
Introduction
Financial institutions are accelerating AI investment at a remarkable pace - 75% of UK financial services firms were already using AI in 2024, up from 58% just two years prior. Yet the same industry faces a more fundamental problem that no model architecture can solve: the data powering these systems is often incomplete, untraceable, or ungoverned.
That gap is expensive. The OCC assessed a $400 million civil money penalty against Citibank in 2020 for deficiencies that included data governance and internal controls. FinCEN levied a $1.3 billion penalty against TD Bank in 2024 tied to transaction-monitoring failures.
A wrong decision in financial services is rarely just a business miss. It can trigger regulatory penalties, erode customer trust, or create fraud exposure. And every strategic decision traces back to the quality of the data behind it.
This article breaks down what a financial data strategy actually requires - why most fail, what the reliable ones share, and how governance and AI readiness translate into measurable outcomes.
Key Takeaways
- A financial data strategy is a structured framework for collecting, governing, and activating data to enable reliable, traceable decisions
- Poor data quality, missing lineage, and siloed systems are the root cause when financial data initiatives underdeliver
- Embed governance into the architecture from day one - bolting it on after deployment rarely works
- AI models in financial services are only as reliable as the data pipelines feeding them
- Payoffs are concrete: faster regulatory reporting, sharper risk models, and AI outputs that hold up under audit
What Is a Data Strategy in Financial Services?
A financial data strategy is the deliberate framework governing how an institution collects, stores, governs, and activates data to achieve specific business outcomes. Unlike IT data management - which focuses on storage and infrastructure - a data strategy is fundamentally about decision value: connecting data infrastructure to the institution's ability to act with confidence.
Financial services is uniquely complex territory for data. Three intersecting pressures make the stakes higher than in most industries:
- Regulatory density: SOX, GDPR, BSA/AML, and DORA each impose distinct data control requirements, and compliance failures carry direct financial penalties
- Data sensitivity: PII, transaction records, and account histories are high-value targets for fraud and high-liability assets under regulation
- Decision speed: Fraud detection, credit approvals, and trading decisions require real-time data inputs where staleness isn't just inconvenient - it's dangerous
A well-executed data strategy turns raw data into traceable, auditable inputs that AI models, risk frameworks, and regulatory reports can actually rely on. That shift - from scattered data assets to governed, decision-ready infrastructure - is what the sections below are designed to help financial institutions achieve.
Why Most Financial Data Strategies Fall Short
Siloed Systems and Fragmented Data Ownership
Most financial institutions operate across a combination of legacy core banking systems, modern cloud platforms, and third-party data sources that don't naturally communicate. The result is data silos where the same customer may carry different profiles across systems: conflicting addresses, inconsistent risk classifications, and mismatched account histories.
The scale of the problem is well-documented:
- The Bank of England and FCA's 2022 ML survey identified legacy systems as the greatest perceived constraint to ML adoption
- Deloitte's 2024 banking and capital markets survey found 86% of respondents cite ease of data access as a top concern
- McKinsey estimates the right data architecture can cut implementation time in half and lower costs by 20%

The inverse of that last figure is what fragmented architecture costs institutions every day.
The Hidden Cost of Poor Data Quality
Poor data quality rarely announces itself. Credit models trained on inaccurate inputs produce distorted risk scores, and AML systems miss suspicious transaction patterns. The damage accumulates silently until a regulatory examination or a fraud loss surfaces the problem.
Gartner estimates poor data quality costs organizations an average of $12.9 million annually - and that's a cross-industry figure. In financial services, where enforcement penalties compound the operational losses, the true cost is higher.
The data lineage gap compounds this further. When an institution cannot trace a credit decision back to its source data and transformations, it cannot defend that decision to regulators. The Basel Committee's 2023 progress report found that only 2 of 31 assessed G-SIBs were fully compliant with all BCBS 239 principles, meaning the majority of global systemically important banks still cannot reliably aggregate and report risk data as required.
Lineage is not a technical feature. It is a regulatory necessity.
Governance Added as an Afterthought
Many institutions build data platforms first and attempt to impose governance later. The results are predictable: inconsistent master data definitions, thousands of cost centers with no standardization, and shadow spreadsheets maintained by business units that systematically undermine the official systems.
Red flags that signal a governance-deficient strategy:
- Model predictions cannot be traced back to source data
- Business teams maintain parallel spreadsheets because they don't trust central systems
- Monitoring tools exist but go largely unused
- Regulatory reporting takes weeks to compile rather than days
Two or more of these signals appearing together indicate a structural problem - one that incremental fixes won't resolve. The architecture itself needs to be reconsidered.
The Essential Components of a Strong Financial Data Strategy
Data Quality Management
Data quality in financial services must be evaluated across four dimensions that directly affect decision reliability:
| Dimension | What It Means | Why It Matters |
|---|---|---|
| Completeness | No missing inputs in risk models or credit files | Incomplete data produces gaps in model coverage |
| Accuracy | Correct and current customer and account data | Stale or wrong inputs corrupt every downstream output |
| Consistency | Unified definitions across all systems and business units | Inconsistent definitions make cross-system analysis unreliable |
| Timeliness | Real-time freshness for fraud detection and market risk | Delayed data turns risk management into historical review |

Embed quality gates at ingestion, transformation, and output layers - not only at the point of entry. The BoE/FCA 2022 survey found 43% of financial firms identified data quality and structure issues as a major ML-related risk.
Data Lineage and Metadata Tracking
Lineage is the documented trail every data point travels from its source through transformations to its use in a model, report, or decision. Without it, institutions face compounding problems:
- Cannot explain a model output to regulators or internal reviewers
- Cannot identify which downstream decisions are affected when source data changes
- Cannot respond to an examination without manual, time-consuming reconstruction
Metadata layers make lineage searchable and auditable. Compliance teams can access the trail directly - the difference between a one-hour audit response and a three-week reconstruction exercise.
Unified Data Architecture
The evolution from isolated data warehouses toward modern architectures - cloud-native, hybrid, and lakehouse designs - allows institutions to process both structured financial data and unstructured inputs such as customer communications and market signals. Deloitte's 2024 survey found 52% of banking organizations had migrated more than half of their data to the cloud.
The architecture must be infrastructure-agnostic, capable of operating across legacy on-premises systems and modern cloud environments, so governance and data quality standards apply consistently regardless of where data lives.
Real-Time Data Observability
Financial decisions operate at speed. Fraud signals must be detected within the payment processing window. Credit approvals happen in real time. Risk exposures shift with market movement. The Federal Reserve's FedNow guidance states that systems analyzing incoming transaction data in real time, 24x7x365, are what prevent fraudulent transactions from completing.
Missing observability has concrete consequences:
- Stale fraud models that miss new attack vectors
- Risk dashboards built on hours-old data
- Compliance reports that reflect yesterday's reality rather than today's exposure
BIS Project Hertha found that real-time payment analytics helped identify 12% more illicit accounts and improved detection of previously unseen financial crime patterns by 26% - a direct return on observability investment.
Integrated Data Intelligence
Those observability gains compound when data quality, governance, and AI operate as a single system rather than separate programs. The most capable institutions connect data pipelines directly into governed machine learning workflows - closing the gap between raw data and auditable decisions.
Cybic's Drava platform is built on this architecture: it connects enterprise data pipelines, machine learning, AI reasoning, and intelligent agents into unified, auditable workflows. Orchestration, security controls, and governance frameworks are embedded at the design level rather than added afterward. For financial institutions, that means moving from raw data to actionable intelligence without introducing compliance gaps in between.
Data Governance: The Backbone of Reliable Decision-Making
Effective data governance defines who owns data, how it is created and modified, what standards it must meet, and how every decision derived from it is logged and traceable. It is the operating layer that holds every other component of a data strategy together. Remove it, and quality standards decay, shadow systems multiply, and audit trails disappear.
People - Roles and Accountability
A functional financial data governance model requires clearly defined roles:
- Chief Data Officer (CDO): Owns the strategic vision and regulatory accountability at the executive level
- Domain Data Stewards: Maintain quality standards within specific business areas - lending, risk, compliance
- Business Data Owners: Accountable for the accuracy of data assets within their function
- Data Governance Council: Cross-functional body bridging business, compliance, and engineering

Without assigned ownership, data quality erodes and uncontrolled local practices fill the vacuum. The governance council is what keeps individual business units aligned - and what makes the process layer below it enforceable.
Process - Policies, Standards, and Lifecycle Management
Defined roles mean nothing without the policies that govern how data actually moves through its lifecycle:
- Creation: Master data management with defined naming conventions and validation rules
- Change: Documented change management with impact assessment before modifications propagate
- Quality enforcement: Automated quality thresholds and escalation paths when standards aren't met
- Retirement: Structured decommissioning that preserves lineage and audit records
Mature process governance reduces regulatory reporting time from weeks to days because the data trail already exists in a structured, audit-ready format. The Bank of England's digital regulatory reporting initiative is built on this premise - machine-executable regulatory reporting depends on common data standards and structured data processes.
Technology - Controls, Access, and Auditability
The technology layer of governance includes three non-negotiable controls:
- Role-based access controls (RBAC): Enforce least-privilege access to sensitive financial data
- Encryption: Protect customer and transaction data in transit and at rest
- Automated auditability: Immutable, timestamped logs of every data modification and AI-driven action
Cybic builds these controls at the architectural level - embedded from initial design rather than added after deployment. That distinction matters because governance controls applied post-deployment can be bypassed, degraded, or simply not extended to new data sources as they're added. When governance is architectural rather than bolted on, it extends automatically to every new data source, pipeline, and AI-driven workflow added to the system.
Building AI Readiness Into Your Data Strategy
AI adoption in financial services - credit scoring, fraud detection, regulatory capital modeling, customer personalization - runs entirely on the data foundation beneath it. The IIF-EY 2024 financial services AI survey found that data quality (16%) and data availability (12%) were the top barriers to production AI - not model limitations. The Federal Reserve's SR 11-7 model risk guidance is unambiguous: model output quality depends on input data, and errors in inputs produce inaccurate outputs.
What AI-Ready Data Looks Like
In regulated environments, production AI deployment demands four specific data properties:
- Governed: Clear ownership, access controls, and documented change history
- Traceable: Full lineage from source through transformation to model input and prediction output
- Tested: Validated at ingestion, transformation, and prediction layers - not just at the software development stage
- Explainable: Outputs can be connected to specific data inputs, enabling regulatory justification for automated decisions such as loan denials or fraud flags
Maturity Levels for Self-Assessment
Financial institutions can assess their AI readiness against three levels:
| Maturity Level | Governance State | AI Reliability | Regulatory Readiness |
|---|---|---|---|
| Reactive | Absent or entirely manual | Inconsistent; outputs cannot be explained or audited | Failures discovered through external events |
| Operational | Standardized controls in place | Improving, but lineage and observability gaps limit reliability | Performance measured, not proactively managed |
| Strategic | Proactive monitoring with full traceability | Data quality failures caught before they affect models | Examination responses measured in hours, not weeks |
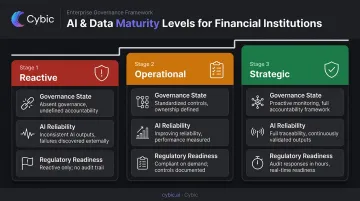
The gap between Reactive and Strategic is a data infrastructure and governance problem, not a model problem. That distinction determines where remediation effort should be directed - and why data strategy must precede AI investment.
Frequently Asked Questions
What is the data strategy for financial services?
A financial data strategy is a structured organizational framework for collecting, governing, and activating data to support reliable business decisions, regulatory compliance, and AI adoption. It differs from general data management by aligning every data capability directly to business outcomes and regulatory accountability rather than treating storage and infrastructure as ends in themselves.
What are the essential components of a data strategy in financial services?
The five core components are data quality management (completeness, accuracy, consistency, timeliness), data lineage and metadata tracking, unified data architecture, real-time observability, and integrated governance. All five must work together, because gaps in any one component degrade the reliability of the others.
How does data governance support regulatory compliance in financial services?
Governance creates documented, auditable data trails that allow institutions to demonstrate data accuracy, access control, and process integrity to regulators under frameworks such as SOX, GDPR, and BSA/AML. Well-structured governance reduces audit preparation time and lowers the risk of regulatory findings by keeping compliance evidence readily available.
What role does data quality play in AI adoption for financial institutions?
AI models are only as reliable as their training and inference data. Poor quality data leads to inaccurate risk scores, missed fraud signals, and model outputs that cannot be explained or defended to regulators. Data quality is the precondition for responsible AI deployment, not a parallel workstream.
How do financial institutions measure the success of their data strategy?
Key metrics include reduction in regulatory reporting cycle time, improvement in model accuracy and stability, decrease in data incident rate, and audit response speed. Mature institutions tie these directly to business outcomes such as loan default rates and fraud loss ratios.
What is data lineage and why does it matter in banking?
Data lineage is the documented record of where a data point originated and every transformation it underwent before use in a report, model, or decision. In banking, complete lineage is required for model risk validation, regulatory examination responses, and explaining automated decisions - such as credit denials - to regulators and customers.


