
Introduction
Enterprises are generating unprecedented volumes of data projected to reach 181 zettabytes by 2025yet most still struggle to convert that data into timely, trustworthy decisions. The core problem isn't volume; it's infrastructure. Legacy data systems were never designed for today's analytical and AI demands, leaving organizations trapped in a costly paradox: drowning in data while starving for insight. The financial impact is severe: poor data quality costs the average enterprise $12.9 million annually, a drain that compounds when bad data feeds machine learning models and LLMs.
A well-architected Enterprise Data Warehouse (EDW) is the strategic foundation that determines whether an organization can turn data into decisions across the business. This guide covers five critical areas:
- What an EDW is and how it differs from transactional databases
- How modern cloud-native architecture works
- Implementation best practices that separate successful deployments from expensive failures
- Governance requirements that must be embedded at the architectural level
- Platform selection criteria that balance performance, cost, and vendor lock-in risk
Key Takeaways
- An EDW is a centralized, governed repository that integrates structured data from across the organization into a single source of truth for BI, analytics, and AI
- Modern EDW architecture has shifted from legacy ETL to cloud-native ELT, separating storage from compute for independent scalability
- Implementation success hinges on five practices: business alignment, data quality at the staging layer, the right integration strategy, dimensional modeling, and metadata management
- Embed governance and security at the architectural level and not bolted on after deployment
- The EDW is the prerequisite infrastructure for enterprise AI; clean, governed data is what makes ML models, copilots, and automation trustworthy
What Is an Enterprise Data Warehouse (and How Does It Work)?
An Enterprise Data Warehouse (EDW) is a centralized, analytics-optimized repository that consolidates structured data from multiple source systems like CRM platforms, ERP systems, operational databases, cloud SaaS applications across an entire organization.
Unlike transactional databases (OLTP systems built for fast writes and operational processing), an EDW is purpose-built for analytical queries, historical trend analysis, and business intelligence. It also differs from data lakes, which store raw, unstructured data without transformation. The EDW's core purpose is to produce a consistent, governed single source of truth for analysis.
Key Characteristics That Define an EDW
Four foundational characteristics distinguish an EDW from other data systems, originally defined by Bill Inmon, the recognized "Father of Data Warehousing":
- Subject-oriented : Organized around business domains like Customer, Sales, or Product rather than by application or transaction type
- Integrated : Resolves naming inconsistencies, measurement differences, and format conflicts across source systems into a unified schema
- Time-variant : Stores historical snapshots enabling trend analysis, with every data point accurate as of a specific moment in time
- Non-volatile : Data is written once and not overwritten, forming an auditable, static historical record

EDW vs. Data Mart
A data mart serves a single department's analytical needs. For example, a Marketing data mart containing only campaign and customer data. An EDW spans the entire enterprise and feeds multiple downstream data marts. The EDW is the central reservoir; data marts are the specialized pipelines drawing from it.
Enterprise Data Warehouse Architecture: From Legacy ETL to Modern ELT
The historical ETL (Extract, Transform, Load) model defined data warehousing for decades. Data was extracted from source systems and transformed on a dedicated server before loading , a sequence that created real constraints:
- Pipeline delays from blocking transformation steps
- Expensive dedicated transformation hardware
- Raw data discarded after processing, limiting reuse
- Schema changes that were slow and costly to implement
These bottlenecks are exactly what modern cloud-native EDW architecture was designed to solve.
The shift to cloud-native ELT (Extract, Load, Transform) inverts this process: raw data is loaded directly into the cloud warehouse first, and transformation happens using the warehouse's own compute engine. This approach delivers three key advantages:
- Data becomes available faster transformation no longer blocks loading
- Raw data is preserved, enabling multiple transformation passes for different use cases without re-extracting from source systems
- The separate transformation server is eliminated, replaced by elastic cloud compute
Modern EDW Workflow Layers
1. Ingestion Layer:
- Batch syncs for high-volume historical loads
- Change Data Capture (CDC) for near-real-time database replication, streaming only inserts, updates, and deletes
- Event streaming via Apache Kafka for operational data requiring seconds-level latency
2. Loading and Staging:
Raw data lands in a staging zone preserving source fidelity, with append-only patterns and load metadata captured for auditability.
3. Transformation and Modeling:
Data is shaped using dimensional modeling techniques inside the warehouse compute engine, producing query-ready analytical tables.
Star Schema vs. Snowflake Schema
Two primary data modeling schemas are used in the transformation layer:
| Feature | Star Schema | Snowflake Schema |
|---|---|---|
| Structure | Central fact table linked directly to denormalized dimension tables | Dimension tables normalized into sub-tables |
| Query Performance | Faster; requires fewer JOINs | Slower; requires complex, multi-hop JOINs |
| Storage Efficiency | Lower; high data redundancy | Higher; minimal data redundancy |
| Maintenance | Harder to update due to duplicated data | Easier to update; changes made in one place |
| Best For | Fast BI queries, executive dashboards | Storage-constrained environments, complex hierarchies |
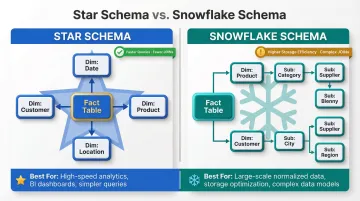
The Kimball Group recommends avoiding snowflake schemas because they are difficult for business users to navigate and negatively impact query performance. Modern cloud EDWs with columnar storage have narrowed this performance gap, though the usability argument remains valid.
Compute-Storage Separation Architecture
Modern cloud EDW platforms (Snowflake, BigQuery, Redshift, Azure Synapse) use architectures that separate compute from storage, enabling:
- Storage and compute scale independently based on workload demands
- Heavy ETL jobs run without degrading executive dashboard performance
- Serverless options reduce manual infrastructure management overhead
- Costs align to actual query activity, no charges for idle capacity
Enterprise Data Warehouse Implementation Best Practices
Enterprise Data Warehouse Implementation Best Practices
Five practices separate EDW implementations that deliver measurable value from those that stall in infrastructure debates. Each one addresses a different failure point from scope definition to how data surfaces in AI systems.
Start with Business Outcomes, Not Technology
Gartner predicts that by 2027, 80% of data and analytics governance initiatives will fail due to a lack of connection to prioritized business outcomes. Most EDW implementations fail not because of bad technology choices but because they are scoped as IT projects measured by uptime rather than business impact.
Best practice: Define specific, measurable business outcomes before selecting a platform. For example, reducing a reporting cycle from 5 days to 2, improving demand forecast accuracy by 15%, or enabling real-time fraud detection. The EDW's architecture should be reverse-engineered from these targets.
Build Data Quality Into the Staging Layer
The staging layer, the zone where raw data lands before transformation is the critical control point for data quality. Best practices at this layer include:
- Append-only loading with timestamps to preserve audit trails
- Lightweight validations: null checks, type mismatches, row count reconciliation
- Partitioning by date or source for efficient query pruning
- Storing load metadata (batch IDs, file names, source system identifiers)
Catching quality issues here prevents bad data from propagating into production analytical tables, where it becomes exponentially more expensive to remediate.
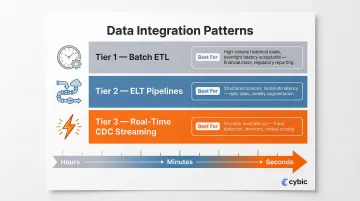
Match Your Integration Strategy to Business Velocity Requirements
Not all data needs to move at the same speed and choosing the wrong integration pattern is a common source of architectural debt. Use this framework:
Batch ETL:
- Best for compliance-heavy or large-volume historical loads where overnight latency is acceptable like monthly financial close, regulatory reporting
ELT Pipelines:
- Best for scalable transformation of structured sources with moderate latency requirements like daily sales reporting, weekly customer segmentation
Real-Time Streaming via CDC:
- Best for operational decisions requiring seconds-level latency like inventory management, fraud detection, clinical risk scoring
Adopt a hybrid integration posture that matches pattern to use case rather than forcing a single approach across all data sources.
Apply Dimensional Modeling for Analytical Performance
How data is physically organized inside the EDW directly determines query performance and analyst productivity. Use proven dimensional modeling (Kimball methodology) to structure data into:
- Fact tables measurable events: transactions, orders, patient encounters
- Dimension tables the contextual who/what/when: customer, product, date, location
Well-designed models allow BI tools to answer complex cross-functional queries in seconds without requiring data scientists to manually join raw tables.
Treat Metadata as a First-Class Asset
Metadata management has evolved beyond technical documentation. Modern EDWs need a metadata layer that captures three distinct categories:
- Column definitions, data types, and field-level lineage (technical)
- What each field means to the finance team versus the ops team (business context)
- Freshness, update frequency, and data ownership (operational)
In practice, metadata catalogs must also be machine-readable so AI tools like LLMs, RAG systems, and data copilots can query and reason over enterprise data directly, without requiring a human intermediary to bridge the gap.
Governance and Security: The Non-Negotiable Architectural Foundation
Governance cannot be a post-deployment overlay. When access controls, audit trails, and data quality rules are added after architecture is defined, they are expensive to enforce and easy to circumvent. The principle of governance-by-design embeds policies for data access, lineage tracking, and compliance directly into the warehouse architecture from day one.
Treating governance as an architectural requirement and not a post-launch feature is what separates compliant, auditable warehouses from ones that fail regulatory scrutiny under pressure.
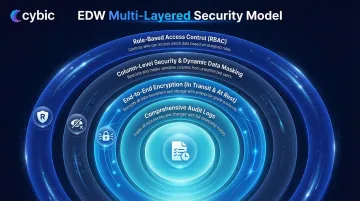
Multi-Layered Security Model
A production EDW requires:
- Role-Based Access Control (RBAC) : Mediates access through organizational roles rather than individual accounts, reducing security administration complexity without sacrificing control (NIST INCITS 359-2012).
- Column-Level Security and Dynamic Data Masking : Protects PII without restricting broader analytical access. BigQuery Policy Tags and Snowflake's dynamic data masking obscure sensitive data at query runtime without modifying stored data.
- End-to-End Encryption : Data encrypted in transit and at rest satisfies SOC 2, HIPAA, and GDPR requirements simultaneously.
- Comprehensive Audit Logs : An immutable record of every query and data action. Weak controls carry real costs: the HHS Office for Civil Rights fined Montefiore Medical Center $4.75 million after a malicious insider stole and sold protected health information.
Data Lineage and Its Operational Value
Data lineage traces exactly where a data point originated, how it was transformed, and which downstream reports depend on it. Lineage is essential for:
- Debugging analytical errors
- Passing compliance audits
- Building analyst trust in the data
Data Quality Governance
Automated processes for validation, cleansing, and enrichment must run continuously rather than as one-time projects. Quality governance must be enforced at:
- Pipeline level : Schema drift detection, null checks, type validation
- Semantic level : Business rules that define what "valid revenue" or "active customer" means across departments
Choosing the Right EDW Platform: Cloud, On-Premise, or Hybrid
Cloud vs. On-Premise TCO
| Dimension | On-Premise EDW | Cloud EDW |
|---|---|---|
| Cost Model | CapEx (High upfront hardware/software costs) | OpEx (Pay-as-you-go, variable subscription fees) |
| 5-Year TCO (Steady Workload) | ~$411,000 (200 vCPU / 200TB baseline) | ~$854,000 (Cloud costs double for 24/7 steady-state workloads) |
| Scalability & Time-to-Scale | Slow; requires hardware procurement | Instant; elastic scaling via configuration |
| Management Overhead | High; requires dedicated DBAs and sysadmins | Low; provider handles patching and infrastructure |
For most organizations today, cloud or hybrid is the operationally superior default but regulated sectors (public sector, healthcare) may have specific on-prem or hybrid mandates.
Cloud EDWs offer strong cost efficiency for variable or bursty workloads. For massive, predictable, 24/7 workloads, on-premise TCO can be meaningfully lower as the table above shows.
Platform Evaluation Framework
Compare EDW platforms across five criteria:
- Performance and concurrency : How the platform handles simultaneous queries and workloads
- Ecosystem fit : Native integrations with existing BI tools, cloud providers, and data pipelines
- Pricing model transparency : Decoupled storage/compute vs. node-based vs. serverless
- Semi-structured data support : Native handling of JSON, Parquet, Avro beyond standard structured data
- Multi-cloud and hybrid flexibility : For organizations with data sovereignty requirements or multi-cloud strategies
The 2024 and 2025 Gartner Magic Quadrants for Cloud Database Management Systems consistently position AWS, Google, Microsoft, Oracle, Databricks, and Snowflake in the Leaders quadrant.
Mitigating Vendor Lock-In with Open Data Formats
Platform lock-in is a real architectural risk, one that surfaces when migrating data, switching compute layers, or adopting a multi-cloud strategy later. Most major EDW vendors have responded by supporting open table formats that decouple storage from the query engine:
- Snowflake: Natively supports Apache Iceberg tables using Parquet files
- Google BigQuery: Supports BigLake Iceberg and Delta Lake external tables
- Amazon Redshift: Supports querying Apache Iceberg tables via Redshift Spectrum or Serverless
- Azure Synapse: Serverless SQL pools natively query Parquet and Delta Lake formats
When evaluating platforms, confirm open format support early. It's one of the few architectural decisions that's genuinely difficult to reverse after data volumes scale.
Building an AI-Ready EDW: The Bridge to Intelligent Automation
A governed, well-structured EDW is the prerequisite for enterprise AI and not an optional add-on. ML models require clean, consistent, historically complete data to train reliably. AI copilots and LLM applications require structured, metadata-enriched data to answer business questions accurately.
The AI readiness gap is severe: while 81% of Chief Data Officers prioritize AI investments, only 26% report their data is ready to support scaled AI. Gartner predicts 60% of AI projects will be abandoned by 2026 due to a lack of AI-ready data. Organizations that attempt to deploy AI on ungoverned, fragmented data sources consistently experience hallucinations, unreliable outputs, and failed adoption. The EDW is where AI gets its ground truth.
How a Modern EDW Evolves Into an AI Data Foundation
- Feature-ready datasets: The transformation layer produces clean, structured datasets for ML training pipelines
- Metadata as knowledge layer: The metadata catalog becomes what AI agents use to discover and interpret enterprise data
- Real-time ingestion: Streaming capabilities feed operational AI models for demand forecasting, predictive maintenance, or clinical risk scoring
Cybic's Drava platform connects a governed enterprise data layer (including EDW outputs) to ML pipelines, AI reasoning, and intelligent agent workflows. This gives organizations a direct path from structured data to operational AI that actually runs in production.
The platform embeds governance, security, and RBAC directly into the architecture. AI systems built on Drava operate with full auditability, role-based access controls, and a strict guarantee: no model training on proprietary enterprise data.
Organizational Readiness: The Missing Dimension
Technology alone doesn't determine whether AI deployments succeed. People and process close the gap between a working pilot and an AI system that scales across the organization.
Before deploying AI on your EDW, a data readiness audit should cover:
- Data quality and completeness across source systems
- Lineage documentation for critical datasets
- Access controls and role-based permissions
- Metadata coverage and catalog completeness
Organizations that run this audit before deployment avoid the most common failure mode: discovering data gaps after the AI system is already in production.
Frequently Asked Questions
What is an enterprise data warehouse?
An Enterprise Data Warehouse (EDW) is a centralized, governed repository that consolidates structured, analytics-ready data from across an organization into a single source of truth, designed specifically for BI, reporting, and advanced analytics rather than transactional processing.
How does an enterprise data warehouse (EDW) work?
Data is extracted from source systems, loaded into a cloud-native warehouse, and then transformed using the warehouse's compute engine producing structured, query-ready datasets that BI tools, analysts, and AI systems can access through SQL queries or API integrations.
What is an enterprise data strategy and what are its key pillars?
An enterprise data strategy is the organizational plan for how data is collected, governed, stored, and used to drive decisions. The key pillars typically include data governance, data quality, integration architecture, metadata management, and an analytics and AI roadmap.
Can an enterprise data warehouse be cloud-based (for example, on Azure)?
Yes, most modern EDW deployments are cloud-based. Microsoft Azure Synapse Analytics is one of the leading platforms alongside Snowflake, Google BigQuery, and Amazon Redshift offering on-demand scaling, managed infrastructure, and pay-as-you-go pricing.
What are the best enterprise data warehouse platforms?
The leading platforms are Snowflake, Google BigQuery, Amazon Redshift, and Microsoft Azure Synapse Analytics. The right choice depends on your workload type, existing cloud ecosystem, concurrency requirements, and cost model.
What are the core principles of enterprise data warehousing?
The four classic principles are subject-oriented organization, integration of disparate sources, time-variant historical storage, and non-volatility (data is not overwritten). Modern implementations add a fifth: governance-by-design, where access controls and data quality rules are embedded at the architectural level from the start.


