
Introduction
Most enterprise data teams don't have a data problem - they have a fragmentation problem. CRM data lives in Salesforce, operational records in SAP, sensor streams in proprietary IoT platforms, and customer analytics in a warehouse that's three major versions behind. Consolidating all of it into something queryable, governed, and scalable is where traditional on-premises warehouses consistently fall short.
The global DBMS market grew 13.4% in 2024 to $119.7 billion, with cloud database platforms capturing the majority of gains - cloud DBMS now represents 64% of spending versus 36% on-premises. At this point, cloud-first data infrastructure is the default, not the exception.
This guide covers what Snowflake actually is (and what it isn't), how its three-layer architecture works in practice, and which industries are getting measurable value from it. It also covers where it falls short - so you finish with a clear framework for evaluating whether Snowflake fits your organization's data strategy.
TLDR
- Snowflake is a fully managed, cloud-native data platform - not ETL, not a database in the traditional sense
- Its separated storage and compute architecture prevents workload contention across teams
- Available on AWS, Azure, and Google Cloud - no vendor lock-in required
- Cost governance is the most common adoption failure point, not the technology itself
- Strong fit for multi-source analytics; poor fit for OLTP or organizations with strict on-prem data residency requirements
What Is the Snowflake Data Platform?
Snowflake started as a cloud data warehouse. It's now more accurate to describe it as a managed data and AI platform - one that handles structured tables, semi-structured formats (JSON, Avro, Parquet, XML), and the compute required to query all of it, without any hardware to provision or patches to apply.
The platform runs as a fully managed service across Amazon Web Services, Microsoft Azure, and Google Cloud. You pick your cloud provider and region; Snowflake handles everything underneath.
What Snowflake Is Not
A common source of confusion: Snowflake is not an ETL tool. It's the destination where ETL pipelines deliver data. It can participate in the load stage through Snowpipe or COPY INTO commands, but pipeline orchestration depends on external tools - Fivetran, dbt, Airflow, and similar. Snowflake stores and processes the data; something else moves it there.
Scope matters here. Snowflake positions itself as an AI Data Cloud supporting data engineering, analytics, applications, and AI workloads. That positioning holds - with two clear boundaries: it doesn't replace purpose-built ML platforms for deep data science work, and it isn't designed for high-frequency transactional processing the way operational databases are.
Multi-Cloud Without Lock-In
One architectural decision that matters for enterprise buyers: Snowflake accounts are hosted on a single cloud provider, but Snowflake's cross-cloud capabilities (Snowgrid) allow data sharing and replication across providers. For organizations running workloads on multiple clouds - 79% of cloud buyers used multiple providers in Q3 2024 according to IDC - this reduces the risk of building your data backbone inside a single provider's ecosystem.
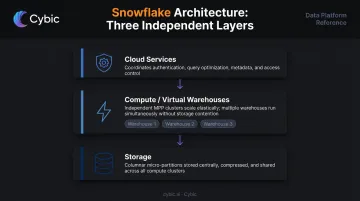
How Snowflake's Three-Layer Architecture Works
The architecture is what separates Snowflake from legacy warehouses. Three independent layers, each scalable on its own terms.
The Storage Layer
Data loaded into Snowflake is automatically reorganized into compressed, columnar micro-partitions. You don't manage indexes, partition schemes, or physical file layouts - Snowflake handles optimization, statistics tracking, and pruning automatically. Teams used to hand-tuning Oracle or Teradata often find this the biggest adjustment: the physical storage layer is mostly invisible.
The Compute Layer (Virtual Warehouses)
This is where queries actually run. Virtual warehouses are independent MPP clusters, each with its own compute resources shared with no other warehouse. The practical implication: your data science team running multi-hour transformation jobs won't slow down the finance team's BI dashboards.
Three warehouse configurations cover different concurrency needs:
| Warehouse Type | Best For |
|---|---|
| Standard | Ad-hoc queries, general analytics |
| Multi-cluster | High concurrency, peak demand fluctuations |
| Isolated per-team | Departmental chargebacks, SLA separation |
Multi-cluster warehouses handle concurrency by automatically starting or stopping additional clusters based on load - useful when you can't predict how many users will hit a dashboard simultaneously.
The Cloud Services Layer
This is Snowflake's coordination layer. Authentication, query optimization, metadata management, access control, and transaction handling all live here. It's what makes Snowflake self-managing. Most infrastructure administration burden, the kind that requires a full-time DBA team on legacy systems, shifts here and becomes platform-managed.
Why Separation of Storage and Compute Matters
Traditional warehouse hardware forces you to overprovision for peak load. You pay for the hardware whether it's running or idle. Snowflake flips this: scale compute up when demand spikes, scale it back when demand drops, or pause it entirely.
Storage costs are separate and continuous; compute costs are consumption-based. That distinction matters in practice - without deliberate configuration (auto-suspend settings, warehouse sizing policies), consumption-based pricing can generate surprises. Cost control here is an operational discipline, not a licensing negotiation.
Key Features That Set Snowflake Apart
Three capabilities explain why enterprises keep choosing Snowflake over alternatives: zero-copy data sharing, native handling of semi-structured formats, and compliance controls built into the platform itself.
Secure Data Sharing
Snowflake lets organizations share live tables, views, and user-defined functions with other Snowflake accounts without physically copying the data. The consumer account stores nothing; they query the provider's data objects directly. This matters for partner data exchanges, regulatory reporting to external bodies, or product teams sharing data with customers as a service.
Native Semi-Structured Data Support
Snowflake's VARIANT data type stores JSON, XML, Avro, ORC, and Parquet natively, with no schema pre-definition required. Teams can ingest event logs, API payloads, or IoT streams and query them with standard SQL alongside structured tables. This removes the need for a separate document database to handle flexible-format data.
Security and Compliance Controls
Snowflake's security model covers:
- Encryption: Data at rest is encrypted and data in transit uses TLS. Key lengths vary by configuration and edition, so verify specifics against your compliance requirements before assuming a single standard applies
- Access control: Combines RBAC, DAC, and UBAC - privileges are assigned to roles, roles to users
- Authentication: SSO via third-party identity providers, MFA required for all human password users under current defaults
- Compliance certifications: SOC 2 Type II, HIPAA/HITRUST (Business Critical Edition required, with a signed BAA before any PHI is stored), PCI-DSS, FedRAMP High, and GxP compatibility
For regulated industries, this matters at the architecture stage, not after deployment. Cybic's Snowflake engagements embed RBAC, audit trails, and compliance controls from day one - so healthcare, financial services, and public sector clients meet their obligations without retrofitting governance onto a live system.
Snowflake Use Cases Across Industries
Energy and Manufacturing
Devon Energy, working with Whitson, used Snowflake to automate bottomhole pressure calculations for 5,000+ wells daily while making 95% of application data available to employees. The core challenge was consolidating sensor data, operational records, and engineering data from disparate systems into a single queryable environment.
For manufacturing and energy clients, Snowflake's ability to handle semi-structured IoT data streams alongside structured operational records in the same platform - without duplicating data into separate systems - is the core technical advantage.
Healthcare and Life Sciences
NYC Health + Hospitals centralized 100 billion+ rows of healthcare data on Snowflake, reducing membership data delivery times from five days to five minutes. MarketScan by Merative reported 10x faster access to real-world life sciences data alongside up to 60% savings in data ingestion and processing costs.

Healthcare deployments have specific requirements before any PHI is stored:
- Requires Business Critical Edition for HIPAA compliance
- Needs a signed Business Associate Agreement (BAA) before going live
- Supports governed data sharing with role-level access controls on specific data objects
Organizations consolidating EHR data, claims records, and clinical trial data tend to get the most value from these governance features.
Financial Services and Retail
Financial services teams use Snowflake for workloads that depend on fast queries across large, multi-source datasets:
- Fraud detection and real-time transaction monitoring
- KYC/AML compliance reporting
- Customer 360 analytics
- Quantitative research pipelines
Retail deployments follow a similar pattern. Demand forecasting models pull together historical sales data, promotional calendars, market trends, and external signals to reduce stockouts and tighten inventory planning.
Named customer evidence for financial services fraud use cases is primarily solution-page based rather than published case studies - keep that in mind when weighing vendor claims in this vertical.
Evaluating Snowflake: Benefits, Limitations, and Fit
Core Benefits
- No infrastructure management: Fully managed - no patching, no capacity planning, no hardware refresh cycles
- Workload isolation: Independent virtual warehouses prevent resource contention across teams
- SQL-native interface: Teams don't need to learn a new query language or retool existing BI workflows
- Cross-cloud flexibility: Runs on AWS, Azure, and Google Cloud - reduces single-provider dependency
- Multi-format data support: Structured, semi-structured, and increasingly unstructured data in one platform
Real Limitations
Cost without governance. G2 reviewers rate Snowflake 4.6/5 from 754 reviews, but cost is the most frequently cited concern - "Expensive" appears in 91 reviews, "Cost Management" in 44. The pricing model charges separately for storage and compute credits, with a 60-second minimum each time a warehouse starts. Warehouses left running between jobs accumulate credits fast.
Mitigation requires deliberate configuration:
- Set auto-suspend defaults on all warehouses
- Use resource monitors with spend alerts
- Assign warehouse ownership with chargeback accountability
- Avoid frequent start-stop cycles for small jobs without cost testing
No on-premises option. Snowflake cannot be deployed on private infrastructure. For organizations with strict data residency requirements or significant sunk costs in existing on-prem warehouse hardware, this is a hard architectural constraint, not a preference.
OLTP is not the use case. Snowflake is optimized for analytical (OLAP) workloads - large-scale reads, aggregations, and transformations. High-frequency transactional processing belongs in a purpose-built OLTP system.
Fit Assessment
Snowflake is well-suited for organizations that:
- Consolidate data from multiple operational sources for analytics
- Run concurrent BI and transformation workloads across multiple teams
- Need cross-cloud flexibility or data sharing with external partners
- Want strong governance and compliance controls at the platform level
It's a weaker fit for organizations that:
- Require on-premises deployment due to regulatory or sovereignty constraints
- Have small data volumes that don't justify managed cloud warehouse costs
- Need real-time, high-frequency transaction processing

The Governance Reality
Snowflake reduces infrastructure burden significantly. It does not eliminate the need for data ownership, access control design, cost accountability, and workload governance. Organizations that treat it as self-running encounter cost overruns and data quality issues within months of deployment.
For enterprise clients in Oil & Gas, Healthcare, and Manufacturing, Cybic builds Snowflake deployments with governance built in from the start, not bolted on afterward. That means:
- RBAC structures and audit logging configured at deployment
- Warehouse cost controls and spend alerts set before go-live
- AI pipeline architecture integrated as part of the core system design
Frequently Asked Questions
Is Snowflake used for data warehousing?
Yes - data warehousing is Snowflake's foundational function. It stores and organizes large volumes of structured and semi-structured data from multiple sources for analytics and BI workloads. Its cloud-native architecture makes it a direct modern alternative to traditional on-premises warehouse hardware.
Is Snowflake a database or ETL tool?
Snowflake is a cloud-native data warehouse - the destination where ETL/ELT pipelines deliver transformed data, not the tool that moves it. Native ingestion options (Snowpipe, COPY INTO) handle data loading, but orchestration requires external tools like dbt, Fivetran, or Airflow.
What cloud platform does Snowflake run on?
Snowflake runs on all three major cloud providers - AWS, Microsoft Azure, and Google Cloud Platform. Organizations choose their preferred provider at account setup, and cross-cloud data sharing is available through Snowflake's Snowgrid capabilities.
What are the main limitations of Snowflake?
The main limitations: no on-premises deployment option, pricing that can escalate without proper cost governance, and an architecture built for analytical (OLAP) workloads rather than high-frequency transactional (OLTP) processing.
How does Snowflake pricing work?
Snowflake charges separately for storage and compute. Compute is billed in credits based on virtual warehouse usage, with a 60-second minimum per start. Configuring auto-suspend keeps warehouses from running idle and is the most direct way to control costs.
How does Snowflake compare to Databricks or Amazon Redshift?
Snowflake is optimized for SQL-based analytics and governed data sharing with minimal infrastructure management. Databricks is stronger for data science, ML engineering, and lakehouse workflows. Redshift is tightly integrated with the AWS ecosystem and suits teams already invested there. The right choice depends on workload type, cloud preference, and team skill set.


