According to MuleSoft's 2025 Connectivity Benchmark Report, the average enterprise now runs 897 applications, with 46% using 1,000 or more - and 95% of IT leaders cite integration complexity as a direct barrier to effective AI implementation.
This guide covers what enterprise data integration actually is, the five core methods, how to build a strategy that holds up under real-world conditions, why governance must be baked in from the start, and how integrated data unlocks AI at scale. It's written for IT leaders, data architects, and business decision-makers - not vendor evaluation committees.
Key Takeaways
- Enterprise data integration unifies disparate systems into a governed, trustworthy data environment - one that evolves with the business, not a one-time pipeline build.
- ETL, ELT, API integration, data virtualization, and data fabric are distinct approaches - each suited to specific latency, volume, and compliance requirements.
- Strategy should start with business outcomes, not technology selection.
- Governance, RBAC, encryption, and audit controls must be architectural decisions - not retrofits.
- Without integrated, governed data, AI and intelligent automation produce unreliable results - regardless of the models or tools used.
What Is Enterprise Data Integration?
Enterprise data integration is the practice of connecting an organization's disparate systems - CRMs, ERPs, HR platforms, operational databases, cloud services, and legacy infrastructure - into a unified environment where data can be accessed consistently, trusted across business units, and acted on without manual reconciliation.
This is distinct from point-to-point integrations or one-off data migrations. Point-to-point connects two specific systems directly; a migration moves data from System A to System B once. Enterprise integration is an ongoing architectural capability - not a project with an end date.
Why Data Silos Form
Silos are the natural result of organizations adopting best-of-breed tools for each function, selected independently rather than as part of a cross-functional data strategy:
- Marketing picks a CRM optimized for pipeline tracking
- Finance implements an ERP built around accounting workflows
- Operations deploys a warehouse management system focused on logistics
Each tool is the right choice in isolation. The problem emerges at the seams.
IBM research found that 77% of organizations agree silos actively hinder real-time analytics and decision-making. The operational symptoms are familiar: inconsistent metric definitions, duplicate customer records, and conflicting inventory figures that no single team owns.
Integration Is Not Just ETL
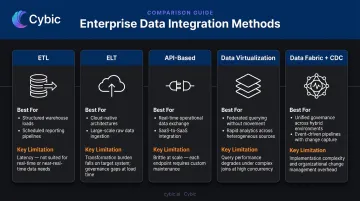
A persistent misconception: data integration equals ETL. ETL is one technique within a broader discipline. Mature enterprise integration strategies employ multiple methods simultaneously, matched to what each use case actually requires:
- Batch ETL - for historical reporting and scheduled data loads
- Real-time CDC (Change Data Capture) - for operational sync where latency matters
- APIs - for connecting SaaS platforms and modern cloud services
Selecting a single method and applying it universally is one of the most common reasons integration programs stall.
Core Data Integration Methods
No single method handles every use case. Below is how each of the five primary approaches works - and where each one breaks down:
ETL (Extract, Transform, Load)
The most established pattern. Data is extracted from source systems, transformed into a target schema, then loaded into a data warehouse.
Best for: Complex transformation requirements, regulatory validation before storage, scheduled batch analytics, strict data quality controls.
Limitation: Pipeline brittleness under frequent schema changes and inherent latency from batch scheduling.
ELT (Extract, Load, Transform)
ELT reverses the sequence - raw data lands in a cloud data warehouse first, then transformations run in place using the warehouse's own compute. As TDWI's cloud ELT research notes, this shift moves transformation workloads to the cloud for greater scalability and elasticity.
Best for: Cloud-native analytics, analyst empowerment via SQL, faster time-to-value on new data sources.
Risk: Raw data quality issues propagate downstream if validation checks aren't enforced at landing.
API-Based Integration
REST APIs and webhooks enable real-time, bidirectional data exchange - essential for SaaS platforms like CRMs and marketing tools that don't expose direct database access.
Best for: Real-time SaaS connectivity, event-driven workflows, operational data exchange.
Tradeoffs: Rate limits, API versioning changes, and dependency on source system webhook reliability.
Data Virtualization
Creates a logical abstraction layer that queries source systems on demand without physically moving data. Particularly valuable where data residency or privacy regulations restrict replication.
Best for: Compliance-sensitive environments, federated queries across regulated data sources.
Limitation: Performance degrades when used against high-traffic transactional systems.
Data Fabric and CDC
Gartner defines data fabric as a flexible, reusable, AI-augmented integration design concept that uses metadata to connect distributed data across hybrid and multi-cloud environments. It gives organizations with sprawling hybrid and multi-cloud environments a unified layer to manage, discover, and govern data without rebuilding every pipeline from scratch.
Best for: Organizations managing distributed data across hybrid and multi-cloud environments, metadata-driven governance, and AI-augmented integration at scale.
Limitation: Implementation complexity is high - realizing data fabric's full value requires mature metadata management and strong governance foundations already in place.
Change Data Capture (CDC) complements data fabric by streaming incremental changes from operational databases in near real time - ideal for keeping analytical systems synchronized with transactional sources without full data reloads.
Best for: Near-real-time sync between operational and analytical systems, reducing load on source databases.
Tradeoffs: CDC pipelines require careful handling of schema changes in source systems; poorly managed CDC can introduce ordering or duplication issues downstream.
Method Comparison at a Glance
| Method | Best For | Key Limitation |
|---|---|---|
| ETL | Regulated batch analytics, complex transforms | Latency; brittle under schema changes |
| ELT | Cloud-native analytics, SQL-driven teams | Data quality risks if landing validation is weak |
| API-Based | Real-time SaaS connectivity, event-driven flows | Rate limits; versioning instability |
| Data Virtualization | Compliance environments, federated queries | Poor performance against transactional systems |
| Data Fabric + CDC | Hybrid/multi-cloud governance, real-time sync | High implementation complexity |
Building Your Enterprise Data Integration Strategy: 5 Key Pillars
Technology-first thinking is the most common and costly mistake in integration initiatives. The right architecture question isn't which tool to buy - it's which decisions this data needs to support. Architecture follows from business requirements, not the other way around.
Pillar 1: Start with Business Outcomes
Before evaluating any platform or method, define:
- What business decisions will integrated data enable?
- Which processes become faster, cheaper, or more accurate?
- What customer or operational experiences improve?
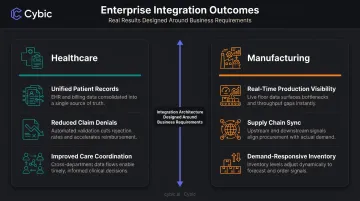
Concrete examples: a healthcare organization needs unified patient records across EHR and billing systems to reduce claim denials and improve care coordination. A manufacturer needs real-time production and supply chain visibility to respond to demand shifts without excess inventory. The integration architecture is designed around these requirements, not ahead of them.
Pillar 2: Audit Your Current Data Landscape
Map what exists before designing what's next. A data landscape audit should capture:
- All active data sources, formats, and ownership
- Update frequencies and data freshness requirements
- Sensitive or regulated data classifications (PII, PHI, financial)
- Where the most painful silos are creating measurable business friction
This surfaces a prioritized roadmap rather than a sprawling wishlist. Cybic structures data assessment engagements around this sequence: current-state landscape review, gap identification, and strategic roadmap development before any architecture decisions are made.
Pillar 3: Select the Right Architecture for Each Use Case
A simple decision framework:
| Latency Requirement | Recommended Approach |
|---|---|
| Sub-second operational sync | CDC or streaming |
| Minutes / near real-time | Micro-batch ELT |
| Daily / periodic reporting | Batch ETL |
| Compliance-restricted data movement | Data virtualization |
| Multi-cloud hybrid landscape | Data fabric |
No organization needs one method. Most need three or four, deployed purposefully.
Pillar 4: Embed Governance from Day One
Governance retrofitted after pipelines are built produces security gaps, compliance failures, and data quality degradation that costs far more to fix than to prevent. Define role-based access policies, classify sensitive data, and establish audit logging requirements before the first pipeline is designed. Waiting until an audit finding forces the issue is a predictable and avoidable outcome.
Pillar 5: Design for Scalability and Continuous Improvement
Integration is not a project with an end date. Data volumes, source systems, and business requirements evolve continuously. Build for this by:
- Using modular, reusable integration components rather than hardcoded point-to-point connections
- Preferring cloud-native, infrastructure-agnostic architectures (AWS, Azure, GCP)
- Establishing KPIs for pipeline freshness, data quality scores, and business impact
- Running quarterly reviews to retire stale pipelines and add new sources systematically
Why Data Governance Must Be Built Into Your Integration Architecture
Gartner estimates poor data quality costs organizations at least $12.9 million per year on average. That figure represents the downstream cost of governance treated as an afterthought : duplicate records, misrouted pipelines, compliance remediation, and decisions made on corrupted data.
The Core Governance Requirements
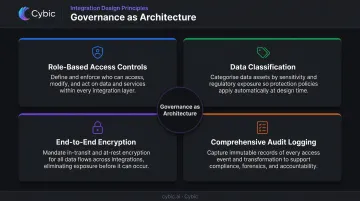
Every integration architecture needs these four components addressed at design time:
- Role-based access controls (RBAC): Enforce least-privilege principles so each business unit accesses only what it needs. This isn't just a security measure ; it prevents accidental data corruption from write access granted too broadly.
- Data classification: Identify PII, PHI, and commercially sensitive fields before pipelines are designed. Sensitive data requires different handling, encryption standards, and access policies than operational metrics.
- End-to-end encryption: Data in transit and at rest must be encrypted - both internal pipelines and cloud-to-cloud transfers.
- Comprehensive audit logging: Every data access event and pipeline execution should be logged with sufficient detail to reconstruct what happened, when, and by whom.
Data Quality Governance
Disconnected source systems routinely generate conflicting records. A customer might be listed three different ways across CRM, ERP, and billing , each with a different address and purchase history. Integration pipelines must apply standardized schemas, transformation rules, and validation checks so data quality is enforced by default rather than fixed in periodic cleanup cycles.
Master Data Management (MDM) handles this for critical shared entities : customers, products, locations. Without MDM, integrated data still produces contradictory answers to basic questions like "how many active customers do we have?"
Regulated Industries Face Higher Stakes
Organizations in healthcare, financial services, and the public sector carry additional compliance requirements that directly shape how integration pipelines must be designed:
- HIPAA: Requires audit controls and six-year documentation retention for ePHI
- SOC 2: Covers security, availability, and confidentiality controls across systems handling customer data
- GDPR: Mandates data portability rights, transfer restrictions, and the right to erasure - each of which constrains how pipelines store and move data
Gartner predicts that by 2027, 60% of organizations will fail to realize anticipated AI use-case value specifically because of incohesive data governance frameworks. Integration architecture that ignores governance doesn't just create compliance risk ; it actively undermines the AI investments built on top of it.
This is why Cybic embeds governance at the architectural level - RBAC, encrypted data protection, audit trails, and data lineage tracking are structural decisions, not add-ons. Organizations that treat governance as a design constraint rather than a compliance checkbox protect both their data quality and the AI systems that depend on it.
Common Enterprise Data Integration Challenges
Managing Integration Complexity at Scale
As enterprises grow, point-to-point integrations multiply into a fragile web that becomes nearly impossible to monitor or extend. Adding a new data source means touching every existing connection that needs its data.
One structural fix: a hub-and-spoke architecture where all systems connect through a central integration layer. New sources plug into the hub once, and every downstream consumer benefits without custom connection work.
Handling Legacy System Integration
Many enterprises run critical workflows on mainframes, aging ERPs, or custom databases built decades before modern APIs existed. The practical approaches:
- Integration middleware with adapters for legacy protocols
- API gateways that expose legacy systems through modern REST interfaces
- Database replication technologies for near-real-time synchronization
The right approach depends on the system's strategic importance and its modernization roadmap. A mainframe running core transaction processing needs a different strategy than a deprecated CRM being phased out over 18 months.
Balancing Real-Time vs. Batch Integration
Not all data needs to be real-time. Treating it as such inflates infrastructure costs and operational complexity without delivering proportional value.
Reserve real-time integration (CDC, streaming) for use cases where latency directly affects outcomes:
- Fraud detection - stale data means missed signals
- Inventory management - real-time stock visibility prevents overselling
- Patient monitoring - delays carry clinical risk
Batch or micro-batch ELT works well for historical analytics, regulatory reporting, and dashboards where hourly or daily freshness is sufficient.
Data Integration as the Foundation for Enterprise AI
AI models are only as reliable as the data they operate on. Fragmented, inconsistent, or ungoverned data produces unreliable outputs - flawed recommendations, biased predictions, and compliance violations that are expensive to defend. And Gartner's prediction is a direct warning: 60% of organizations will fail to realize AI use-case value by 2027 due to governance gaps.
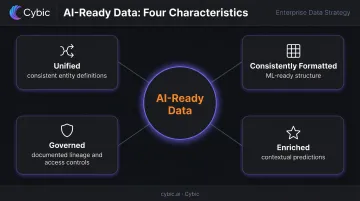
What "AI-Ready" Data Looks Like
IBM defines AI-ready data as high-quality, accessible, trusted information that enterprises can confidently use for AI training and use. In practice, that means:
- Unified across source systems with consistent entity definitions
- Formatted consistently so ML models don't require manual preparation per use case
- Governed with documented lineage and access controls
- Enriched with context that makes predictions actionable, not just statistically interesting
From Reporting to Operational Intelligence
The shift from reactive reporting to proactive AI-driven decisions depends entirely on this foundation:
- Predictive maintenance in manufacturing: Requires real-time sensor data integrated with maintenance history and equipment specs - data that typically lives across three or four separate operational systems.
- Demand forecasting in retail: Requires unified sales history, inventory positions, pricing data, and external signals like seasonality or market trends.
- Clinical decision support in healthcare: Requires integrated EHR data, lab results, and billing history - with strict PHI governance controls on every pipeline.
None of these work on fragmented data. Each one requires the integration architecture described throughout this guide.
Cybic's Drava platform addresses this directly: it connects enterprise data, machine learning, AI reasoning, and intelligent agents into a unified operational system, with RBAC, encryption, audit trails, and regulatory compliance (SOC 2, HIPAA, GDPR) built into the architecture from day one.
For regulated industries, one governance detail stands out. Drava enforces a strict policy against training models on proprietary enterprise data - a non-negotiable requirement in healthcare, financial services, and government environments where data confidentiality is a legal obligation, not a preference.
Without this layer in place, even the most capable AI models operate on unstable ground - producing outputs that can't be trusted, audited, or scaled.
Frequently Asked Questions
What is enterprise data integration?
Enterprise data integration connects an organization's disparate systems - CRMs, ERPs, cloud platforms, and legacy databases - into a unified, consistent data environment. This enables reliable reporting, automation, and AI-driven decision-making across the enterprise rather than within individual silos.
What are the 5 steps of the ETL process?
The five steps are:
- Identify and connect to data sources
- Extract raw data
- Transform data by cleansing, standardizing, and applying business rules
- Load into the target data warehouse or database
- Validate and monitor the loaded data for quality and completeness
What are the 4 types of system integration?
The four commonly cited types are:
- Point-to-point - direct system-to-system connections
- Hub-and-spoke - all systems connect through a central layer
- Enterprise service bus - a shared messaging layer routes data between systems
- API-led - systems communicate through standardized APIs managed by a gateway
What is the difference between a data lake and a data warehouse?
A data warehouse stores structured, pre-transformed data optimized for analytics and reporting. A data lake stores raw, unstructured, and semi-structured data at scale - requiring transformation before it can be used for analytics, ML, or AI workloads.
Why is data governance important in enterprise data integration?
Without governance, integration pipelines expose sensitive data to unauthorized users, propagate poor-quality data across systems, and create compliance violations. Governance is a prerequisite for integration pipelines that are trustworthy, secure, and audit-ready - not an optional layer added after deployment.
How does data integration support AI and machine learning?
AI models require clean, accessible data to produce reliable outputs. Enterprise data integration builds the unified, governed foundation that allows ML models and AI agents to operate on trustworthy data - without manual preparation for every new use case.