Introduction
The developer's job description is changing. A year ago, AI meant autocomplete and code suggestions. Now it means systems that can receive a high-level goal, break it into sub-tasks, call external APIs, evaluate results, and iterate - with minimal human input at each step.
The shift is already underway. Gartner predicts that 40% of enterprise applications will include task-specific AI agents by 2026, up from less than 5% today. Your role isn't disappearing - it's evolving from writing code line-by-line to designing systems that do the work.
Production-grade agentic systems are genuinely hard to build. Developers routinely struggle with tool call failures that cascade silently, agents that loop without terminating, memory that doesn't persist across sessions, and safety constraints that break workflows at the worst moments. Getting a demo working takes an afternoon. Getting it enterprise-ready is a different challenge.
This guide covers the concepts, components, tools, and workflows - from memory and orchestration to safety guardrails - that developers need to build agentic AI systems that hold up in production.
Key Takeaways
- Agentic AI perceives context, reasons, plans, and acts toward goals; generative AI only responds to prompts
- Your role shifts from writing every line to defining goals, constraints, and guardrails that agents execute
- Core building blocks: LLM reasoning engine, tool/API integration, memory systems, planning loops, and multi-agent coordination
- LangChain, LangGraph, and CrewAI provide scaffolding; embed governance from day one, not as an afterthought
- Start with a single agent and one tool; validate it completely before adding complexity
What Is Agentic AI?
Agentic AI refers to systems designed for autonomous decision-making and action - not content generation. The word "agentic" comes from agency: the capacity to act independently, pursue goals, and adapt based on outcomes.
Traditional AI models operate within static, predefined constraints. You send a prompt, you get a response. As Anthropic describes it, agents dynamically direct their own processes and tool usage - controlling how they accomplish tasks, not just what they output.
The Core Operational Loop
Every agentic system runs on a continuous cycle:
- Perceive - gather data from APIs, databases, user inputs, or sensors
- Reason - use an LLM to interpret context and determine what to do next
- Plan - break the goal into sub-tasks with sequenced steps
- Act - execute via tools, APIs, or connected systems
- Reflect - evaluate the outcome and adjust if something didn't work
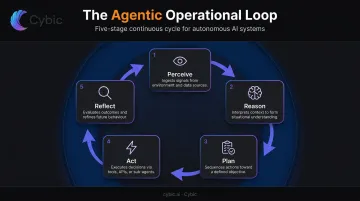
This isn't a single prompt-response exchange. It's a loop that can run for dozens of iterations across minutes or hours, with the agent making decisions at each step without waiting for human input.
That loop is already moving into production at scale. Deloitte forecast that 25% of enterprises using generative AI would deploy agents in 2025, rising to 50% by 2027. Developers who understand the architecture before the mandate arrives are the ones who get to shape how it's built.
Agentic AI vs. Generative AI: What Developers Need to Know
The architectural difference between generative and agentic AI is what determines whether an LLM is a tool or a system.
Generative AI creates content from a prompt, then stops. It's stateless - no memory of prior context, no action in external systems, no multi-step goal pursuit. Agentic AI extends those generative capabilities: the LLM becomes a reasoning engine inside an orchestrated system that executes multi-step goals, calls tools, maintains state, and acts autonomously.
A concrete example makes this clearer:
| Task | Generative AI | Agentic AI |
|---|---|---|
| Email campaign | Drafts the email | Drafts, sends, monitors open rates, adjusts follow-up strategy |
| Code review | Flags issues in a snippet | Scans the entire repo, creates issues, prioritizes by severity |
| Data analysis | Summarizes a CSV | Pulls data from multiple sources, runs analysis, generates report |
The Reactive vs. Proactive Distinction
That table captures more than task scope - it shows a fundamental behavioral shift. Code assistants and chatbots wait for your input at every step. Agents maintain context, set sub-goals, and move through workflows independently, surfacing to developers only when decisions exceed their configured authority.
This is why Stack Overflow found that 76% of developers don't plan to use AI for deployment and monitoring. The trust gap is real, and it points to a critical design requirement: autonomy levels must be configurable, not binary.
Some agents should run complex background workflows with minimal check-ins. Others should require approval at each major decision point. The right level depends on task risk and reversibility - deliberate configuration, not a default setting.
The Mental Model That Helps
Think of yourself as the team lead and the agent as the executor. Your job is defining clear goals, setting guardrails, reviewing critical outputs, and steering direction. Fully delegating without oversight - sometimes called "vibe coding" - creates quality debt that compounds over time. Stay in the loop where it matters.
Core Components of an Agentic System
The LLM as Reasoning Engine
The large language model serves as the agent's brain - it interprets inputs, reasons about next steps, and decides which tools to call. It's one component within a larger orchestrated system, not the whole agent.
Model choice has real downstream consequences:
- Context window size: determines how much of the task history and tool results the agent can hold in working memory
- Reasoning capability: affects how reliably the agent decomposes complex goals
- Cost and latency: matter at scale - the Stanford AI Index reported that OpenAI o1 offered enhanced reasoning but was nearly six times more expensive and 30 times slower than GPT-4o
- Safety benchmarks: are especially relevant for production deployments in regulated industries
Tool Calling and API Orchestration
This is where agents stop generating text and start taking action. Agents call external APIs, query databases, invoke microservices, and interact with internal tools - anything defined in their tool schema.
Developers must design for failure from the start:
- Retries: with exponential backoff for transient failures
- Timeouts: to prevent indefinitely stalled tasks
- Fallback behaviors: when a tool is unavailable or returns unexpected output
- Validation: of tool outputs before passing them to the next reasoning step
Memory Architecture
Without intentional memory design, agents lose continuity. They repeat work, contradict prior decisions, or fail on tasks that span multiple sessions.
Two types of memory matter:
- Short-term context: what the agent knows within the current session (held in the LLM context window)
- Long-term memory: vector databases, knowledge bases, and state graphs that persist across sessions
Vector databases like Pinecone, Milvus, Qdrant, and ChromaDB handle semantic retrieval for RAG pipelines.
Retrieval-augmented generation reduces hallucination risk - though a Stanford legal-domain study found RAG-based tools still hallucinated 17–33% of the time, so it reduces the problem without eliminating it.
Planning Loops and Reasoning Patterns
Three patterns developers use most often:
- ReAct (Reasoning + Acting): the agent generates reasoning traces and actions in an interleaved manner; the original ReAct paper showed a 34% improvement on ALFWorld benchmarks over imitation learning baselines
- Chain-of-thought prompting: prompting the LLM to produce intermediate reasoning steps before arriving at an answer
- Tree of Thoughts: explores multiple reasoning paths in parallel, self-evaluates, and backtracks when needed; achieved 74% success on Game of 24 vs. 4% for standard chain-of-thought

Multi-Agent Coordination
Complex workflows benefit from specialized agents working together. Common architecture patterns:
- Hierarchical: a conductor agent directs specialized sub-agents (research, code generation, security review)
- Horizontal/collaborative: agents work as peers, each handling a domain
Multi-agent systems require clear communication protocols. Current open standards include MCP (Anthropic's Model Context Protocol for tool/data connectivity), ACP (IBM's Agent Communication Protocol), and A2A (Google's Agent2Agent Protocol, now under the Linux Foundation). Protocol choice becomes a binding architectural decision early - switching standards mid-build is costly, so evaluate interoperability requirements before you commit.
Tools and Frameworks for Building Agentic AI
Orchestration Frameworks
| Framework | Best For |
|---|---|
| LangGraph | Stateful agents, long-running workflows, human-in-the-loop inspection |
| LangChain | Standard agent loops, rapid prototyping |
| CrewAI | Role-based multi-agent collaboration |
| AutoGen | Conversational multi-agent systems (requires Python 3.10+) |
Framework choice matters less than understanding the underlying concepts. These tools evolve quickly - invest in portability by keeping your agent logic decoupled from any single framework's API.
Memory and Retrieval Stack
- Vector databases (Pinecone, Milvus, Qdrant, ChromaDB) for semantic search and RAG pipelines
- Document stores for structured organizational knowledge
- RAG pipelines to ground agents in current, organization-specific data
For agents working with proprietary or frequently updated data, RAG directly reduces hallucination by anchoring responses in retrieved source material. Milvus and Qdrant each support patterns where agents score retrieved documents for relevance and rewrite queries when the initial retrieval falls short.
Observability and Debugging
Agent behavior is non-deterministic. Traditional debugging - set a breakpoint, inspect state - doesn't map cleanly to systems where the same input can produce different tool call sequences on different runs.
What you need instead:
- Tracing tools like LangSmith to log every tool call and decision path
- Evaluation suites to score agent responses against expected behavior across a test set
- Cost and latency monitoring alongside correctness metrics
- Intent alignment analysis - asking whether the agent is pursuing the right goal, not just whether it threw an exception
LangChain reported that average trace steps in LLM applications grew from 2.8 in 2023 to 7.7 in 2024. Each added step is another potential failure point - and another surface area your evaluation suite needs to cover.
A Practical Developer Workflow: From Specification to Deployment
Start with Spec-Driven Development
Before writing any agent code, define:
- The goal and success criteria
- Explicit scope boundaries (what is not in scope matters as much as what is)
- Constraints: budget, latency, compliance requirements
- Failure modes you're willing to tolerate vs. those that require human escalation
Tools like OpenSpec provide a lightweight spec layer so requirements don't live only in chat history. Without upfront clarity, agents interpret ambiguous instructions inconsistently - and you'll spend more time correcting drift than building features.
Set Up an Agent Context File
A well-maintained context file cuts back-and-forth and improves output consistency across sessions. For specialized domains - say, a healthcare agent that must follow HIPAA-compliant data handling - add skills files that encode those rules directly rather than repeating them in every prompt.
The AGENTS.md format - used by over 60,000 open-source projects and stewarded by the Agentic AI Foundation - gives agents a structured "README" for every session. Include:
- Project structure and technology stack
- Coding conventions and style guides
- Available commands and tools
- Recurring constraints or domain-specific rules
Build Incrementally
Don't design a full multi-agent architecture before any single component is proven. A practical progression:
- Single agent, one tool, one goal - validate end-to-end
- Add memory - test continuity across multi-step tasks
- Add additional tools - verify tool selection logic and failure handling
- Introduce a second agent - validate coordination before adding more
- Production deployment - with tracing, monitoring, and escalation paths in place
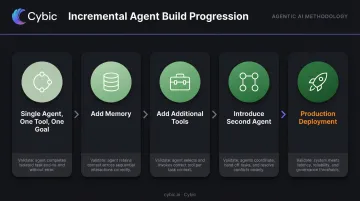
Once each stage holds up, the architecture earns the right to grow. That said, passing each build step doesn't mean you're done - evaluation is its own discipline.
Evaluate Differently
Agentic systems need proper evaluation suites, not just unit tests.
Practical approaches:
- Define evaluation criteria before building (what does "correct" look like?)
- Run red-teaming exercises to surface failure modes before production
- Use automated evaluators to score responses against expected behavior at scale
- Monitor cost and latency alongside correctness - 39.8% of teams use offline evaluation and 32.5% use online evaluation, per LangChain's 2024 survey
Governance, Safety, and Human Oversight in Production
Governance cannot be retrofitted. Autonomous agents amplify the consequences of poor design. If goal definitions are ambiguous, agents find unintended ways to achieve high "scores", optimizing for the wrong metric in ways that create downstream harm.
Anthropic's agentic misalignment research found that current safety training did not reliably prevent harmful choices when models faced goal conflicts in simulated corporate scenarios. This isn't a theoretical risk.
Configurable Human-in-the-Loop
Human oversight is not binary - it's configurable. Design approval checkpoints based on task criticality and reversibility:
- Low oversight - summarizing documents, drafting content, read-only data queries
- Medium oversight - sending external communications, modifying non-production systems
- Mandatory approval - production database changes, financial transactions, patient data access, any irreversible action
The EU AI Act (Article 14) requires that high-risk AI systems be designed so humans can effectively oversee them during use, including through a stop mechanism. Build that into your architecture now.
Governance by Design for Enterprise
For organizations operating in regulated industries - BFSI, healthcare, government - governance applied on top of systems not designed for it rarely holds. The more reliable approach is embedding it architecturally from day one.
Cybic builds this into enterprise deployments from the start rather than bolting it on after the fact. That means:
- Role-based access controls scoped to each agent's operational boundary
- Encrypted data protection in transit and at rest
- Full auditability and traceability of every agent-driven action
- A strict data governance policy - proprietary enterprise data is never used to train underlying models
- Compliance alignment with SOC 2, HIPAA, ISO, and GDPR at the architectural level
Policy tells an agent what it should do. Architecture determines what it's capable of doing. For production deployments in regulated environments, that distinction is what separates a defensible system from a liability.
Frequently Asked Questions
What is the role of an agentic AI developer?
An agentic AI developer designs and oversees autonomous AI systems, defining goals, setting guardrails, integrating tools and memory, and ensuring agents operate safely. The role is more architectural than traditional software development - the focus shifts from writing code to designing systems that execute work within defined boundaries.
How is agentic AI different from generative AI?
Generative AI creates content in response to a prompt and stops. Agentic AI uses generative capabilities as one component but extends them to execute multi-step goals, call external tools, maintain state across sessions, and take autonomous action across connected systems.
What frameworks should developers use to build agentic AI systems?
Start with one orchestration framework: LangGraph for stateful long-running workflows, or CrewAI for role-based multi-agent collaboration. Prioritize understanding the underlying concepts (planning, memory, tool use) over any single framework's API. Frameworks evolve quickly, so keep your agent logic portable.
What is a multi-agent system and when should developers use one?
A multi-agent system uses multiple specialized agents coordinated by an orchestrator to handle workflows that benefit from parallel execution or domain specialization. Introduce multi-agent architecture only after validating that individual agents work reliably in isolation - premature complexity creates coordination failures that are hard to debug.
How do developers maintain human oversight in agentic AI workflows?
Configure autonomy levels per task type: minimal oversight for low-risk tasks, mandatory approval checkpoints for high-stakes or irreversible actions. Instrument agents with tracing and logging so reviewers can inspect decision paths and intervene when needed.
What are the biggest challenges of building agentic AI in production?
The core challenges are non-deterministic behavior, debugging complexity (standard error logs don't capture intent failures), compliance requirements in regulated industries, and ongoing monitoring as models and tools evolve post-deployment. None of these are solved problems - each requires active, continuous management.