Introduction
Generative AI application development is the practice of building software systems that use large language models and foundation models to generate content, automate reasoning, and interact with users in ways traditional software cannot.
For enterprise leaders in healthcare, manufacturing, oil and gas, retail, and the public sector, the pressure to implement GenAI is real - but most available guidance targets developers, not the operational and strategic decisions that actually determine whether a deployment succeeds or fails.
McKinsey estimates generative AI could add $2.6 to $4.4 trillion annually to the global economy across use cases. That figure explains why GenAI has shifted from experimental initiative to strategic infrastructure decision. Getting there without expensive mistakes is a different challenge entirely.
This guide covers:
- What GenAI application development actually involves
- How the end-to-end development process works
- Enterprise-specific factors that must be addressed before a single line of code is written
- The failure modes that consistently derail otherwise well-funded programs
Key Takeaways
- Most enterprise GenAI apps are built on Retrieval-Augmented Generation (RAG) - not custom-trained models
- Build sequence: define use case → select model → design retrieval architecture → integrate data → evaluate → deploy with monitoring
- Data quality and governance must be resolved before deployment, not after
- The most common failure modes: skipping the POC stage, building unnecessary custom models, and ignoring hallucination risk
- Not every workflow suits GenAI: deterministic, zero-tolerance processes typically require rule-based or conventional software
What Is Generative AI Application Development?
Generative AI application development is the process of building software systems that use pre-trained foundation models - large language models (LLMs) or vision models - to generate text, analyze documents, support decision-making, or automate complex reasoning tasks.
That's a meaningful distinction from traditional software, which executes fixed logic. A conventional rule engine either matches a condition or it doesn't. A GenAI application understands context, generates responses dynamically, and can handle tasks that were never explicitly programmed.
How It Differs from Conventional AI/ML
| Traditional ML | Generative AI | |
|---|---|---|
| Training | Labeled data for specific tasks | Pre-trained on broad data; no task-specific retraining |
| Scope | Narrow (fraud detection, churn prediction) | Broad (summarization, Q&A, drafting, analysis) |
| Outputs | Deterministic, fixed categories | Dynamic, context-driven responses |
| Flexibility | One model per task | One model handles multiple task types |

A single GenAI model can summarize a contract, answer questions about a policy document, and draft a maintenance report - without retraining for each.
Core Output Types
Enterprise GenAI applications generally fall into a few categories:
- Conversational interfaces - chatbots, enterprise copilots, internal knowledge assistants
- Document intelligence - summarization, extraction, classification, and analysis of unstructured documents
- AI agents - systems that take sequential, goal-driven actions across multiple enterprise systems
- Code generation - automated development assistance and legacy code translation
- Image and multimodal analysis - visual inspection support, diagram interpretation, document OCR
Cybic builds across all of these categories for enterprise clients. LLM-powered document intelligence and enterprise copilots are among the most commonly deployed, typically integrated into existing workflows with governance controls on AWS, Azure, and Google Cloud.
How Generative AI Application Development Works
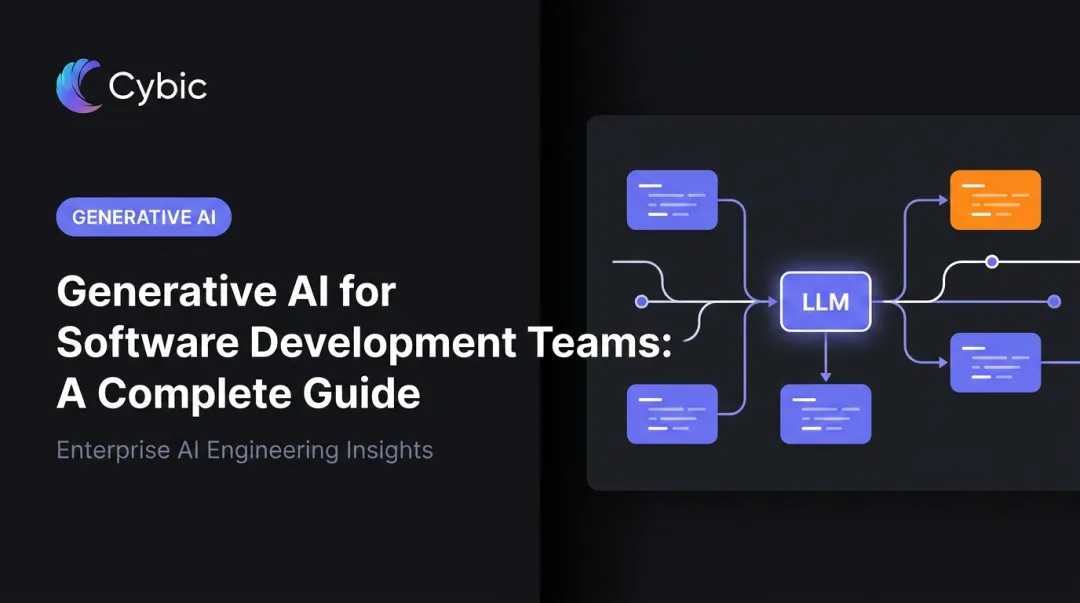
Most enterprise GenAI applications don't involve training a custom model. They follow an architectural pattern called Retrieval-Augmented Generation (RAG) - a framework that connects an LLM to a retrieval layer so the model responds based on your organization's specific data rather than its general training alone.
RAG is the dominant enterprise pattern because it avoids the cost and risk of fine-tuning while keeping outputs grounded in current, proprietary information.
What a Production GenAI App Actually Requires
Beyond the basic RAG core, a production-ready application includes:
- Vector database - stores embeddings of enterprise documents so relevant context can be retrieved at query time
- Orchestration layer - manages the flow between retrieval, prompt construction, and model response
- Logging and monitoring - tracks query patterns, output quality, and system performance over time
- Access control layer - enforces role-based permissions so users only access information appropriate to their role
- Output validation - catches problematic responses before they reach end users
Model selection adds another dimension. Teams evaluate models across four criteria:
- Modality - text-only, vision, or multimodal support
- Latency requirements - acceptable response time under production load
- Cost per token - total inference cost at expected query volume
- Feature support - function calling, fine-tuning availability, context window size
Benchmark against real business scenarios, not vendor benchmarks. Generalized public models frequently outperform specialized alternatives for practical enterprise tasks.
The Three Development Stages
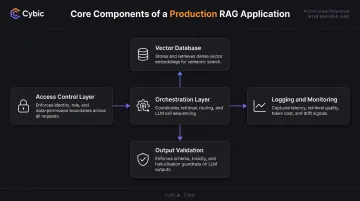
Step 1: Define the Use Case and Evaluate Fit
Every GenAI project starts with a clear, bounded problem statement and a testable success metric. Teams that skip this step build technically functional applications that fail to deliver measurable business value. The use case must identify the data source, the intended user, and the specific outcome the system is expected to improve.
GenAI is not appropriate for every workflow. Processes requiring exact, reproducible outputs - financial calculations, binary regulatory compliance checks, real-time safety-critical control systems - are better served by conventional software. GenAI excels at unstructured language tasks.
Step 2: Build and Validate the Architecture
Architecture decisions made early determine long-term adaptability. The choice of model provider, vector database, orchestration framework, and infrastructure (cloud, hybrid, on-premises) locks in dependencies that are expensive to reverse. Modular, infrastructure-agnostic design allows teams to swap model providers as the market evolves without rebuilding the application layer. This flexibility is a practical necessity given how quickly LLM pricing and capability gaps shift.
Cybic designs solutions to operate across AWS, Azure, and Google Cloud without locking clients into a single provider, which matters when model pricing and capability gaps shift year over year.
Step 3: Test, Evaluate, and Deploy
Evaluation requires a purpose-built dataset of prompt-and-expected-response pairs covering edge cases, not just typical queries. Good evaluation combines automated metrics with human review.
Deployment decisions - fully managed versus self-managed, latency versus cost tradeoffs - must reflect anticipated production traffic and compliance requirements before the system goes live.
Critical Factors for Enterprise GenAI Success
Data Quality Comes First
A GenAI application is only as accurate as the data it retrieves and reasons over. Disorganized, siloed, or incomplete enterprise data produces unreliable outputs regardless of model quality. Cybic's own data practice notes that 80% of enterprise data is unstructured, siloed, or underutilized - and that's before considering whether it's been formatted for retrieval pipelines.
Auditing and structuring knowledge repositories must happen before building retrieval architecture - skipping this step forces costly rework later.
Governance Built Into the Architecture
Enterprise GenAI systems require security controls, role-based access controls (RBAC), auditability of AI-driven actions, and data governance policies to be embedded at the architecture level - not retrofitted after deployment.
This is especially non-negotiable in regulated industries. Healthcare organizations must align with HIPAA; financial services face SOC 2 and GDPR requirements. When compliance is retrofitted after deployment, the result is expensive rearchitecting - and real regulatory exposure while that work is underway.
Cybic's Drava platform addresses this directly - it's a governed AI automation platform with RBAC, encrypted data protection in transit and at rest, full auditability of AI actions, and a strict policy against using proprietary enterprise data to train underlying models. Unlike assembling governance from separate tools, these controls are built in, not added afterward.
Hallucination Risk Is Real and Manageable
LLM hallucination - confident but factually incorrect output - is a documented risk across all major providers. Research on LLM hallucination rates shows figures as high as 82% in certain contexts, though production rates vary significantly by use case and mitigation approach.
Proven mitigation strategies include:
- High-quality RAG retrieval that grounds responses in verified source documents
- Chain-of-thought prompting that makes reasoning steps explicit and checkable
- Confidence scoring and output validation layers that flag low-confidence responses
- Human-in-the-loop review for high-stakes decisions
No approach eliminates hallucination entirely. The architecture must reflect the acceptable risk threshold for the specific use case. A customer service chatbot and a clinical documentation system are not the same problem - treat them accordingly.
Infrastructure and Scalability Planning
Infrastructure decisions made after deployment consistently result in budget surprises. Planning for the following before go-live avoids the most common pitfalls:
- Traffic variability: Burst capacity needs differ sharply from steady-state usage
- Latency requirements: Real-time applications have tighter tolerances than async batch workflows
- Inference costs: Token costs at scale are easy to underestimate in early prototyping
- Provider dependency: Multi-cloud and infrastructure-agnostic design enables cost optimization and resilience as usage grows
Common Pitfalls in Enterprise GenAI Development
Skipping the Proof of Concept
Many organizations move directly from use case identification to full-scale implementation. A well-designed POC using a realistic but limited dataset identifies data gaps, tests accuracy thresholds, and produces real cost estimates before significant engineering resources are committed. Skipping this stage consistently leads to longer timelines and higher costs, not shorter ones.
Building Custom Models When Public LLMs Are Sufficient
Fine-tuned or custom-trained models are rarely necessary for enterprise applications. Publicly available LLMs combined with RAG retrieval provide strong performance for most business tasks at a fraction of the cost and maintenance burden.
Custom model development is worth considering only when:
- RAG plus prompt engineering leaves a demonstrable performance gap
- The domain requires proprietary terminology or reasoning that public models can't approximate
- Data sensitivity prevents use of any third-party inference endpoint
Applying GenAI to Deterministic Workflows
A common organizational error is applying GenAI to processes that require exact, reproducible outputs. Financial calculations, compliance checks with binary pass/fail outcomes, and real-time safety-critical control systems need conventional rule-based or ML-based software.GenAI introduces variability by design: that's a feature for unstructured language tasks and a liability for deterministic computation.

Treating Governance as a Post-Deployment Task
Organizations frequently plan to "add" access controls, audit logging, and data privacy protections after the system is built. This leads to expensive rearchitecting and exposes the organization to data breaches or compliance violations in the interim.
The Samsung ChatGPT incident is a clear illustration: engineers inadvertently exposed proprietary source code through a public LLM interface because no guardrails were in place at launch. Security and governance must be architectural requirements established before development begins.
Conclusion
Generative AI application development at the enterprise level follows a structured path:
- Define the use case and success criteria
- Design a modular, integration-ready architecture
- Connect enterprise data through RAG pipelines
- Evaluate outputs rigorously before and after deployment
- Deploy with governance, monitoring, and iteration cycles in place
It's a continuous process, not a one-time build.
Organizations that see measurable business impact invest in the fundamentals first: data quality, modular architecture, embedded governance, and honest ROI measurement. Scaling comes after those foundations hold.
Cybic builds generative AI systems where governance and integration are architectural decisions, not afterthoughts. That approach cuts both risk and delivery time for enterprises that need production-ready systems, not prototypes.
Frequently Asked Questions
What is generative AI application development?
It's the process of designing and deploying software systems that use pre-trained foundation models (LLMs, vision models) to perform tasks like document analysis, conversational AI, and workflow automation. Unlike traditional software that executes fixed logic, these systems generate contextual responses dynamically based on input and retrieved data.
What's the best generative AI platform for app development?
There's no single best platform - the right choice depends on use case, governance requirements, infrastructure environment, and cost tolerance. Major options include Azure OpenAI, Google Vertex AI, AWS Bedrock, and open-source models. Best practice is benchmarking multiple models against real business scenarios before committing to one provider.
What is RAG and why does it matter for enterprise GenAI?
RAG (Retrieval-Augmented Generation) connects an LLM to a real-time retrieval system so the model responds based on your organization's specific data. Most enterprise teams choose it because it reduces hallucination, avoids retraining costs, and keeps outputs grounded in current, proprietary information.
How long does it take to build a generative AI application?
A focused proof of concept can be built in weeks; a production-ready system with full data integration, governance controls, and monitoring typically takes several months. Skipping the POC phase in favor of direct full-scale development consistently produces longer timelines, not shorter ones.
How do you prevent hallucinations in generative AI applications?
Key mitigations include RAG grounding, chain-of-thought prompting, output validation layers, and human review for high-stakes decisions. No approach eliminates hallucination entirely - the architecture must reflect the acceptable risk threshold for each use case.
What industries benefit most from generative AI application development?
Industries with high volumes of unstructured data and knowledge-intensive workflows see the strongest ROI: healthcare (clinical documentation and patient interaction), manufacturing (maintenance reporting and quality workflows), oil and gas (field safety and operational intelligence), retail (customer service automation and demand forecasting), and public sector (citizen services and document processing at scale).