
Introduction
Enterprise AI deployment for predictive analytics means integrating machine learning models into core business operations to continuously forecast outcomes and trigger decisions at scale. If you're an enterprise leader in Oil & Gas, Manufacturing, Healthcare, Retail, or Public Sector moving beyond proof-of-concept, this guide covers how deployment actually works and what separates projects that ship from those that stall.
Despite widespread discussion of predictive analytics in executive strategy, most organizations stall at the operational level. They can articulate what they want to predict equipment failures, customer churn, demand fluctuations but lack clarity on how to reliably move models into production workflows.
Research shows only 10-15% of AI pilot projects reach long-term production deployment due to integration difficulties, data quality issues, and organizational resistance. That gap between a validated model and a deployed one carries real costs: degraded operational performance, missed forecasting opportunities, and sunk investment.
Key Takeaways
- Enterprise AI deployment embeds trained ML models into live business systems and not dashboards or notebooks
- Success requires data infrastructure readiness, model validation, workflow integration, and ongoing governance
- Infrastructure gaps, poor integration, and absent governance kill more deployments than model quality ever does
- Key success factors include data quality, MLOps maturity, drift management, and compliance by design
- No unified data infrastructure or defined decision workflows means no ROI regardless of model sophistication
What Is Enterprise AI Deployment for Predictive Analytics?
Enterprise AI deployment for predictive analytics is the end-to-end process of taking a trained machine learning model and embedding it into production systems where it continuously generates forecasts, scores, or recommendations that inform or automate business decisions.
The outcome is a fundamental shift from reactive decision-making (responding after events occur) to proactive operations that act before outcomes materialize. This happens at the speed and scale enterprise environments demand: thousands of decisions per day, across distributed operations, with consistent logic and auditable outputs.
This differs from adjacent concepts in three concrete ways:
- Predictive analytics as a reporting function surfaces insights in dashboards but doesn't trigger action
- AI experimentation or proof-of-concept work validates models in controlled conditions but stops short of operational integration
- Deployment means the model is embedded in the workflow where decisions happen scoring leads in the CRM, triggering maintenance work orders in the ERP, or adjusting inventory in the supply chain system
The distinction matters because value is only realized in that third category.
Why Enterprises Are Deploying AI for Predictive Analytics
Enterprises in asset-intensive and operationally complex industries face decision volumes, data volumes, and consequence-of-error thresholds that rule-based systems and manual analysis can't keep up with. Analysis of over 10,000 global customers revealed an 11x increase in AI models put into production year-over-year, with the ratio of experimental to production-ready models dropping from 16:1 to 5:1.
Enterprise environments specifically demand:
- Consistency across high-frequency decisions - Applying the same logic to thousands of daily decisions without human variability
- Speed of signal-to-action - Reducing the time between detecting a pattern and executing a response from days to seconds
- Cross-functional data integration - Combining IoT sensor data, ERP transactional records, and CRM customer interactions into unified predictions
- Defensible, auditable outputs - Maintaining compliance in regulated sectors where decisions must be traceable and explainable
The cost of delay is measurable and steep. In Oil & Gas alone, unplanned downtime costs between $70,000 and $500,000+ per hour. Predictive maintenance cuts overall maintenance costs by 18-25% compared to preventive approaches, and up to 40% compared to reactive maintenance.

Those figures reflect a pattern that holds across industries. Organizations still running batch forecasting, static rule engines, or disconnected dashboards routinely face:
- Inventory imbalances from lagging demand signals
- Delayed failure responses that turn minor faults into costly outages
- Undetected churn signals until customers have already left
- Compliance exposure from decisions that can't be traced or explained
A model that works in a notebook but isn't deployed in production delivers none of these outcomes. The value is only realized when the system runs live, inside real workflows.
How Enterprise AI Deployment for Predictive Analytics Works
Enterprise AI deployment is an operational lifecycle, one that runs from raw data ingestion and feature engineering through model training, productionization, workflow integration, and continuous monitoring.
What the system can predict depends on three inputs:
- Data sources : sensor telemetry, transactional records, CRM data, supply chain events, and other structured or unstructured enterprise data
- Data quality : freshness, granularity, and completeness of available records
- Decision scope : the specific business question the model is built to answer
Platforms designed for this process such as Cybic's Drava platform, which unifies enterprise data, machine learning, AI reasoning, and intelligent agents manage the full lifecycle within a single governed architecture that operates across cloud, hybrid, or on-prem environments.
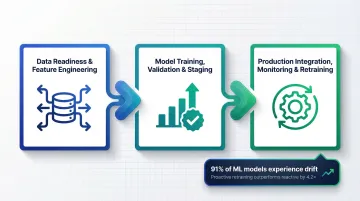
Phase 1: Data Readiness and Feature Engineering
Before any model can be deployed, enterprise data must be consolidated, cleaned, and structured into features the model can learn from. This phase covers data pipelines, data quality governance, and feature stores that ensure model inputs reflect real operational conditions rather than sanitized test data.
Feature stores are critical for eliminating training-serving skew, a common issue where differences in data handling between training and production degrade model accuracy. Atlassian's implementation of a feature store improved online feature accuracy to 99.9%, increased overall prediction accuracy by 2%, and accelerated deployment time from 1-3 months to just 1 day.
Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. IDC reports that 90% of enterprise data is unstructured, and much of it remains siloed, obsolete, or incomplete making it inaccessible for reliable ML training.
Phase 2: Model Training, Validation, and Staging
Engineering teams train models on historical enterprise data, validate them against held-out datasets, and stage them in controlled environments before production release. Validation must include business-value metrics and not just technical accuracy scores like AUC or F1.
This phase should include explicit checks for:
- Bias detection - Ensuring models don't systematically disadvantage specific groups
- Data leakage - Confirming training data doesn't contain information from the future
- Domain drift - Validating that training data distributions match production conditions
A model with high technical accuracy may not be ready for production. Technical metrics don't reflect business value, and models that perform well in notebooks often degrade rapidly when exposed to live data distributions.
Phase 3: Production Integration, Monitoring, and Retraining
Deployment means integrating model outputs directly into operational systems like ERPs, CRMs, scheduling platforms, alerting systems so that predictions trigger actions, not just appear in reports.
Research shows that 91% of machine learning models suffer from model drift over time, with up to 32% of production scoring pipelines experiencing distributional shifts within their first six months. Models left unchanged for 6+ months see error rates jump by 35% on new data.
Ongoing drift monitoring, automated retraining pipelines, and version-controlled deployment keep models performing against live data. Industry benchmarks show that proactive retraining outperforms reactive approaches by 4.2x in prediction stability.
Key Factors That Affect Enterprise AI Deployment for Predictive Analytics
Data infrastructure maturity: Consolidated, governed data environments like cloud, hybrid, or on-premises are a prerequisite. Fragmented data silos are the leading root cause of deployment failure. According to Gartner, 63% of organizations either do not have or are unsure if they have the right data management practices for AI.
MLOps capability: Organizations must treat model deployment as the beginning of the lifecycle, not the end. Continuous monitoring, automated retraining, A/B testing, and version control are operational requirements. 45% of leaders in organizations with high AI maturity keep AI initiatives in production for three years or more, compared to only 20% in low-maturity organizations.
Workflow integration depth: Predictive outputs only generate ROI when embedded into the systems where decisions are made. Models surfaced in standalone dashboards are rarely acted on with the speed or consistency needed for impact. The decision must be automated or the prediction must appear in the exact interface where the decision-maker works.
Governance, security, and regulatory constraints: In regulated industries like Oil & Gas, Healthcare, Financial Services, Public Sector deployment must meet a specific set of structural requirements:
- Role-based access controls and encrypted data handling
- Full auditability of AI-driven actions and decisions
- Strict separation between proprietary enterprise data and model training environments
- Alignment with SOC 2, HIPAA, ISO, and GDPR requirements
Cybic builds these controls into the platform architecture from day one, rather than layering them on post-deployment.
Scale and infrastructure environment: Deployment architectures must accommodate enterprise-scale inference volumes, latency requirements (real-time vs. batch), and heterogeneous infrastructure environments. Solutions that lock organizations into a single cloud ecosystem introduce brittleness that enterprise operations cannot absorb.
Common Issues and Misconceptions in Enterprise Predictive AI Deployment
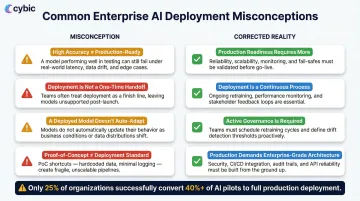
Most enterprise AI projects stall not because the models fail technically, but because the teams around them misunderstand what deployment actually requires. Four misconceptions account for the majority of production failures:
- High accuracy doesn't mean production-ready. A model with strong AUC or F1 scores measures statistical performance on test data and not operational impact or resilience to live conditions. Models that work cleanly in notebooks often degrade quickly when exposed to real data distributions.
- Deployment is not a one-time handoff. Many teams treat it as passing the model from data science to engineering, then moving on. The result: drift goes undetected, predictions become unreliable, and decisions get made on stale outputs. Deployment starts an operational lifecycle, it doesn't end a project.
- A deployed model doesn't automatically change behavior. Predictions must be embedded into the specific workflow, interface, or automated trigger where the actual decision happens. If outputs appear in a dashboard but not in the ERP system where purchasing decisions are made, nothing changes.
- Proof-of-concept performance is not a deployment standard. Organizations frequently greenlight production based on pilot results rather than actual readiness criteria, data pipeline stability, infrastructure scalability, governance controls, and change management. A Deloitte report found that just 25% of organizations have converted 40% or more of their pilots into production systems.
When Enterprise AI Deployment for Predictive Analytics May Not Be Appropriate
Predictive AI deployment isn't the right solution for every organization. In each of the following situations, a simpler approach will likely deliver better results at lower cost and risk:
- Low decision volume or stable environments : When decisions are infrequent and conditions are predictable, there isn't enough signal to justify the infrastructure. A rule-based system or statistical model delivers comparable accuracy at a fraction of the operational overhead.
- Fully mappable decision logic : If a domain expert can define the entire decision process using if-then rules, a rule-based system is usually the right choice. These "glass box" systems provide complete transparency, which is non-negotiable when regulatory compliance demands absolute explainability.
- Insufficient historical data : Statistical models require minimum data thresholds to be valid. The rule of 10 events per variable in logistic regression is a well-established benchmark fall below it and you get biased coefficients, not predictions.
- No workflow to receive model outputs : Siloed data, missing MLOps capacity, or no operational process to act on predictions means deployment produces a system that appears functional but delivers no measurable business impact.
- Deployment driven by competition, not need : Organizations that pursue predictive AI because competitors are doing so without identifying specific decision points, mapping data availability, or defining success metrics produce proof-of-concepts that never scale. The right starting point is always the decision, not the technology.
Frequently Asked Questions
What is enterprise AI deployment for predictive analytics?
Enterprise AI deployment for predictive analytics is the process of integrating trained ML models into live enterprise systems so they continuously forecast outcomes and drive operational decisions distinct from analytics dashboards (which surface insights) or experimental model development (which validates without deploying).
Why do most enterprise predictive AI projects fail to reach production?
The three most common failure modes are: absence of MLOps infrastructure to sustain models in production, failure to embed outputs into operational workflows where decisions are actually made, and insufficient governance frameworks that block deployment in regulated environments. Technical model quality is rarely the primary obstacle.
What infrastructure does an enterprise need before deploying AI for predictive analytics?
Three foundational prerequisites are required: unified and governed data infrastructure that consolidates data sources and ensures quality, MLOps tooling for continuous monitoring and automated retraining, and integration pathways into the operational systems (ERPs, CRMs, scheduling platforms) where decisions are made.
What is the difference between predictive AI and generative AI in enterprise deployments?
Predictive AI analyzes historical data to forecast specific future outcomes, churn, equipment failure, demand fluctuations typically driving operational decisions. Generative AI creates new content based on learned patterns, text, images, code typically supporting content creation, communication, and scenario generation. They are complementary tools with different operational roles.
How do enterprises ensure governance and compliance in AI-powered predictive analytics?
Effective governance requires controls embedded at the architectural level and not added after deployment. Core requirements include:
- Role-based access controls and encrypted data protection (in transit and at rest)
- Auditability of AI-driven actions and model explainability for regulated sectors
- Data governance policies ensuring proprietary enterprise data is never used to train external models
How long does it typically take to deploy a predictive analytics AI system in an enterprise?
Timeline varies based on data readiness, infrastructure complexity, and integration requirements. Organizations with mature data pipelines can move from validated model to production in weeks; those building foundational infrastructure should plan a phased multi-month program covering data consolidation, governance, and workflow integration first.


