates
- Accuracy benchmarks
Without pre-defined baselines, ROI measurement becomes guesswork.
What are the most common reasons enterprise GenAI projects fail?
The most common failure patterns:
- Governance added too late in the build cycle
- PoC environments that don't reflect production reality
- No change management plan before rollout
- Unclear ownership of AI outcomes post-deployment
Gartner identifies poor data quality, inadequate risk controls, escalating costs, and unclear business value as the primary drivers of PoC abandonment.