
Introduction
Financial institutions operate at a scale most industries never encounter. Visa's network alone processed 639 million transactions per day in fiscal year 2024.
Behind every one of those transactions sits a pipeline - or more accurately, dozens of them - spanning core banking platforms, payment processors, market data feeds, CRMs, and third-party data providers that rarely speak the same language.
The result is predictable: siloed data, slow regulatory reporting, fraud detection that can't keep pace with transaction velocity, and AI models that underperform not because the algorithms are weak, but because the data feeding them is inconsistent or stale.
Data engineering is what holds this together. Done well, it determines whether a financial institution can report accurately to regulators, catch fraud before losses compound, and build AI systems that perform in production - not just in testing.
This post covers the unique demands financial services places on data infrastructure, the core stack, and real use cases across fraud, credit risk, and compliance. It ends with the best practices that separate reliable pipelines from expensive ones.
Key Takeaways
- Financial services demands purpose-built data infrastructure: transaction velocity, regulatory obligations, and error consequences operate at a scale most industries never encounter.
- Core use cases include real-time fraud detection, automated regulatory reporting, credit risk modeling, and AML/KYC entity resolution.
- Best practices cover data quality across every pipeline layer, observability, modular architecture, and compliance built into the design from the start.
- Clean, governed data pipelines are the prerequisite for financial AI: the IIF-EY 2025 survey identifies data quality and availability as the biggest barriers to AI adoption in financial services.
Why Financial Services Creates Unique Data Engineering Demands
Three factors compound to make financial data engineering genuinely different from most other domains.
Velocity, Regulation, and Consequence
Transaction velocity is the obvious starting point - Mastercard processed 159.4 billion switched transactions in 2024 alone. Real-time payment networks, FX feeds, and options chains generate continuous data streams that batch processing can't handle for latency-sensitive operations.
Regulatory obligations add a layer most industries don't face. Frameworks like BCBS 239, MiFID II Article 16, SOX 404, and AML rule 31 CFR 1020.210 don't just require accurate numbers. They require documented controls, internal testing, and the ability to demonstrate how data was collected, transformed, and used. A pipeline that produces the right output but can't explain its inputs fails regulatory scrutiny.
The consequences of errors are also categorically different. In most industries, a bad pipeline produces a wrong report. In banking, it produces an incorrect credit decision, a missed fraud flag, or a materially misstated regulatory capital filing.
The Legacy System Problem
Most established banks and insurers run infrastructure built across multiple decades: mainframe cores, proprietary databases, and siloed systems that predate modern APIs.
Global banking technology spend reached $650 billion in 2023 according to McKinsey, with a significant portion absorbed by maintaining and bridging that legacy infrastructure rather than building net-new capabilities.
Data engineers at financial institutions routinely face the task of extracting data from systems that were never designed for extraction. They do this without disrupting live operations that process billions of dollars daily.
Data Sensitivity and Access Control
Financial data carries the strictest access control requirements of almost any sector. For transaction records, credit history, and PII, these controls aren't features to add later. They're core design requirements:
- Role-based access controls tied to data classification
- Encryption in transit and at rest
- Field-level masking for sensitive identifiers
- Tokenization for payment and account data
Regulators audit data management practices directly, not just final reports.
Core Components of a Financial Data Engineering Stack
Ingestion Layer
Financial data arrives from everywhere: transaction databases, market data APIs, payment processors, credit bureaus, customer portals, and third-party enrichment providers. The ingestion layer handles all of it.
Apache Kafka has become the standard for real-time event streaming in financial services. Nationwide Building Society, for example, adopted Kafka and Confluent Platform to support online banking, payment processing, mortgage applications, and Open Banking demands through an event-driven architecture.
For batch ingestion (monthly bureau pulls, end-of-day position files), cloud-native connectors like AWS Glue and Azure Data Factory handle structured extraction from source systems.
The trend toward event-driven ingestion over scheduled batch reflects a practical reality: financial operations increasingly require data within seconds, not hours.
Storage and Lakehouse Architecture
The traditional data warehouse, optimized purely for structured SQL queries, doesn't accommodate everything a modern financial institution needs to process: call center transcripts, scanned documents, and unstructured risk narratives alongside transaction tables.
The lakehouse architecture addresses this by combining warehouse-style governance with the flexibility of a data lake. Platforms like Snowflake, Databricks, and BigQuery power this layer.
MUFG Bank selected Databricks as its next-generation data and AI platform in April 2025, specifically to consolidate AI model development and support fraud detection, risk management, and operations automation across 30,000 employees.
Transformation Layer
Raw financial data is messy. Currency normalization, customer record deduplication across systems, and standardizing counterparty identifiers (LEIs, BICs) for cross-system analysis are routine transformation challenges.
dbt (data build tool) now leads most financial data teams' transformation stacks, bringing software engineering practices - version control, testing, documentation - to SQL transformations. The lineage graphs dbt generates also serve a compliance function, showing how derived metrics trace back to source data.
Real-Time vs. Batch Processing
Not every financial use case requires the same latency profile:
| Use Case | Processing Model | Typical Latency Target |
|---|---|---|
| Fraud scoring | Stream processing | Sub-100ms |
| AML transaction monitoring | Stream processing | Near real-time |
| End-of-day settlement | Batch | End of business day |
| Monthly regulatory reports | Batch | Scheduled submission |
| Credit bureau data pull | Batch | Per-application |

Apache Flink and Kafka Streams handle stream processing for latency-sensitive cases. Most financial institutions run both in parallel; the architecture decision comes down to matching the right model to the latency requirement.
Orchestration and Monitoring
Complex financial pipelines have dependencies: a regulatory report can't run until position data is reconciled, which can't run until trade confirmation files have loaded. Tools like Apache Airflow, Prefect, and Dagster manage these dependency chains with SLA enforcement and automated alerting.
In financial services, pipeline failure isn't just a technical incident. A missed regulatory submission carries real compliance consequences. Orchestration with built-in runbook automation is a production requirement, not an enhancement.
Real Use Cases: Data Engineering Across Financial Services
Fraud Detection and Prevention Pipelines
Real-time fraud detection is one of the most technically demanding data engineering problems in finance. The architecture looks like this:
- Event stream ingestion - payment events flow from card networks into a stream processor (Kafka, Flink)
- Feature computation - transaction velocity, geolocation delta, device fingerprint, merchant category are computed against a feature store in near real time
- Model scoring - enriched features are passed to a fraud model, which returns a risk score
- Decision and response - scores above threshold trigger decline or step-up authentication
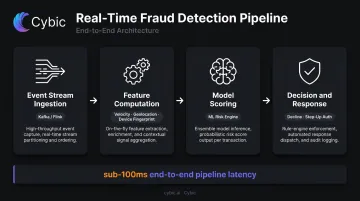
The latency requirement is unforgiving. Mastercard's Decision Intelligence Pro assesses transaction risk in less than 50 milliseconds, with initial modeling showing fraud detection rates improved by 20% on average and false positives reduced by more than 85%. Getting both right simultaneously - more fraud caught, fewer legitimate transactions blocked - is only possible when the underlying pipeline delivers consistent, fresh features reliably.
The engineering challenge isn't the model. It's building a pipeline that delivers consistent, fresh features at sub-100ms latency, 24/7, across global transaction volumes.
Credit Risk Modeling and Loan Origination
Automated credit decisioning depends on pipelines that aggregate data from multiple bureau sources - Equifax, Experian, TransUnion - alongside internal transaction history and increasingly, alternative data such as rent payments, utility data, and bank account cash flow.
Each bureau returns data in different formats, with different field naming conventions and data organization. Before a credit model can score an applicant, those inputs need to be reconciled, deduplicated, and normalized. A CFPB study analyzing 200,000 credit files found that different scoring models placed consumers in the same credit quality category only 73–80% of the time - showing how differently the same consumer can appear across bureau formats.
That normalization work doesn't stop at origination. Streaming pipelines enable continuous credit monitoring, so risk models can flag a deteriorating borrower profile between scheduled reviews rather than catching it only at annual renewal.
ECOA/Regulation B adds a non-negotiable governance layer: creditors must retain all information used in evaluating applications for 25 months and provide specific reasons for adverse actions. Every feature input to a credit model needs to be auditable - for regulatory examination and for adverse-action notices when complex algorithms are involved.
Regulatory Reporting and Compliance Data Pipelines
US financial institutions produce standardized reports for multiple regulators - Call Reports for the FDIC/FFIEC, FR Y-9C for the Federal Reserve, FOCUS reports for FINRA and the SEC - each with specific data formats, reconciliation requirements, and submission deadlines.
Data engineering teams build automated pipelines that:
- Pull from authoritative source systems
- Apply regulatory calculation logic
- Reconcile outputs against source data
- Produce audit-ready reports with full transformation history
BCBS 239 (Principles for Effective Risk Data Aggregation and Risk Reporting) sets the governance standard here - requiring banks to design data architecture that fully supports risk data aggregation in both normal conditions and stress scenarios, with accuracy, completeness, and timeliness as explicit requirements.
Tools like dbt's lineage graphs, Databricks Unity Catalog, and Apache Atlas provide column-level data lineage that satisfies examiner inquiry - showing not just what the number is, but which source table it came from and how it was transformed.
AML/KYC Data Workflows
Anti-money laundering pipelines operate at significant scale. FinCEN reported 4.7 million Suspicious Activity Reports filed in FY2024 - averaging 12,870 daily SAR filings - which gives a sense of the transaction monitoring volume financial institutions must process.
The data engineering requirements for AML/KYC include:
- Entity resolution - matching and deduplicating customer identities across accounts, products, and subsidiaries
- Graph analytics - detecting suspicious transaction patterns between counterparties that aren't visible in individual account views
- Watchlist screening - continuously matching customer and transaction data against OFAC, PEP, and sanctions lists in real time
- Customer due diligence data pipelines - collecting and maintaining beneficial ownership information per FinCEN's CDD rule requirements
The FFIEC BSA/AML Examination Manual governs examiner expectations for all of these - transaction monitoring, customer due diligence, and OFAC controls are evaluated as program components, not isolated checks.
Regulatory Compliance as a Data Engineering Requirement
Compliance in financial services cannot be retrofitted. A pipeline built without access controls, without audit logging, and without lineage tracking doesn't become compliant by adding those features later - the history is already unauditable.
"Compliance by design" means:
- Data lineage tracking built into every transformation layer
- Immutable audit logs capturing who accessed what data and when
- Retention policies automated at the storage layer (not enforced manually)
- Role-based access controls defined before the first query runs
- PII classification and masking applied at ingestion, not downstream

Regulators including the SEC and OCC increasingly audit data management practices directly during examinations, not just the accuracy of final reports but the controls and documentation behind them. OCC Bulletin 2024-26 updated FFIEC IT examination procedures to include evaluation of development, acquisition, and maintenance controls. The Federal Reserve's SR 11-7 explicitly requires rigorous assessment of data quality and relevance for model inputs.
For financial institutions operating globally, cross-border data residency adds another layer. US institutions serving EU customers must manage GDPR obligations, governing where data can be stored and processed, alongside domestic requirements. Zone-based architecture, where data is physically partitioned by jurisdiction, is the standard engineering response to cross-border compliance.
Cybic's governance-embedded-by-design approach reflects this same principle: building security controls, RBAC, audit trails, and regulatory alignment at the architectural level across every engagement, rather than layering compliance onto pre-built pipelines. The result is infrastructure that holds up under examination - not just operationally sound, but documentably so.
Best Practices for Financial Data Engineering Teams
Data Quality as a First-Class Concern
Data quality failures in finance have direct consequences - incorrect risk weights, erroneous fraud flags, misstated regulatory capital. BCBS 239 Principle 3 explicitly requires accurate and reliable risk data with largely automated aggregation to minimize errors.
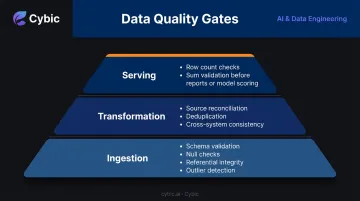
Best practice is to implement quality checks at three layers:
- Ingestion - schema validation, null checks, referential integrity, outlier detection before data enters the pipeline
- Transformation - reconciliation against source system totals, deduplication checks, cross-system consistency validation
- Serving - row count and sum checks before reports are filed or models are scored against production data
Design for Observability
Financial pipelines need end-to-end monitoring - not just "did the job run?" but "is the data fresh, complete, and within expected ranges?"
Key observability components:
- Pipeline run status with failure alerting and runbook-driven incident response
- Data freshness monitoring - if end-of-day positions aren't available by 6pm, downstream settlement fails
- Volume anomaly detection - a sudden 40% drop in transaction count may indicate a feed failure, not a quiet day
- SLA tracking with escalation paths for regulatory reporting deadlines
Build Modular, Reusable Data Products
Observability tells you when something breaks. Modular architecture reduces how often it does. Monolithic pipelines accumulate technical debt quickly as regulatory requirements evolve - domain-oriented data products are the more durable pattern:
- Customer 360 - a single authoritative source that fraud, credit, marketing, and compliance teams all query, rather than each maintaining separate copies
- Transaction enriched - standard enrichments applied once at the product layer, eliminating duplicated logic across teams
- Regulatory position - a shared calculation layer that feeds multiple report types from one set of rules
This reduces duplication, improves consistency, and makes it easier to update logic when regulations change.
From Data Engineering to AI: Building Intelligence Into Financial Operations
The most common failure mode in financial AI isn't a weak model - it's inconsistent features, stale data, or quality issues that weren't detected upstream. A fraud model trained on clean historical data but served stale features in production will underperform - and those failures are hard to trace back to the source.
A well-engineered feature store - a centralized repository of pre-computed, versioned features - solves this by ensuring the same feature definitions and freshness guarantees apply to both model training and real-time inference. This architecture prevents feature drift and training-serving skew before they compound into measurable performance degradation.
The AI use cases this foundation enables in financial services are expanding quickly:
- Generative AI for investment research - requiring structured pipelines feeding real-time earnings data and SEC filings to LLM reasoning layers
- Automated underwriting - combining ML scoring with real-time data enrichment from bureaus and alternative sources
- AI-driven customer segmentation - requiring unified customer data across all product lines, which only exists if the data engineering is right
Deloitte's 2025 survey found AI use by surveyed banks rose from 56% in 2023 to 67% in 2025. The firms moving fastest built their data infrastructure before deploying AI - not in parallel with it.
Cybic's Drava platform connects enterprise data pipelines, machine learning, AI reasoning, and intelligent agents in a single governed system. For financial services teams, that means each new use case - fraud detection, underwriting, customer analytics - can be deployed on a shared, auditable foundation with RBAC and governance already in place.
Frequently Asked Questions
What is BSI in engineering?
In cloud and data engineering, BSI most often refers to Germany's Federal Office for Information Security (Bundesamt für Sicherheit in der Informationstechnik), which publishes the BSI C5 Cloud Computing Compliance Criteria Catalogue. C5 defines minimum requirements for secure cloud computing and is referenced by financial services firms - including US-based multinationals - evaluating cloud infrastructure compliance in Germany and the EU.
What is data engineering in financial services?
Data engineering in financial services covers designing, building, and maintaining the pipelines, storage systems, and transformation processes that move financial data - transactions, market feeds, customer records, risk data - for analytics, regulatory reporting, and AI applications. It is the foundational layer that determines whether downstream analytics and compliance functions are reliable.
What are the most common data engineering use cases in banking?
The top use cases are real-time fraud detection pipelines, automated regulatory reporting (Fed, OCC, FINRA, SEC), credit risk data workflows, AML/KYC entity resolution and watchlist screening, and customer 360 data products that unify customer data across product lines for consistent use in analytics and compliance.
How does data engineering support regulatory compliance in financial services?
Data engineering enables compliance by automating data collection, transformation, and report generation for regulatory submissions. It also provides the data lineage, audit trails, and access controls that regulators require firms to demonstrate during examinations - the documented path from source to output, not just the final numbers.
What is the difference between batch and real-time data processing in finance?
Batch processing handles large data volumes at scheduled intervals - end-of-day settlement reports, monthly regulatory filings. Real-time (stream) processing handles data as it arrives for latency-sensitive operations like fraud detection, live risk monitoring, and instant payment validation. Most modern financial institutions run both: stream processing for sub-second decisions, batch for high-volume scheduled workloads.
What tools are commonly used for financial services data engineering?
Widely adopted tools include:
- Apache Kafka - real-time event streaming
- Apache Spark - large-scale batch processing
- dbt - data transformation
- Snowflake / Databricks - cloud data platforms
- Apache Airflow - pipeline orchestration
- Databricks Unity Catalog / Apache Atlas - data governance and lineage tracking


