Introduction
Standard RAG works well - until it doesn't. When your knowledge base spans clinical records, compliance documents, operational logs, and product catalogs all at once, a single retriever starts conflating unrelated content. Context gets diluted. Hallucinations creep in. And the problem compounds at scale.
Google Research found that insufficient context can push an LLM's incorrect-answer rate from 10.2% to 66.1%. That's not a retrieval edge case - it's a structural failure mode that surfaces predictably as knowledge bases grow in scope and complexity.
Multi-agent RAG addresses this directly: rather than routing every query through a single retriever-generator loop, it distributes retrieval across a coordinated network of specialized agents, each responsible for a distinct domain of the knowledge problem.
What follows is a technical breakdown of how these systems are architected, where the implementation complexity lives, and the conditions under which multi-agent RAG earns its overhead - and when it doesn't.
Key Takeaways
- Multi-agent RAG replaces one generalist retriever with specialized agents, each owning a specific domain or data source
- Three layers drive the architecture: a routing orchestrator, domain-specialized RAG agents with tuned vector stores, and an aggregator that synthesizes the final response
- Single-agent RAG breaks when knowledge spans multiple domains, retrieval strategies differ by data type, or queries require multi-hop reasoning
- Enterprise deployments must address latency, governance, routing accuracy, and fault isolation alongside retrieval performance
What Is a Multi-Agent RAG System?
A multi-agent RAG system is an AI architecture in which a network of autonomous agents - each with a defined role - collaborates to retrieve relevant information from external knowledge bases and generate grounded, contextually accurate responses using a large language model.
The purpose: reduce hallucination, improve retrieval precision across heterogeneous data sources, and handle reasoning that a single retriever-generator loop can't manage at scale.
How It Differs from Standard and Agentic RAG
These three terms get used interchangeably, but they describe meaningfully different architectures:
| Architecture | Mechanism | Best fit |
|---|---|---|
| Standard RAG | One retriever, one vector store, one generator | Narrow, coherent knowledge domains |
| Agentic RAG | Single agent with retrieval tools and iterative reasoning | Complex queries needing decomposition, not source specialization |
| Multi-Agent RAG | Network of specialized agents coordinated by an orchestrator | Heterogeneous sources, multi-domain queries, independent scaling needs |

The distinction matters practically. Agentic RAG - as Microsoft describes it - decomposes a complex question into subqueries and executes retrieval iteratively. That's a single agent with more capable tools.
Multi-agent RAG introduces agent specialization: independent retrieval scopes, separate vector stores, and an orchestration layer that routes work between discrete agent units.
Conflating the two is a costly architectural mistake - either under-engineering (deploying agentic RAG when multi-agent coordination is needed) or over-engineering (standing up full multi-agent infrastructure when a well-prompted single agent would suffice). Getting the architecture right starts with understanding what each pattern actually does.
Why Enterprise AI Systems Need Multi-Agent RAG
Single-agent RAG fails in enterprise environments for a structural reason: one retriever cannot handle heterogeneous knowledge cleanly.
When a single vector store contains clinical records alongside compliance documents and operational logs, the retriever pulls context from all of them simultaneously. For a query about drug interaction protocols, that means mixing clinical evidence with policy text and maintenance logs. The retrieved context becomes noisy. The model hallucinates to fill gaps.
That's precisely what the ACL 2025 MAIN-RAG benchmark measured. Multi-agent filtering architectures - using Predictor, Judge, and Final-Predictor agents - improved answer accuracy by 2% to 11% over training-free baselines by targeting noisy retrieved documents directly.
Enterprise-Specific Demands
Multi-agent RAG addresses several problems single-agent systems simply can't:
- Domain-aware retrieval - different domains require different chunk sizes, embedding models, and top-k values; legal text and time-series logs need different retrieval strategies
- Multi-hop reasoning - queries that require sequential retrieval and intermediate reasoning (e.g., "which suppliers have compliance issues that overlap with our open purchase orders?") need agents that can chain context across sources
- Fault isolation - when one retrieval pathway fails, it shouldn't take down the entire pipeline
- Independent scaling - a high-traffic domain agent can be scaled horizontally without re-architecting the orchestrator or aggregator
For industries where AI decisions carry operational or regulatory weight - healthcare, energy, financial services - retrieval accuracy alone isn't sufficient. Outputs need to be traceable and auditable. Regulatory frameworks like EU AI Act Article 12 require automatic event logging for high-risk AI systems, and HIPAA 45 CFR 164.312 mandates access controls and audit trails for systems handling protected health information.
Cybic embeds governance controls - role-based access, auditability, and regulatory alignment - directly at the agent architecture level rather than bolting them on after deployment. In multi-agent systems, each retrieval path multiplies the surface area for unauthorized data exposure. That architectural decision matters.
How a Multi-Agent RAG System Works: Architecture and Flow
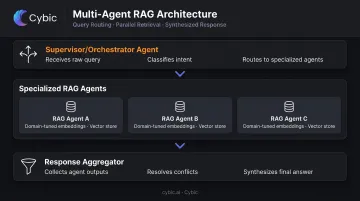
At a high level: a user query enters the system, an orchestrator classifies intent and routes the query to one or more specialized agents, each agent independently retrieves from its assigned vector store, and an aggregator synthesizes individual outputs into a coherent response.
The Three Architectural Layers
Layer 1 - Supervisor/Orchestrator Agent Receives the raw query, classifies it by domain or intent, and determines whether single-agent or multi-agent coordination is needed. Routing errors here compound across every downstream stage, making this the highest-leverage component to get right.
Layer 2 - Specialized RAG Agents Each agent owns a dedicated vector store with domain-tuned embedding strategies, chunk parameters, and prompts. Agents operate independently and can be versioned, optimized, or scaled without touching other agents.
Layer 3 - Response Aggregator Collects outputs from all invoked agents, resolves conflicts, and synthesizes a final answer. In well-designed systems, the aggregator also attributes which piece of information came from which agent and domain, enabling downstream auditability.
Frameworks like LangGraph make this structure explicit through defined Nodes (agent functions), Edges (control flow), and State (data passed between agents), which improves debuggability in distributed pipelines.
Step 1: Query Intake and Routing
The orchestrator receives the raw query and classifies it using an LLM-based classification function. Based on that classification, it routes to a single specialized agent or dispatches to multiple agents simultaneously.
Poor routing degrades every downstream stage. A query misrouted to the wrong specialized agent returns irrelevant context, and the aggregator has nothing useful to synthesize. Routing accuracy must be instrumented and monitored in production - not assumed to be correct.
Step 2: Specialized Retrieval
Each specialized agent retrieves against its dedicated vector store using domain-optimized parameters:
- Chunk size and overlap - controls context granularity and boundary bleed
- Top-k - sets how many candidate passages feed into generation
- Embedding model - must match the domain's vocabulary and semantic structure
More advanced implementations use interleaved retrieval and reasoning. Rather than retrieve-once-then-generate, the agent iterates between pulling context and refining its reasoning. This approach, demonstrated in IRCoT and FLARE, is particularly valuable for multi-hop queries where intermediate reasoning determines what to retrieve next.
Step 3: Response Aggregation and Output
The aggregator collects responses from all invoked agents and synthesizes the final answer. For single-domain queries, it effectively passes through the specialized agent's output directly.
For multi-domain queries, the aggregator does two things: it resolves conflicting information across agents, and it attributes each piece of the final response to its source agent and domain. That attribution is a hard requirement for auditability in regulated environments - healthcare, financial services, and government deployments in particular.
Key Factors That Affect Multi-Agent RAG Performance
Vector Store and Embedding Strategy
One-size-fits-all embedding strategies fail when agents handle structurally different content types. Dense legal text, time-series operational logs, and structured product catalogs each require different chunking and retrieval approaches.
- RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval) recursively embeds, clusters, and summarizes chunks to build multi-level abstraction trees - well suited for long documents where hierarchical context matters
- HNSW (Hierarchical Navigable Small World graphs) enables approximate nearest-neighbor search with a controllable hierarchy - appropriate for high-throughput retrieval where query latency is constrained
Orchestrator Routing Logic
Three primary approaches exist, each with trade-offs:
- LLM-based intent classification - flexible and handles novel queries, but adds inference latency at the routing step
- Rule-based keyword routing - fast and deterministic, but breaks on queries that don't match predefined patterns
- Hybrid routing - keyword rules for common query patterns, LLM classification for ambiguous cases; the most robust production approach
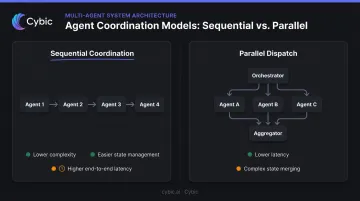
Latency and Agent Parallelism
Multi-agent architectures add round-trip overhead compared to single-agent RAG. As LangChain's multi-agent documentation notes, more calls mean higher latency, especially sequential calls, and higher per-request API costs.
The trade-off:
- Sequential coordination - lower complexity, easier state management, higher end-to-end latency
- Parallel dispatch - lower latency, but requires careful state merging at the aggregator when agents return simultaneously
For latency-sensitive applications, parallel dispatch is preferable where agent outputs are independent. For queries requiring intermediate reasoning between agents, sequential coordination is necessary.
Governance and Infrastructure
In regulated industries, each agent represents a distinct retrieval path - and each path is a potential vector for unauthorized data access. Role-based access controls must be enforced at the agent level, not just at the application layer.
This prevents an orchestrator from routing to a clinical agent and inadvertently exposing data the querying user isn't cleared to see.
The right infrastructure model treats agents as independently deployable services. Key deployment considerations include:
- Independent resource allocation per agent, so one high-load agent doesn't degrade the others
- Standardized agent discovery using protocols like Google's Agent2Agent (A2A) for interoperability across independently deployed services
- Cross-boundary coordination support for enterprise environments where agents are distributed across cloud regions or organizational units
Common Pitfalls and When Multi-Agent RAG May Not Be the Right Fit
The Most Common Misconception
More agents don't automatically mean better accuracy. A poorly designed routing layer or mismatched embedding strategy per agent will produce worse results than a well-tuned single-agent RAG, since routing errors propagate through every downstream agent. Multi-agent RAG requires proportionally more engineering rigor, not just more components.
When to Skip Multi-Agent RAG
Multi-agent RAG is the wrong choice when:
- The knowledge domain is narrow and coherent - a single well-structured vector store retrieves accurately without cross-domain contamination
- Query volume is low and latency is the primary constraint - multi-agent round trips add overhead that simpler architectures avoid
- The team lacks observability infrastructure - distributed agent pipelines are difficult to debug without proper instrumentation; building multi-agent RAG without it creates untraceable failure modes
- You're choosing it because it sounds more sophisticated - architecture decisions should be driven by diagnosed retrieval failures, not by preference for complexity
The Right Signal
The correct trigger for multi-agent RAG is a demonstrated failure in single-agent retrieval. Specifically, look for:
- Cross-domain contamination in retrieved context
- Persistent hallucination on multi-hop queries
- Retrieval that cannot scale independently across heterogeneous data sources
These failures, observed in production, justify the added complexity. The desire to build a more architecturally impressive system does not.
Frequently Asked Questions
What is a RAG system in simple terms?
RAG (Retrieval-Augmented Generation) is a method where an AI retrieves relevant information from an external knowledge base before generating a response. This grounds the output in factual, up-to-date data rather than relying solely on what the model learned during training.
What is the difference between a RAG agent and agentic RAG?
Agentic RAG is a single AI agent equipped with retrieval tools and iterative reasoning - it decides when and what to retrieve. Multi-agent RAG distributes these responsibilities across multiple specialized agents, each owning a domain or task, coordinated by an orchestrator.
What is an example of a multi-agent RAG system?
A healthcare organization might deploy a clinical documentation agent, a medical literature agent, and a regulatory compliance agent - all coordinated by a supervisor that routes physician queries to the appropriate specialist and aggregates responses into a single grounded answer.
When should you use multi-agent RAG instead of standard RAG?
Multi-agent RAG makes sense when the knowledge base spans multiple distinct domains with different retrieval needs, when single-agent retrieval produces cross-domain contamination or hallucinations, or when you need to scale different retrieval workloads independently. It's overkill when the domain is narrow, coherent, or low-volume.
What are the main challenges in building a multi-agent RAG system?
The hardest problems are designing a reliable orchestrator routing layer (misrouting degrades every downstream agent), managing latency from multi-agent round trips, and maintaining governance and auditability across all retrieval paths. Each requires more engineering rigor than standard RAG.
How does an orchestrator agent work in a multi-agent RAG system?
The orchestrator receives the incoming query, classifies its intent and domain using an LLM-based classification function, and routes the query to one or more specialized agents. It either passes through the response directly or hands it to an aggregator for synthesis - making it the highest-leverage component in the entire architecture.


