
Introduction
Most enterprises sit on decades of valuable data but can't act on it fast enough. The infrastructure holding that data was built for a different era. Data volumes are exploding, AI-driven decisions are now a competitive necessity, yet legacy data warehouses still batch-process overnight and break under real-time analytical workloads.
Data teams dedicate 53% of engineering time to pipeline maintenance, costing organizations $2.2 million annually just keeping systems running. Legacy pipelines break 30-47% more often than modern alternatives, resulting in 60 hours of downtime per month. Meanwhile, business leaders demand real-time insights to stay competitive.
This blog explains what data warehouse modernization actually means, why the cost of inaction is measurable, and what best practices look like for organizations that want to build a data foundation that supports AI-ready operations not just lift infrastructure to the cloud and call it done.
Key Takeaways
- Legacy EDWs slow analytics, inflate costs, and block AI adoption
- Modernization covers architecture, governance, and data readiness, cloud migration is just one piece
- The 5 R's framework (Rehost, Replatform, Refactor, Re-architect, Replace) provides a decision lens for choosing the right path
- Hybrid approaches lower risk: keep stable workflows intact while redesigning high-impact areas first
- Governance, real-time capability, and AI readiness need to be designed in from the start and not bolted on later
What Is Data Warehouse Modernization?
Data warehouse modernization is the process of evolving an organization's data warehouse infrastructure to meet current demands for speed, scale, governance, and advanced analytics. This means rethinking architecture, tooling, data models, and integration patterns and not just migrating to the cloud. True modernization addresses how data is structured, governed, and consumed.
Understanding Enterprise Data Warehouses
An Enterprise Data Warehouse (EDW) is a centralized repository that integrates data from multiple operational systems like CRM, ERP, IoT sensors, financial systems through ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) pipelines. It stores this data in a structured, query-optimized format and serves it to BI tools, dashboards, and analytics platforms.
EDWs have four defining characteristics:
- Organized around key business domains like customers, products, sales rather than individual applications
- Consolidates data from across the business into a single, consistent format
- Retains historical records to support trend analysis and long-term reporting
- Keeps loaded data stable; records are not frequently updated or deleted mid-cycle
These characteristics make EDWs reliable analytical foundations but also slow to adapt when data volumes, sources, or business requirements change rapidly. That's where the modernization decision begins.
The 5 R's of Data Warehouse Modernization
The 5 R's framework provides a practical decision lens for modernization:
- Rehost: Move systems as-is to cloud infrastructure with minimal changes
- Replatform: Migrate with minor optimizations (for example, switching to managed database services)
- Refactor: Restructure code and pipelines without changing core architecture
- Re-architect: Redesign data models and architecture for modern workloads
- Replace: Retire legacy systems entirely in favor of modern platforms
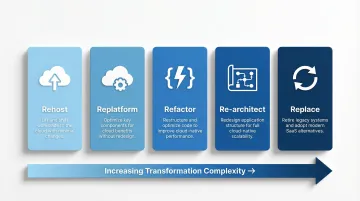
Most enterprises apply a mix across different workloads. The right choice depends on business criticality, accumulated technical debt, and long-term strategic value.
Why Legacy EDWs Are Holding Enterprises Back
Legacy data warehouses don't just slow things down, they actively prevent organizations from making timely decisions, supporting AI initiatives, and controlling infrastructure costs.
Operational Pain Points
Legacy EDWs suffer from fundamental architectural limitations:
- Batch processing delays: Overnight ETL jobs mean insights arrive hours or days late, when business conditions have already changed
- Rigid schemas: Adding new data sources requires months-long projects involving schema redesign, testing, and validation
- Fixed capacity: Expensive on-premise hardware either over-provisions (wasting money) or buckles under peak analytical loads
The maintenance burden is staggering. Data teams spend 53% of their engineering time on pipeline upkeep, with legacy and DIY pipelines breaking 30-47% more often than modern alternatives.
The AI Bottleneck
Traditional data warehouses offer no support for unstructured data images, text, IoT feeds and are optimized for historical reporting, not AI workloads. Most offer no native support for Python or R, the languages data scientists actually use.
The result: data scientists spend more time building workaround pipelines to get clean, accessible data than building models. AI initiatives stall before they start.
Escalating Costs
Legacy licensing charges for capacity whether you use it or not. As data volumes grow, costs scale linearly with no corresponding performance gains. Even early cloud migrations haven't solved this:
- Cloud migration inefficiencies cost companies 14% more than planned each year
- 65% of enterprises exceed original migration budgets by at least 20%
- Root cause: poor architectural planning, not cloud platform limitations
Key Benefits of Modernizing Your Enterprise Data Warehouse
Performance and Agility
Modern cloud-native data warehouses deliver dramatic performance improvements through columnar storage, separated compute and storage, and elastic scaling. Organizations moving from on-premise systems to Snowflake reduced query resolution time from 7 seconds to 2 milliseconds, a 10X improvement in time to insights.
AT&T reported that 90% of data requests now return in less than one second after migrating to Snowflake. Pfizer achieved 4X faster data processing with Snowpark. Gains like these reshape decision-making speed across the entire organization.

Provisioning time differences are equally dramatic. On-premise deployments require physical procurement, delivery, installation, and configuration taking weeks or months. Cloud deployment completes in hours or days, with resources added or removed in minutes.
Cost Efficiency
Pay-as-you-go cloud pricing eliminates idle compute costs. BigQuery customers save up to 54% in total cost of ownership compared to alternative cloud EDW offerings. Pfizer achieved 57% lower TCO with a 28% reduction in overall database costs after migrating to Snowflake.
Even cloud-to-cloud migrations deliver real savings when architectural optimization is part of the strategy. Organizations that simply lift-and-shift without redesigning for cloud-native patterns forfeit 30–50% of the cost savings available through proper re-architecture.
Data Quality and Consistency
The ETL/ELT modernization process forces systematic cleansing and standardization of data from disparate sources. This eliminates the "whose numbers are right?" debates between departments. A modernized EDW becomes a verifiable single source of truth across the enterprise.
Foundation for Advanced Analytics and AI
Clean, governed, and well-modeled data is the prerequisite for reliable machine learning, predictive analytics, and generative AI applications. Organizations cannot build trustworthy AI on fragmented or dirty data without it, AI initiatives stall at the proof-of-concept stage.
The data confirms how widespread the problem is:
- Only 7% of enterprises say their data is completely ready for AI adoption
- 56% cite siloed data and integration challenges as the top blocker
- 41% flag data quality and bias issues as a primary obstacle
Warehouse modernization directly removes each of these barriers.
Governance and Compliance
Modern platforms offer fine-grained access controls, data lineage tracking, audit trails, and encryption at rest and in transit. This is especially critical for regulated industries like healthcare, financial services, oil and gas, public sector where data provenance (where data originated and how it's been handled) and auditability are non-negotiable.
The consequences of inadequate governance are severe. Citigroup was assessed a $400 million penalty in 2020 for failures in data governance programs, with an additional $60.6 million fine in 2024 for insufficient progress in remediating data quality issues.
Modern Approaches to Data Warehouse Modernization
Cloud Migration
Moving from on-premise EDWs to cloud-native platforms (AWS Redshift, Google BigQuery, Azure Synapse, Snowflake) provides elastic compute, managed infrastructure, and faster deployment cycles. Organizations can choose between full cloud migration and hybrid cloud approaches that keep sensitive workloads on-premise while moving analytical workloads to the cloud.
The cloud's key advantages extend beyond infrastructure cost savings. Teams can spin up development environments in minutes, scale compute capacity during peak periods, and pay only for what they use.
Data Lakehouse Architecture
The Data Lakehouse merges two previously separate worlds: the raw storage flexibility of a data lake with the governance and query performance of a traditional warehouse. In practice, this means ACID transactions, schema enforcement, and fast analytical queries like applied to structured, semi-structured, and unstructured data in one unified platform.
Databricks defines the lakehouse as using Delta Lake for optimized storage and Unity Catalog for fine-grained governance. The business case is compelling: lakehouse customers realized an average ROI of 482% over three years, with a 4.1-month payback period and $2.6M in annual infrastructure savings.
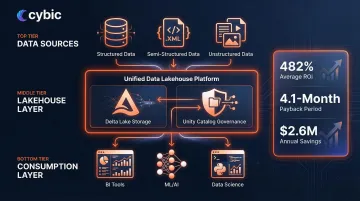
This architecture fits organizations that need to support traditional BI workloads alongside advanced analytics like machine learning on unstructured data, real-time streaming, and data science exploration without maintaining separate systems for each.
Hybrid Migration Strategy
For most enterprises, a hybrid migration strategy is the most practical path: preserve 70-80% of existing workflows through lift-and-shift, then target 20-30% of high-impact or inefficient areas for meaningful redesign.
In practice, this might look like:
- Migrating core reporting pipelines as-is to reduce validation complexity
- Redesigning ingestion frequency for critical operational dashboards
- Consolidating redundant pipelines that accumulated over years of organic growth
- Re-architecting data models only for high-value analytical workloads
Trying to redesign everything at once makes validation exponentially harder and compounds project risk. The hybrid approach lets teams build institutional knowledge, demonstrate ROI early, and refine the process before committing the full data estate.
ETL/ELT Modernization and Pipeline Automation
Shifting from fragile, manually written batch ETL processes to modern ELT patterns like load first, transform in-platform and automated pipeline orchestration reduces maintenance burden and accelerates migration timelines considerably.
Recent tooling has changed what's achievable in compressed timelines:
- AWS DMS with generative AI converts up to 90% of schema objects from commercial databases to PostgreSQL automatically
- Hexaware achieved a 90% reduction in delivery time and 80% reduction in migration risks using AWS DMS and Schema Conversion Tool
- Databricks GenAI Accelerators cut migration timelines by up to 70% and reduce manual effort by more than 50%

Real-Time Streaming Architectures
Integrating technologies like Apache Kafka or cloud-native streaming services allows data to be ingested and available for analysis within seconds rather than overnight. 89% of IT leaders see Data Streaming Platforms as critical to achieving data-related goals, with 90% increasing DSP investments.
Real-time streaming delivers measurable business outcomes. EVO Banco reduced weekly fraud losses by 99% and blocked 500 fraudulent transactions daily using Confluent Cloud. Vocus Group reduced call record mediation costs by 94% and improved fraud detection rule implementation speed by 80% using AWS serverless services.
Not every use case demands real-time. Fraud detection, IoT monitoring, and supply chain visibility benefit from second-level latency. Monthly financial reporting and historical trend analysis can tolerate batch processing.
Approach comparison at a glance:
| Approach | Best For | Key Trade-off |
|---|---|---|
| Cloud Migration | Infrastructure cost reduction, faster dev cycles | Requires re-validation of existing workloads |
| Data Lakehouse | Mixed BI + ML/AI workloads, diverse data types | Higher architectural complexity upfront |
| Hybrid Migration | Enterprises with large, stable data estates | Requires careful scope management |
| ELT Modernization | Teams with brittle legacy pipelines | Tool selection adds evaluation overhead |
| Real-Time Streaming | Fraud detection, IoT, supply chain visibility | Unnecessary overhead for batch-tolerant use cases |
Best Practices for a Successful EDW Modernization
Start with a Pre-Migration Audit
Before any platform decision or migration begins, conduct a thorough inventory of existing data assets, active vs. unused pipelines, data quality issues, and redundant systems. Identify what is genuinely being used for business decisions vs. what is legacy accumulation.
This "clean the house" step prevents carrying forward technical debt into the new environment. Organizations often discover that 30-40% of existing pipelines are no longer actively used or can be consolidated.
Align Business Stakeholders Before the First Line of Code Moves
Data warehouse modernization is not an IT project, it's a business capability project. Engage business users, data consumers, and department leads early to understand what analytical capabilities they need, which data domains are highest priority, and what "success" looks like in business terms.
Early alignment prevents scope creep and post-migration disappointment. When business stakeholders define success criteria upfront, technical teams can design solutions that deliver measurable value rather than just technical improvements.
Embed Governance by Design, Not as an Afterthought
Define data ownership, access controls, data classification policies, and lineage requirements before migration begins, then build them directly into the new architecture. Retrofitting governance onto a running system is far more expensive and disruptive than engineering it in from the start.
Organizations that establish data ownership, quality standards, and compliance frameworks before infrastructure migration typically see 25-40% improvements in data management metrics within the first year. Those that retrofit governance struggle for years.
This is especially critical for regulated industries, where governance requirements must be architectural requirements and not compliance checkboxes applied at the end:
- Healthcare organizations must meet HIPAA data privacy and security requirements
- Financial services firms must comply with SOX reporting and audit controls
- Public sector agencies face strict government data handling and residency standards
- Manufacturing and energy clients often carry additional industry-specific regulatory obligations
Modernize Iteratively, Not All at Once
Begin with a specific business domain or use case like sales analytics, supply chain reporting, customer analytics that demonstrate value quickly, then expand scope.
This approach allows teams to build institutional knowledge, refine the migration process, and show tangible ROI to leadership before committing the entire data estate. Early wins also build organizational trust which matters when asking departments to change how they access and use data.
Plan for AI Readiness from the Outset
If the long-term goal is to power AI, machine learning, or intelligent automation from this data foundation, the data model, schema design, data quality standards, and governance framework need to account for that from day one.
Concretely, this means:
- Structuring data for ML feature engineering from the start, not as a later retrofit
- Maintaining trackable lineage for model auditability and regulatory accountability
- Supporting both structured and unstructured data types on the same platform
- Building access controls that govern AI model inputs, not just human queries

By 2028, 50% of organizations will implement zero-trust data governance due to the proliferation of unverified AI-generated data. Organizations that build this into their modernization architecture now avoid an expensive governance retrofit later.
Cybic's data modernization engagements are structured around this principle building the infrastructure layer so that AI models, predictive analytics, and automation tools can be deployed without rearchitecting the foundation.
AI, Automation, and Governance: The Future-Ready Data Warehouse
The modern data warehouse is no longer just an analytics repository, it's the intelligence backbone for enterprise AI. As organizations deploy LLMs, predictive models, and intelligent automation, the quality, structure, and governance of underlying data directly determine AI reliability and trustworthiness.
A modernized EDW with clean lineage, enforced schemas, and access controls becomes the foundation on which AI systems can be safely deployed at scale. Only 7% of enterprises have data completely ready for AI, with 73% struggling with AI data preparation due to siloed data and quality issues.
AI Accelerating Modernization Itself
Generative AI tools are accelerating the modernization process. AWS Database Migration Service uses generative AI to offer recommendations for converting previously incompatible database objects. This reduces the manual burden on engineering teams and compresses migration timelines.
Cybic's Drava platform connects modernized data foundations to AI reasoning and intelligent agents, translating governed data into automated business workflows from supply chain coordination to clinical and industrial operations.
The Governance Imperative
Governance can't be retrofitted after deployment. Organizations need these controls built into the architecture from the start:
- Role-based access controls limiting data exposure by user and function
- Encryption of data at rest and in transit
- Full auditability of data access and transformation history
- Strict policies preventing proprietary data from training shared AI models
Cybic embeds these controls at the architectural level across security, access management, auditability, and regulatory alignment so AI systems operate within defined business rules from day one, not as an afterthought.
Frequently Asked Questions
What is data modernization and what are the 5 R's of modernization?
Data modernization is the process of updating data infrastructure, architecture, and practices to meet current analytical and AI demands. The 5 R's that is Rehost, Replatform, Refactor, Re-architect, Replace provide a decision framework for choosing the right modernization path for each workload based on business value and technical complexity.
What is an EDW and how does it work?
An EDW is a centralized repository that pulls data from multiple enterprise systems via ETL/ELT pipelines, structures it for analytical queries (OLAP), and serves it to BI tools and reporting platforms. Unlike transactional databases (OLTP), it's optimized for analysis rather than operational speed.
What is the EDW data model?
The EDW data model defines how data is structured and organized within the warehouse. Common patterns include the star schema (a central fact table surrounded by dimension tables) and snowflake schema (normalized dimension tables). The choice affects query performance, flexibility, and ease of use for analysts.
Are data warehouses updated in real time?
Traditional data warehouses relied on nightly batch processing, but modern EDWs increasingly incorporate real-time or near-real-time ingestion via streaming technologies like Apache Kafka or cloud-native streaming services, enabling data availability within seconds. Use cases like fraud detection or live operations dashboards typically drive the shift to streaming; batch processing remains sufficient for overnight reporting workflows.
What is the difference between EDW and CDP?
An EDW is a broad enterprise data repository integrating data from all business systems for analytics and reporting across the organization. A Customer Data Platform (CDP) is purpose-built to unify customer data specifically for marketing and personalization use cases. A CDP is often one of many sources feeding into an EDW.
What is a data-driven enterprise and how does EDW modernization support data-driven decision making?
A data-driven enterprise runs decisions on reliable, timely data rather than intuition. EDW modernization supports this by establishing a governed, unified data foundation that accelerates time-to-insight, puts analytics directly in the hands of business users, and supplies the clean data AI models require to function reliably.


