
Predictive analytics changes the equation. Instead of responding to crises, healthcare organizations can identify which patients are trending toward one - before the crisis arrives. The gap between knowing this is possible and actually doing it, though, is where most implementations stall.
This article covers what predictive analytics in healthcare actually is, how the modeling pipeline works, where it delivers measurable results, what makes deployment difficult, and what governance-ready implementation looks like in practice.
Key Takeaways
- Predictive analytics uses historical and real-time health data to forecast future clinical and operational outcomes, not just explain what already happened
- Key use cases include readmission prevention, early disease detection, clinical decision support, and operational forecasting
- 71% of U.S. acute care hospitals now use predictive AI integrated with EHRs - up from 66% in 2023
- The biggest barriers are data fragmentation, HIPAA compliance, algorithmic bias, and acting on insights before the window closes
- Governance must be embedded in the architecture from day one, not added after deployment
What Is Predictive Analytics in Healthcare?
Predictive analytics uses historical and real-time health data - combined with statistical modeling, machine learning, and data mining - to forecast future clinical and operational outcomes. Unlike descriptive analytics, which tells you what already happened, predictive analytics tells you what's likely to happen next - and early enough to act on it.
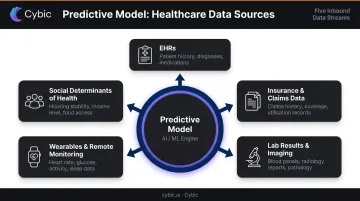
Primary Data Sources
Predictive models in healthcare draw from multiple input streams:
- Electronic health records (EHRs) - diagnoses, medications, procedures, clinical notes
- Insurance and claims data - utilization patterns, prior authorizations, cost history
- Lab results and imaging - structured diagnostic values and radiology findings
- Wearables and remote monitoring - continuous vitals, activity data, glucose readings
- Social determinants of health (SDoH) - housing stability, income, transportation access
Model quality depends heavily on data breadth and freshness across these sources. A readmission risk model trained on EHR data alone will miss signals that claims or SDoH data would catch.
The Shift This Enables
The deeper value of predictive analytics is organizational, not just technical. Care delivery shifts from reactive and symptom-driven to proactive and evidence-driven. Clinicians stop waiting for patients to present with a problem and start acting on probability - reducing avoidable admissions, easing care team burden, and lowering downstream costs.
How Predictive Analytics Works in Healthcare
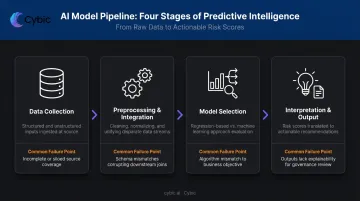
Most healthcare predictive pipelines follow four stages. Each one has distinct failure points.
Stage 1: Data Collection
Pipelines ingest both structured data (demographics, lab values, diagnostic codes) and unstructured data (clinical notes, imaging reports). Data breadth and freshness directly affect prediction quality - a model that only sees yesterday's lab values can't account for a patient's worsening trend over 48 hours.
Stage 2: Preprocessing and Integration
Raw healthcare data arrives fragmented across incompatible systems. Before any modeling begins, it must be cleaned, normalized, and unified. This stage is consistently underestimated.
Only 43% of U.S. hospitals routinely engaged in all four interoperability domains - sending, receiving, finding, and integrating patient data - as of 2023. For independent hospitals, that figure drops to 22%. Without unified data, even well-designed models operate on an incomplete picture.
Stage 3: Model Selection
Two primary modeling families apply in healthcare:
| Model Type | Examples | Best For |
|---|---|---|
| Regression-based | Logistic regression, decision trees, time series | Interpretable outputs, regulatory review, structured data |
| Machine learning | Neural networks, random forests, support vector machines | Complex patterns, unstructured data, high-volume predictions |
The right choice depends on the prediction task. A readmission risk score may prioritize interpretability for clinical review; a sepsis early-warning system may prioritize sensitivity in a high-stakes time window.
Stage 4: Interpretation and Output
Model outputs - risk scores, probability estimates, trend forecasts - must translate into actionable recommendations. Interpretability matters as much as accuracy here. A clinician who can't understand why a model flagged a patient is unlikely to act on it.
This points to the insight-to-action gap: many organizations generate solid predictions but lack the workflow integrations to operationalize them. The risk score exists - but without integrated alerting and clinical workflows, the intervention never happens.
Key Use Cases of Predictive Analytics in Healthcare
Readmission Prevention
Predictive models analyze post-discharge data - diagnosis codes, social risk factors, medication adherence signals - to flag patients likely to return within 30 days. The costs are concrete: AHRQ data puts the average adult 30-day all-cause readmission at $17,700, and CMS can reduce Medicare payments to hospitals with excess readmissions by up to 3%.
The evidence for predictive intervention is concrete. A real-time readmission risk score deployed alongside risk-adjusted interventions reduced 30-day readmission rates in one medicine department from 11.7% in 2017 to 10.1% in 2019 - saving an estimated 3,200 inpatient bed days annually.
Early Disease Detection and Risk Stratification
Risk scoring models stratify patient populations by likelihood of developing serious conditions - cardiovascular disease, diabetes, sepsis - before symptoms escalate. A JAMA Network Open meta-analysis of 22 studies found sepsis alert systems were associated with a 19% reduction in mortality risk (RR 0.81), with electronic alerts showing even stronger results (RR 0.78).
Stratification works by assigning probability scores across a defined patient population, then directing clinical attention toward the highest-risk cohorts. For sepsis specifically, each hour of delay in treatment increases mortality risk - catching the signal at hour two instead of hour eight changes the clinical calculus entirely.
Clinical Decision Support
At the point of care, predictive analytics augments physician judgment by:
- Surfacing treatment response forecasts based on patient history and similar cases
- Flagging contraindications before orders are placed
- Recommending evidence-based protocols when diagnostic uncertainty is high
This reduces diagnostic guesswork without replacing clinical judgment. The goal is consistency: ensuring that what the evidence supports is actually what gets ordered.
Population Health and Operational Efficiency
Beyond individual patients, predictive models identify high-risk cohorts - polychronic patients, underserved populations, patients with fragmented care histories - for proactive outreach. Public health authorities apply similar models for outbreak forecasting and resource pre-positioning.
The operational case is equally urgent. The AHA's 2024 Health Care Workforce Scan reported that nearly 800,000 registered nurses - including 189,000 under age 40 - intended to leave by 2027 due to stress and burnout.
Predictive models directly address this pressure by:
- Forecasting patient volume to prevent understaffing during demand spikes
- Optimizing shift scheduling to reduce burnout-driven attrition
- Cutting no-show rates - the global average sits at 23% - through targeted outreach

Challenges and Governance Considerations
Data Fragmentation and Quality
Healthcare data is distributed across incompatible EHR systems, payer platforms, and device streams. Even when data exists, it's often not usable at the point where it matters. ONC data shows that while 71% of hospitals had electronic access to outside clinical information at the point of care in 2023, only 42% of clinicians actually used it.
Poor input data produces unreliable predictions regardless of model sophistication. Data quality is a prerequisite, not an afterthought.
HIPAA Compliance and PHI Protection
Any predictive analytics system touching patient data must comply with HIPAA's requirements for protecting Protected Health Information. The financial exposure is real: healthcare has carried the highest average data breach cost for over a decade, reaching $10.93 million per breach in 2023 - more than double the global average across all industries.
Compliance requires attention across several layers:
- Evaluate data storage architecture - cloud, hybrid, or on-premises - against your risk profile
- Ensure every vendor handling PHI has a signed Business Associate Agreement (BAA)
- Audit analytics infrastructure for any pathways that route PHI through non-compliant endpoints
HHS OCR guidance makes clear that cookie banners and privacy policies alone don't authorize PHI disclosure to third-party vendors.
Algorithmic Bias and Health Equity
Predictive models trained on historically biased datasets can entrench or amplify healthcare disparities. A landmark study published in Science found that a widely-used health-management algorithm systematically underestimated illness severity in Black patients because it used healthcare cost as a proxy for health need - a flawed assumption that, when corrected, would have increased the share of Black patients receiving additional care from 17.7% to 46.5%.
ONC data from 2024 shows the governance gap persists: while 82% of hospitals evaluated predictive AI for accuracy, only 74% evaluated for bias.
Governance Embedded by Design
Governance retrofitted onto a deployed system doesn't work. Healthcare AI architectures need access controls, audit trails, data lineage tracking, and regulatory alignment built in from the start.
Cybic's Drava platform is built on this principle. Its governance architecture includes:
- Role-based access controls (RBAC) to limit data exposure by user and function
- Encrypted data handling in transit and at rest
- Full audit trails for every AI-driven action and workflow
- No model training on proprietary client data - PHI never becomes training material
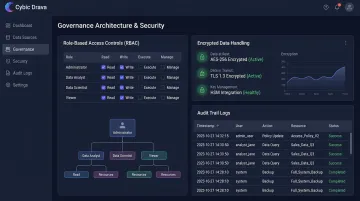
These controls are built into the architecture from the start, not added after deployment.
Turning Predictions into Action: What Implementation Looks Like
Selecting a model is the easy part. Making predictions operationally useful is where most implementations either succeed or fail.
Successful deployment requires three foundational capabilities:
- A unified data layer - breaking down silos so the model sees the complete patient picture, not partial slices from disconnected systems
- Infrastructure-agnostic deployment - running across cloud, hybrid, and on-premises environments to accommodate the diverse IT landscapes common in healthcare
- Workflow orchestration - connecting model outputs to care team alerts, automated messaging, or care management queues so predictions trigger actions rather than accumulating in dashboards
Cybic's Drava platform is built around exactly this architecture - connecting health data, ML models, and intelligent automation into a single governed system. The goal isn't a better dashboard; it's a system where a high-risk readmission score automatically routes to a care manager, not a spreadsheet.
That technical foundation only matters if care teams actually use the system. Provider acceptance is consistently underestimated in implementation planning. Systems built around how care teams actually work - with clear training and visible evidence that the tool reduces burden rather than adding to it - get adopted. Implementations designed around idealized workflows, by contrast, get abandoned.
Frequently Asked Questions
What is an example of predictive analytics in healthcare?
A hospital might use a patient's recent lab values, vital trends, diagnosis codes, and prior claims data to generate a 30-day readmission risk score at discharge. High-risk patients automatically trigger a care manager outreach within 48 hours - before a preventable return visit occurs.
Why is predictive analytics important in healthcare?
It shifts care delivery from reactive to proactive - reducing avoidable hospitalizations, helping clinicians make faster and more consistent decisions, and directing limited staff and resources toward the patients who need them most.
What data sources are used in healthcare predictive analytics?
Primary sources include EHRs, insurance and claims data, lab and imaging results, remote monitoring and wearable devices, and SDoH data. Model accuracy depends on integrating across these sources, not drawing from just one.
What are the biggest challenges of implementing predictive analytics in healthcare?
Key obstacles include data fragmentation across siloed systems, HIPAA compliance requirements, and the risk of algorithmic bias in models trained on unrepresentative data. Embedding predictions into actual clinical workflows also demands significant organizational change management.
How is AI different from traditional predictive analytics in healthcare?
Traditional predictive models apply predefined statistical equations to structured data. Machine learning goes further - processing unstructured inputs like clinical notes and imaging, identifying non-linear patterns, and refining predictions as new data arrives in ways static regression models cannot.


