
Introduction
Physicians currently spend nearly two hours on EHR tasks for every hour of direct patient care - and that's before accounting for prior authorizations, billing codes, and the flood of multimodal data arriving from imaging systems, lab networks, and wearables. Medical image datasets alone are growing at 21–31% annually depending on modality. The workload isn't just heavy; it's structurally mismatched with how healthcare AI has historically been built.
Earlier AI tools (predictive models, rule-based alerts, standalone NLP classifiers) return a single output and stop. They don't coordinate across systems, adapt to context, or carry tasks through to completion.
AI agents work differently. They plan, remember, use tools, and execute multi-step workflows autonomously - a capability that maps far more closely to how clinical work actually unfolds.
This article covers what separates AI agents from traditional healthcare AI, where they're being deployed, how they're evaluated for safety, what's standing in the way of wider adoption, and where the most consequential development is happening.
Key Takeaways
- AI agents are autonomous, LLM-powered systems that plan and act across multiple steps - not glorified chatbots
- Active research systems like ZODIAC, MAGDA, and EHRAgent demonstrate the breadth of clinical and operational use cases
- Evaluation requires both technical metrics and clinical judgment - benchmarks alone don't confirm safe deployment
- Hallucination, interpretability gaps, and accountability ambiguity remain the most pressing deployment risks
- Clinician roles won't disappear - but they will need to change, with institutional support to match
What Sets AI Agents Apart from Traditional Healthcare AI
The Core Architecture
A 2026 Nature npj AI review defines healthcare AI agents as autonomous systems using an LLM as central controller, built around four core modules: planning, memory, tool use, and self-reflection. That architecture is what makes an agent fundamentally different from a predictive model or a search-augmented chatbot.
A rules-based expert system fires when conditions match a predefined trigger. A standalone ML model scores a lab value or flags an image. Both return outputs and stop. An AI agent can:
- Query an EHR for patient history
- Cross-reference imaging results with clinical guidelines
- Call a lab API for recent values
- Draft a clinical summary with recommendations
- Flag ambiguities for clinician review
All of that happens within a single, orchestrated task - without manual handoffs between systems.
Why Multi-Agent Architecture Fits Healthcare
Healthcare problems are rarely single-domain. Diagnosing a complex presentation might require integrating cardiology, radiology, pharmacology, and patient history simultaneously. No single model handles that well.
Multi-agent architectures address this directly. Specialized sub-agents (one for lab interpretation, one for imaging, one for coding) work in parallel under an orchestrating lead agent that synthesizes their outputs into a unified recommendation.
ClinicalAgents, developed by researchers at Hong Kong Polytechnic and HKUST, illustrates this pattern with three core components:
- Monte Carlo Tree Search orchestrator for structured reasoning across diagnostic paths
- Perceive-Hypothesize-Verify-Update loop for iterative clinical reasoning
- Dual memory layer: working memory for the current patient state, static memory for clinical guidelines
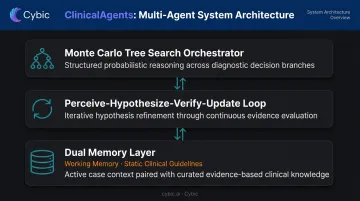
Each sub-agent contributes domain-specific depth, and the orchestrating layer keeps the outputs clinically coherent - something a single generalist model consistently struggles to achieve at this level of complexity.
AI Agent Applications Transforming Healthcare
Assisted Diagnosis and Clinical Decision Support
Diagnostic AI agents go well beyond single-model inference. They integrate multimodal inputs - imaging, labs, EHR history, clinical guidelines - and use multi-agent collaboration to reduce cognitive bias and build diagnostic consensus.
Three research systems illustrate the range:
- ZODIAC - A cardiologist-level LLM framework developed with affiliations including NYU, Stony Brook Medicine, and the University of Pennsylvania. It extracts patient characteristics, detects arrhythmias, and generates preliminary reports using multi-agent collaboration and cardiologist-adjudicated training data
- MAGDA - Developed at TU Munich, it provides multi-agent guideline-driven diagnostic assistance for radiology, particularly chest X-ray decision support. Agents synthesize prompts, screen images against clinical guidelines, and self-refine reasoning; evaluation on CheXpert and ChestX-ray14 showed improvement over zero-shot methods
- ClinicalLab/ClinicalAgent - An end-to-end multi-departmental diagnostic benchmark designed to evaluate agent performance across clinical specialties rather than a single domain
Emergency department triage is another active area. A 2024 JAMA Network Open study evaluated an LLM for adult ED acuity assessment, though fully autonomous agent-based triage remains research-stage. That constraint - keeping a human in the loop - reflects a design principle consistent across all of these systems: agents surface evidence and recommendations for clinician approval. Clinical judgment remains human.
Patient-Facing Health Management and Remote Monitoring
Conversational AI agents are finding traction in mental health and chronic disease management. MISHA, validated in a peer-reviewed randomized controlled trial published in JMIR, delivered chatbot-based stress management coaching for students with measurable outcomes.
A 2025 NEJM AI randomized trial of Therabot - a generative AI mental health chatbot - showed clinically meaningful reductions in depression and anxiety symptoms. It stands as one of the more rigorously controlled independent evaluations of patient-facing mental health AI published to date.
Remote monitoring presents a different problem: volume. A continuous glucose monitor generates up to 288 glucose values per day. Multiply that across a patient panel and it's not a data analysis problem - it's a data triage problem. AI agents address this by parsing high-volume sensor streams, surfacing only clinically relevant alerts, and enabling personalized follow-up between in-person visits.
Hospital Operations and Documentation
The administrative burden is well-documented. According to AMA survey data, physicians handle roughly 39 prior authorization requests per week, consuming approximately 13 staff hours.
EHR documentation compounds that load. A study of 155,000 physicians across 417 health systems found physicians spent 16 minutes 14 seconds per encounter on EHR interaction alone.
AI agents targeting these workflows include:
- EHRAgent - An LLM agent with a code execution interface that autonomously generates and runs code for multi-tabular EHR reasoning; reported 29.6% improvement over the strongest baseline
- Almanac Copilot - An autonomous agent for EMR tasks including information retrieval and order assistance
- Rx Strategist - Uses knowledge graphs and staged verification for prescription validation, reporting 75.93% accuracy and outperforming GPT-4o mini and Claude 3.5 Sonnet on the task
- MALADE - A multi-agent RAG system for adverse drug event extraction from drug labels (drug safety monitoring)
- MEDCO - A multi-agent framework for medical education, including simulated patient, expert doctor, and radiologist agents that create interactive clinical training scenarios

The education use case is particularly relevant for high-volume training programs, where access to live patient encounters is a real bottleneck. Simulated multi-agent scenarios offer a scalable alternative without that dependency.
Evaluating AI Agents in Healthcare: Frameworks and Metrics
Two Tiers of Evaluation
Evaluation in healthcare AI isn't binary. Most serious frameworks operate across two tiers:
Basic feasibility - objective and semantic correctness:
- Accuracy, F1-score, precision, recall, ROC-AUC
- Semantic metrics: BLEU, ROUGE, BERTScore
Reference models include BioGPT-Large at 81.0% PubMedQA accuracy, and Med-PaLM achieving 92.6% alignment with scientific consensus on human evaluation. MEDITRON-70B outperformed GPT-3.5 and Med-PaLM and came within 5% of GPT-4 on medical benchmarks.
These numbers matter - but they don't prove safe deployment. A model can score well on MedQA and still produce clinically dangerous outputs for rare presentations or ambiguous cases.
Developmental excellence - the fuller picture:
- Efficiency: response time, interaction rounds required
- Content quality: clinical completeness, readability, bias assessment across gender/race/age
- Humanistic care: empathy, patient satisfaction, adherence support
Recent research is increasingly demanding this second tier before recommending clinical adoption. Strong benchmark scores are the entry ticket - not the acceptance criteria.
Regulatory Frameworks Taking Shape
That distinction between entry ticket and acceptance criteria is exactly what regulators are now trying to codify. No single mature global standard exists yet, but several frameworks are actively shaping deployment requirements:
| Framework | Jurisdiction | Focus |
|---|---|---|
| MHRA AI Airlock | UK (launched Spring 2024) | Sandbox for AI as a Medical Device; assesses safety, effectiveness, adoption, and equity |
| CORE-MD | EU | Three-component evaluation: valid clinical association, technical performance, clinical performance |
| FDA PCCP Guidance | US (finalized 2025) | Predetermined Change Control Plans for AI-enabled devices |
| NMPA Guidelines | China | Classification and supervision of AI-based medical software |
What this means in practice: healthcare organizations evaluating vendor AI agents should demand evidence that maps to these frameworks - not just benchmark scores.
Most current metrics still leave critical questions unanswered:
- Economic impact of AI-assisted decisions
- Adverse event rates attributable to AI recommendations
- Satisfaction across patients, clinicians, and administrators
Until evaluation standards cover these dimensions, procurement decisions based on benchmarks alone carry real clinical and operational risk.
Real-World Challenges to AI Agent Deployment in Healthcare
Four Core Technical Risks
The research literature documents four deployment risks that healthcare organizations must treat as non-negotiable evaluation criteria:
- Hallucination - A 2025 analysis found that even medical-specialized models had 28.6%–61.9% accuracy on hallucination detection tasks; 91.8% of surveyed clinicians had encountered medical hallucinations, and 84.7% believed such errors could directly harm patients. One documented category: recommending amoxicillin despite documented severe penicillin allergy
- Lack of interpretability - A UK study of 40 healthcare professionals found 66.7% cited absence of detailed explanations for rare conditions as a primary transparency concern, with 50% stating AI outputs require human review before action
- Accountability ambiguity - In the same study, 70% said clinicians should bear primary responsibility for AI-augmented outcomes, while 57.5% said accountability should be shared with developers or institutions
- Data bias and privacy risk - A systematic review of 390 clinical AI/ML studies found 84% of global models did not report racial composition of training data; 31% lacked gender data entirely

Each of these risks is solvable - but only if governance architecture is built in from the start, not patched in after the fact.
Governance Must Be Embedded, Not Bolted On
Addressing these challenges requires security and compliance to be built into the architecture from day one - not retrofitted after deployment.
For healthcare organizations, the minimum architectural requirements include:
- Role-based access controls (RBAC) governing which users and agents can access which patient data
- Encryption of sensitive data in transit and at rest
- Auditability and traceability of all AI-driven actions, so every recommendation can be traced back through the reasoning chain
- Strict data governance - including clear policies against training models on proprietary patient data
At Cybic, these requirements aren't a checklist applied at the end of an engagement - they're embedded at the architectural level. HIPAA compliance, RBAC, and full audit trail mechanisms are scoped into the design before a single line of code is written.
Human and Institutional Barriers
Even with solid governance architecture in place, deployment can stall. Institutional and cultural barriers are just as likely to derail adoption as technical ones:
- Clinician resistance driven by fear of role displacement
- Difficulty building trust in opaque AI outputs
- Competing stakeholder expectations across patients, physicians, administrators, and payers
- Absence of effective feedback loops that allow AI agents to improve from real clinical use
Change management and co-design with clinical staff are as critical as the technology. Without them, even technically sound systems face adoption barriers that undermine their clinical value.
Future Directions: Where Healthcare AI Agents Are Headed
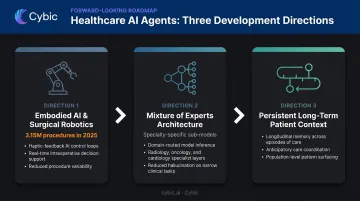
Embodied AI and Surgical Robotics
The integration of AI agents with physical robotic systems is already underway. The da Vinci Surgical System recorded approximately 3,153,000 procedures globally in 2025 - an 18% year-over-year increase - with an installed base of over 11,000 systems. It represents a predecessor to fully agentic surgical AI, where autonomous reasoning is coupled with physical action.
The safety, accountability, and regulatory challenges this introduces are significantly greater than those of advisory-only agents. Wide-scale adoption requires dedicated regulatory pathways that don't yet fully exist.
Mixture of Experts for Specialty Precision
Rather than scaling a single large generalist model, the MoE (Mixture of Experts) architecture dynamically activates specialized sub-models for specific clinical tasks - cardiology, oncology, pharmacology - as needed. The MoE-Health framework proposes this approach specifically for robust multimodal healthcare AI.
That means specialist-level precision on domain-specific tasks, delivered through a single inference pipeline. MoE has moved from theoretical architecture into active validation in professional medical AI systems.
Persistent, Long-Term Patient Context
Today's agents respond to discrete prompts and forget the conversation the moment it ends. Future systems will maintain continuous context about individual patients, population health trends, and evolving clinical workflows - enabling anticipatory care coordination rather than reactive responses.
A 2026 arXiv framework for longitudinal health AI agents proposes building around adaptation, coherence, continuity, and agency across repeated patient interactions. The downstream potential spans several dimensions:
- Earlier intervention through proactive pattern recognition
- Multi-department care coordination across a single patient timeline
- Interoperable agent networks operating across organizational boundaries
Redefining Clinical Roles
AI agents won't replace clinicians. They will, however, change what clinical work looks like - absorbing administrative burden, surfacing decision support, and handling data triage at scale. The American Medical Association adopted policy in 2024 to advance AI literacy in medical education through standardized training, and the National Academy of Medicine has addressed workforce readiness as a critical institutional priority.
The organizations that handle this transition well will invest proactively in training, human-AI collaboration frameworks, and institutional support structures. Organizations that delay will find themselves with capable AI tools and a workforce unprepared to use them - a gap that's harder to close than the technology itself.
Frequently Asked Questions
What is an AI agent in healthcare?
An AI agent is an autonomous, LLM-powered system capable of planning, retaining memory, using external tools, and executing multi-step clinical or operational tasks. Unlike a simple chatbot or single-purpose classifier, it coordinates across systems and adapts its behavior based on context and feedback.
How are AI agents in healthcare different from traditional clinical AI tools?
Traditional clinical AI returns an isolated prediction or output. AI agents orchestrate multi-step workflows, integrate across EHRs, imaging systems, and lab networks, and adapt behavior based on feedback - enabling tasks like end-to-end diagnostic support or prior authorization processing that no single model handles alone.
What are the biggest risks of deploying AI agents in clinical settings?
Four documented risks drive most governance concerns: hallucination (confident but incorrect outputs), lack of interpretability, accountability ambiguity, and data bias or privacy breaches. Mitigating each requires governance architecture that includes RBAC, encryption, auditability, and strict data governance controls.
How are AI agents in healthcare evaluated for safety and clinical accuracy?
Evaluation operates across two tiers: basic feasibility metrics (accuracy, F1-score, task completion) and developmental metrics covering efficiency, ethical compliance, bias assessment, and patient satisfaction. Emerging frameworks such as the UK MHRA AI Airlock and EU CORE-MD are beginning to standardize what evidence is required before deployment.
Will AI agents replace doctors and nurses?
No. AI agents absorb administrative burden and surface clinical decision support, but clinical judgment, patient empathy, and legal accountability remain human responsibilities. Successful adoption requires institutional investment in training and co-adaptation frameworks - not just technology deployment.
What regulations govern the use of AI agents in healthcare?
Key frameworks include: the EU AI Act (medical AI classified as high-risk under Article 6), the FDA's 2025 Predetermined Change Control Plan guidance for AI-enabled devices, and the US Algorithmic Accountability Act (S.2164). China's NMPA issued AI medical software classification guidance in 2021. Requirements differ substantially by jurisdiction and continue to shift.


