Introduction
Most enterprises invest heavily in AI tools and models, only to watch promising pilots stall before reaching production. Research reveals a sobering reality: 88% to 95% of enterprise AI pilots fail to scale, trapped in what industry analysts call "pilot purgatory." The culprit is rarely the AI itself, it's weak foundational architecture.
The gap between proof-of-concept and production-ready systems comes down to foundational infrastructure. Organizations that successfully scale AI invest in platform architecture from day one, rather than retrofitting governance and integration after pilots proliferate.
The data backs this up. According to McKinsey, the top barriers to AI adoption are integration with existing systems (42%) and resistance to change (41%) both architectural challenges, not algorithmic ones.
Key Takeaways
- 88-95% of AI pilots fail due to poor architecture, not algorithms
- Enterprise AI platforms need layered architecture: data, AI/ML, orchestration, integration, and infrastructure
- Governance must be embedded at the architectural level and not bolted on afterward
- Infrastructure-agnostic design prevents vendor lock-in across cloud, hybrid, and on-premises environments
- Phased implementation builds time-to-value while avoiding architectural debt
What Is Enterprise AI Platform Architecture?
Enterprise AI platform architecture is the foundational blueprint governing how an organization builds, deploys, and governs AI at scale. It defines data flows, model serving, agent orchestration, and compliance controls across the full AI lifecycle and not as separate concerns, but as one integrated system. That integration is what transforms isolated AI experiments into production-grade systems that deliver measurable business value.
This differs from building a single AI application or chatbot. Enterprises must address multi-team access, legacy system integration, compliance requirements, and model versioning from day one, all at once. A well-designed architecture handles these concerns systematically. Without it, each new deployment adds to a growing pile of technical debt that becomes harder to unwind.
Platform vs. Application vs. Tool
Three commonly conflated terms require clear distinction:
- AI Tool: A single-purpose capability (e.g., a sentiment analysis API)
- AI Application: A complete solution addressing a specific use case (e.g., customer support chatbot)
- AI Platform: The shared infrastructure layer powering many applications and workflows simultaneously
An enterprise AI platform is the shared foundation that enables multiple teams to build applications without rebuilding data pipelines, governance controls, or model serving infrastructure. Organizations adopting this approach reduced costs by 32% by decommissioning legacy tools and eliminating duplicative workflows.
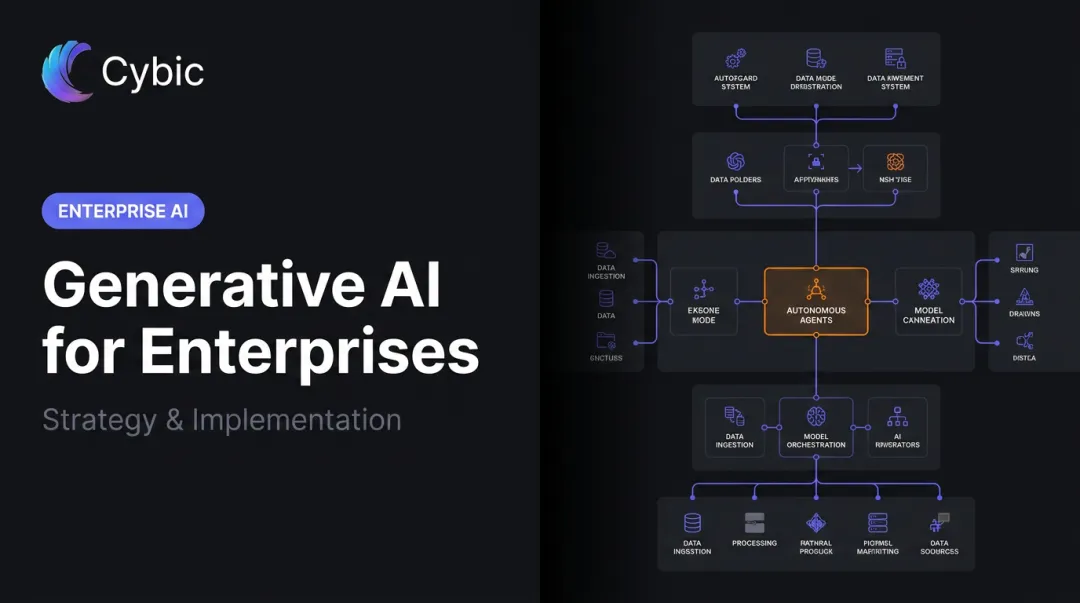
The Core Layers of a Scalable Enterprise AI Platform
Production-grade platforms converge on a layered architecture where each layer handles specific concerns, maintains clear interfaces to adjacent layers, and can evolve independently. Most enterprise implementations include five to seven distinct layers.
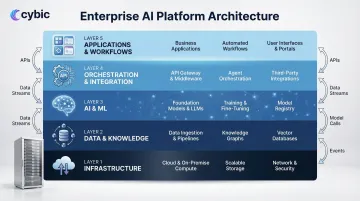
Data and Knowledge Layer
This foundational layer unifies structured, semi-structured, and unstructured data from across the enterprise into a governed, queryable store. Poor data foundations make every AI layer above them unreliable 85% of AI projects fail due to poor data quality.
Key components include:
- Centralized data lakehouse or warehouse (74% of global CIOs now have data lakehouses)
- Vector databases for semantic search and RAG applications
- Real-time streaming pipelines for operational data
- Data quality and cataloging tools
- Data governance frameworks ensuring compliance
Organizations with mature data layers report significantly lower costs. Forrester research found that over one-quarter of data and analytics teams estimate their organizations lose more than $5 million annually due to poor data quality, with 7% reporting losses exceeding $25 million.
The semantic layer bridges raw data and AI reasoning by encoding business entity definitions, relationships, and shared vocabulary. This enables models and agents to interpret data consistently across siloed systems. It's especially critical when the same customer record exists in CRM, ERP, and support systems under different identifiers.
AI and ML Layer
This centralized intelligence hub houses foundation models, domain-specific fine-tuned models, and the operational infrastructure to manage them at scale.
Core components:
- Foundation models and fine-tuned domain-specific models
- MLOps pipelines (training, versioning, deployment, retraining)
- Model registry tracking versions, performance metrics, and lineage
- Model gateway routing inference requests across internal and external models based on cost, latency, and compliance rules
Organizations that successfully industrialize ML shorten production timeframes by 8-10x and reduce development resources by up to 40%. IDC predicted that 60% of enterprises would implement MLOps by 2024, reflecting the maturation of this discipline.
Effective integration layers include standardized API endpoints, event-driven messaging for real-time synchronization, pre-built connectors for common enterprise applications, and custom development paths for proprietary systems. The goal is interoperability without rearchitecting what already works.
Infrastructure Layer
The compute, storage, and networking foundation supporting enterprise AI includes:
- GPU-capable infrastructure for model training and inference
- Elastic autoscaling responding to variable workloads
- Support for cloud, hybrid, and on-premises deployments
- Infrastructure-as-code for reproducibility and auditability
Compute costs vary significantly by hardware choice. On Google Cloud, for instance, an NVIDIA A100 GPU costs $4.40 per hour versus an NVIDIA T4 at $0.35 per hour , a 12x difference that compounds quickly at production scale. Getting the infrastructure layer right before deployment is far cheaper than retrofitting it afterward.
Design Principles for Building AI Systems That Actually Scale
Modularity and Composability
Each architectural component should have clearly defined interfaces and be replaceable without cascading failures. Monolithic platforms built around a single vendor's stack become rigid and difficult to evolve.
The risk is substantial: 94% of IT leaders fear vendor lock-in, and migration costs average $315,000 per project. 57% of IT leaders spent more than $1 million on platform migrations in the last year alone.
Mitigation strategies:
| Strategy | Implementation | Key Benefit |
|---|---|---|
| AI Gateways | Intercept API calls between applications and AI providers | Enables model swapping without rewriting application code |
| Open Standards | Adopt ONNX, Model Context Protocol, OpenTelemetry | Ensures interoperability and prevents proprietary format lock-in |
| Containerization | Use Docker and Kubernetes for orchestration | Reduces reliance on vendor environments and enables multi-cloud |

Infrastructure-Agnostic Design
Enterprise AI systems must operate across cloud providers (AWS, Azure, GCP), hybrid environments, and on-premises infrastructure driven by data residency requirements, latency constraints, and regulatory mandates.
Abstracting infrastructure concerns behind standardized APIs and containerized workloads is what makes this possible. Cybic structures its platform builds around this requirement directly, architecting solutions that run across cloud, hybrid, and on-premises environments from the start rather than retrofitting portability later.
Scalability Patterns
Production AI workloads require distinct provisioning strategies:
- Real-time inference: Persistent instances for low-latency requirements
- Batch processing: Offline processing of large datasets without persistent endpoints
- Serverless inference: Pay-per-millisecond for intermittent traffic
AWS SageMaker documentation outlines these trade-offs, noting that serverless inference allows organizations to pay only for compute capacity used per millisecond, while real-time inference maintains persistent instances for consistent low latency.
Additional patterns include:
- Horizontal scaling for inference workloads
- Separation of training and serving infrastructure
- Asynchronous processing for non-latency-sensitive tasks
- Auto-scaling policies tied to actual demand rather than static provisioning
Observability and Feedback Loops
Production AI systems degrade silently when data distribution shifts or model performance drifts. Research indicates that 91% of machine learning models suffer from model drift.
Yet catching drift early remains a persistent gap. An Arize AI survey found that 26.2% of data scientists and ML engineers say it takes their team a week or more to detect and fix a production model issue, while 50.8% want deeper capabilities to monitor and root-cause drift.
Architecture must include monitoring for:
- Data quality metrics and distribution shifts
- Model accuracy and performance degradation
- Agent behavior and decision patterns
- System health and resource utilization
- Automated alerting and closed-loop retraining pipelines
Design for Operational Reality
Architecture decisions must account for how the system will actually be operated by real teams, within existing compliance environments, integrated with legacy tools. This means involving IT operations and security in architectural decisions from day one, not retrofitting controls after the platform is built.
Cybic's engineers architect, build, and integrate directly handling the translation between business requirements and working systems themselves, rather than passing specifications between layers of consultants. The result is less drift between what was designed and what gets deployed.
Governance, Security, and Compliance by Design
Governance cannot be a bolt-on. When added after architecture decisions are made, it creates blind spots like ungoverned data access, untracked model decisions, and compliance violations that are expensive to remediate.
Cybic embeds governance at the architectural level from day one. The Drava platform builds access controls, auditability, and compliance alignment directly into the architecture and not layered on afterward which is what separates platforms that scale cleanly from those requiring expensive remediation later.
Role-Based Access Control and Identity Management
AI platform RBAC operates at granular, dynamic levels:
- Which data sets can be accessed by which users and systems
- Which models can be invoked by which agents
- Which workflows require human-in-the-loop approval
- Dynamic permission adjustment based on context and risk
This exceeds traditional IT access management in complexity, especially for agentic systems operating at machine speed where access decisions must be made in milliseconds.
Auditability and Traceability
Access control determines who can act. Auditability determines what can be proven afterward and for regulated industries, that distinction is the difference between a defensible system and a liability.
Every AI-driven action must be logged with enough context to reconstruct what happened, why, and what data was used. The EU AI Act Article 12 mandates that high-risk AI systems technically allow automatic recording of events over the system's lifetime to ensure traceability.
Data Governance Specific to AI
Auditability is only as strong as the data underneath it. AI-specific data governance addresses four areas that general IT governance typically misses:
- Lineage tracking : traces data provenance through every transformation so model outputs can be explained and defended
- Training data protection : prevents proprietary enterprise data from being used to train external or shared models
- Residency enforcement : keeps data within required geographic boundaries for cross-border regulatory compliance
- Quality standards : validates data consistency before it reaches models, protecting output integrity at the source

Regulatory Frameworks Shaping Architecture
These governance requirements don't exist in isolation, they map directly to regulatory frameworks that dictate architecture decisions for enterprise AI deployments.
| Framework | Primary Scope | Key Architectural Requirement | Penalty / Impact |
|---|---|---|---|
| EU AI Act | High-risk AI systems in the EU | Human oversight interfaces (Article 14); automatic event logging (Article 12) | Fines up to €35M or 7% of global annual turnover |
| HIPAA | Healthcare data (US) | Administrative, physical, and technical safeguards for ePHI confidentiality, integrity, and availability | Civil and criminal penalties; mandatory breach notification |
| SOC 2 | Enterprise SaaS and data platforms | Controls across security, availability, processing integrity, confidentiality, and privacy | Audit failure blocks enterprise sales; reputational exposure |
| NIST AI RMF | Voluntary US AI risk management | Four-function structure: GOVERN, MAP, MEASURE, MANAGE | Voluntary but increasingly referenced in procurement requirements |
Common Architecture Anti-Patterns That Derail Enterprise AI
Pilot Proliferation
Enterprises deploy dozens of isolated AI pilots with separate infrastructure, data pipelines, and governance controls resulting in fragmentation, duplicated effort, and no shared foundation for scaling.
Teams commonly spend 2 to 3 times their license costs on integration work, custom connectors, and maintenance. Consolidating onto a unified MLOps platform yields real results: organizations report a 40% reduction in their total tool stack after consolidating, removing an average of 2.43 tools per customer.
The alternative: A shared platform layer that individual applications draw from, providing centralized data access, model serving, governance controls, and operational monitoring.
Model-First, Data-Later
Teams invest heavily in model selection and prompt engineering before solving foundational data quality, access, and integration problems. This leads to high-quality models producing low-quality outputs because the data feeding them is inconsistent or ungoverned.
Gartner defines "AI-ready data" as data that is clean, accessible, correctly permissioned, and organized to allow models to operate reliably in production.
Organizations that successfully scale AI run data readiness assessments before launching pilots and not after the model is already chosen.
Cloud-Only Assumption
Architectures designed purely for public cloud fail when enterprise data residency, latency, or air-gap requirements force workloads on-premises or into hybrid environments. The architecture must account for cloud, hybrid, and on-premises environments from day one.
Discovering these constraints after the fact triggers expensive rework. Two failure modes are common:
- Data residency violations: Sensitive data cannot legally or contractually move to public cloud, requiring full re-architecture of data pipelines.
- Edge computing gaps: Local processing requirements at plant floors or remote sites are not accommodated, forcing last-minute workarounds that undermine reliability.
Designing for infrastructure flexibility from the start eliminates both failure modes before they become production problems.
Implementing Enterprise AI Architecture: A Phased Approach
Phase 1: Foundation
Objective: Prove architectural soundness, not maximize business value yet.
Key activities:
- Establish the data layer with governance policies and access controls
- Deploy a model gateway and basic MLOps pipeline
- Set up security controls and audit logging
- Deliver a limited but production-ready use case (e.g., internal document search via RAG)
This phase validates that the architecture can operate reliably in production before expanding scope. Gartner surveys indicate that, on average, it takes 8 months to go from an AI prototype to production making architectural validation critical before scaling investment.
Phase 2: Expansion
Objective: Generate cross-functional value while building platform capabilities.
Key activities:
- Introduce workflow orchestration and agent capabilities
- Modularize application integrations into reusable API services
- Expand data coverage across business domains
- Build monitoring and observability infrastructure
- Deploy additional use cases leveraging the shared platform
By the end of this phase, the shared platform is actively generating ROI across multiple business functions and not sequentially, but in parallel.
Phase 3: Scale and Optimize
Objective: Achieve enterprise-wide adoption and operational excellence.
Key activities:
- Deploy multi-agent workflows across business domains
- Implement enterprise-wide semantic understanding
- Optimize infrastructure costs through right-sizing and efficiency improvements
- Automate retraining pipelines
- Build toward a digital twin of key business processes
The MIT CISR Enterprise AI Maturity Model notes that financial performance improves markedly as enterprises move from Stage 2 (building pilots) to Stage 3 (developing scaled AI ways of working), which involves building a scalable enterprise architecture that allows for scaling and reusing models.
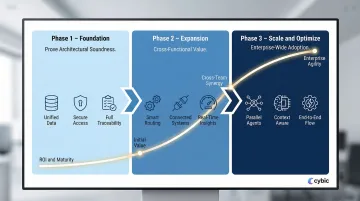
Organizations with well-designed foundational architecture in Phase 1 reach this stage faster than those forced to refactor mid-scale. That gap widens when design and execution are handled by the same engineering team. Cybic's engineering-led delivery model is structured exactly this way experienced engineers architect, build, and integrate directly, keeping architectural intent intact from first deployment through enterprise scale.
Frequently Asked Questions
What are the 4 types of Enterprise Architecture?
The four types are Business Architecture, Application Architecture, Information/Data Architecture, and Technology Architecture. Enterprise AI platform architecture spans all four domains, requiring alignment across business processes, application systems, data flows, and technology infrastructure to function effectively.
What is the 10-20-70 rule for AI?
Originating from Boston Consulting Group, the 10-20-70 rule allocates 10% of AI project effort to algorithms, 20% to technology and infrastructure, and 70% to data preparation and organizational change. That 70% figure is why data architecture and change management determine whether enterprise AI succeeds or stalls.
What is the 30% rule for AI?
The 30% rule holds that AI should handle roughly 70% of repetitive operational tasks, while humans retain 30% for oversight, strategy, and judgment. For enterprise architects, this means MLOps and monitoring layers must be designed with human accountability checkpoints to manage risks like bias and model drift.
What are the 7 C's of AI?
In the enterprise compliance context, the 7 C's are: Competence, Confidentiality, Consent, Confirmation, Conflicts, Candor, and Compliance. Each maps to a concrete AI design requirement from explainability and human-AI collaboration to governance controls that keep deployments legally and ethically sound.
What is the difference between an AI platform and an AI architecture?
AI architecture is the blueprint, the design decisions, layer structure, and integration patterns. An AI platform is the implemented infrastructure that instantiates that architecture. When the architecture is sound, the platform can grow with the organization. When it isn't, the platform eventually has to be rebuilt from scratch.