
Introduction
Teradata to Snowflake migration moves an enterprise's data warehouse workloads, objects, pipelines, and reporting layers from an on-premises Teradata environment to Snowflake's cloud-native platform - a scope that touches architecture, data engineering, and every team that depends on analytics.
Legacy Teradata environments are under real pressure right now. Fixed on-prem architecture was built for a world of predictable batch workloads and steady-state hardware cycles - not elastic compute demands, GenAI pipelines, or concurrent user spikes. According to Gartner's 2024 DBMS market data, cloud DBMS spend now represents 64% of the worldwide market, up from a much smaller share just a few years ago.
This guide covers the full migration process: what it involves architecturally, why enterprises are making the move, how the phases work in practice, and what technical challenges to anticipate before they surface mid-project.
Key Takeaways
- Teradata's tightly-coupled MPP architecture must be re-mapped to Snowflake's decoupled storage-compute model before any migration work begins
- Migration spans assessment, environment setup, code conversion, data transfer, pipeline migration, validation, and cutover
- Key technical challenges: SQL dialect gaps, data type mismatches, BTEQ conversion, and behaviors that produce silent data errors
- Lift-and-shift vs. modernization must be decided upfront - mid-project strategy changes are a leading cause of overruns
- Continuous testing and early business user involvement - not final-stage validation - separate successful migrations from derailed ones
What Is Teradata to Snowflake Migration?
Teradata to Snowflake migration is the structured process of replicating and converting Teradata's database objects - tables, views, stored procedures, macros - along with ETL pipelines and BI layers, into their Snowflake equivalents. The end state is a fully operational cloud data warehouse that handles the same workloads the legacy system did, ideally better.
The Core Architectural Difference
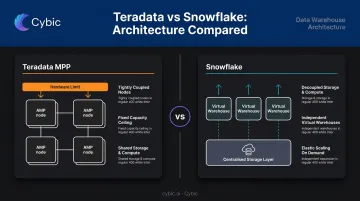
Teradata uses a Massively Parallel Processing (MPP) architecture where storage and compute are tightly coupled across Access Module Processors (AMPs). Every query distributes across those AMPs, and capacity is constrained by the physical nodes installed. Adding compute means adding hardware and redistributing data.
Snowflake separates storage and compute entirely. Virtual warehouses spin up on demand, scale independently, and can run concurrently without contending for the same resources.
That gap is what makes migration non-trivial. Many Teradata design decisions - primary index definitions, query optimization patterns, BTEQ scheduling - exist specifically to work around coupled storage-compute constraints, and those decisions don't carry over cleanly.
Lift-and-Shift vs. Modernization
Not every migration looks the same. Two common approaches:
- Lift-and-shift - Replicate Teradata objects in Snowflake with minimal changes. Faster to execute, lower risk, but carries forward legacy inefficiencies
- Modernization - Use migration as an opportunity to shift from ETL to ELT patterns, redesign pipelines for Snowflake's micro-partition architecture, and clean up 10-20 years of accumulated technical debt
The decision between these two paths has to be made before scoping begins. Teams that start with lift-and-shift estimates and then attempt redesign mid-execution are the ones that blow timelines.
Why Enterprises Are Moving from Teradata to Snowflake
Infrastructure and Cost Constraints
Teradata's fixed node architecture requires expensive hardware refresh cycles. Scaling means adding physical nodes, redistributing data, and absorbing the operational disruption that comes with it. For enterprises with volatile or seasonal workloads, that model creates chronic over-provisioning or under-provisioning - neither is acceptable.
The cost model compounds this. Teradata runs on CapEx: hardware, licensing, DBA overhead, and manual tuning time. Snowflake shifts to consumption-based pricing, where you pay for what you use. Forrester's 2024 Total Economic Impact study for Snowflake found a composite 354% ROI, $19.45M NPV, and payback in under 6 months across four Snowflake customers - with infrastructure and management cost reductions exceeding $5.6M over three years.
AI and Concurrent Workload Demands
Teradata's batch-oriented architecture wasn't designed for what enterprises need now: GenAI pipelines, Snowpark-based ML feature engineering, Snowflake Cortex LLM functions, and real-time analytics running alongside heavy batch jobs.
Snowflake's 2025 GenAI ROI research found that 81% of early GenAI adopters plan to significantly increase cloud data warehouse investment over the next 12 months, and 88% say they need data strategies spanning GenAI use cases. Enterprises building AI-ready data infrastructure - whether using Snowflake-native tooling or deploying AI platforms on top of Snowflake - need a foundation that can handle structured and unstructured data under one architecture.
The concurrency numbers are just as telling: phData's case study with a Pharmacy Benefits Manager serving 27M+ members found that large queries ran 91% faster on a Medium Snowflake warehouse and 97% faster on an XL warehouse. Teradata failed the majority of queries at 20 concurrent users. Snowflake completed 518 queries from 50 concurrent users with zero failures.

New Data Business Models
Snowflake enables data sharing and monetization patterns that are architecturally impossible on legacy on-prem platforms:
- Data Marketplace - publish or subscribe to live data products without moving underlying data
- Snowflake Native Apps - build and distribute data applications directly within the platform
- Governed cross-organization data sharing - share data securely across business units or external partners with full access controls
For healthcare, financial services, and retail enterprises, this opens revenue streams and partnership models that on-prem architecture simply can't support.
How the Teradata to Snowflake Migration Process Works
Snowflake's official migration framework defines nine phases: planning, environment setup, code conversion, data migration, ingestion migration, reporting migration, validation and testing, deployment, and optimize and run.
In practice, Cybic's data warehouse modernization engagements consolidate these into five structured stages - Discovery, Goal Setting, Migration Planning, Design & Development, and Execution - with the technical work concentrated in the final two.
Here's how the critical phases work:
Phase 1: Assessment and Planning
This is the most underestimated phase. Skipping or rushing it is the leading cause of mid-project derailment.
What needs to happen:
- Inventory all database objects: tables, views, stored procedures, macros, BTEQs
- Catalog all ETL jobs and identify their source-to-target lineage
- Document BI reports and their underlying query dependencies
- Flag orphaned objects - tables and jobs that haven't been used in 12+ months are common in mature Teradata environments
- Define the migration strategy (lift-and-shift or modernization) and estimate scope accordingly
Organizations targeting post-migration AI capabilities - Snowpark pipelines, Cortex LLM functions, or enterprise AI platforms - should document those use cases here. The architecture decisions made in Phase 1 either enable or constrain what's possible afterward.
Phase 2: Environment Setup and Security
Snowflake's security model is structurally different from Teradata's, and this phase is an opportunity to clean up access hierarchies that have accumulated over years.
Four areas to address in this phase:
- Define production and development account structures
- Implement network policies, MFA, and SSO
- Replicate the legacy RBAC model in Snowflake - and rationalize it at the same time
- Configure cost tagging tied to virtual warehouses for consumption visibility
Phase 3: Database Code Conversion
Converting Teradata DDL, DML, stored procedures, and BTEQ scripts to Snowflake SQL is where the technical complexity concentrates.
The most common translation issues to plan for:
- Primary index definitions have no direct Snowflake equivalent - handled via clustering keys
- Macros are replaced by stored procedures or views
- QUALIFY clauses require rewriting as subqueries in standard SQL, though Snowflake does support QUALIFY natively
- COLLECT STATISTICS is automatic in Snowflake - no manual equivalent needed
- Join indexes are converted to Snowflake Dynamic Tables, requiring TARGET_LAG and WAREHOUSE parameters
SnowConvert AI is the standard tool for automating this conversion. It handles Teradata SQL, BTEQ, FastLoad, MultiLoad, TPump, and TPT files, translating stored procedures into JavaScript and BTEQ into Python scripts. Automated conversion covers the majority of objects; complex business logic requires human review before sign-off.
With code conversion complete, the focus shifts to moving the actual data.
Phase 4: Data Migration and Ingestion
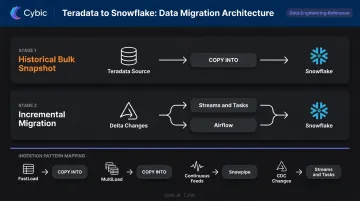
Data migration runs in two stages:
- Historical bulk snapshot - Point-in-time extraction from Teradata, loaded into Snowflake via COPY INTO without transformation
- Incremental migration - Capturing and applying new/changed data through Snowflake Streams & Tasks or external orchestrators like Airflow
The ingestion pipeline migration redirects source feeds from Teradata patterns (FastLoad, MultiLoad) to Snowflake patterns (COPY INTO for bulk loads, Snowpipe for continuous file ingestion, Streams & Tasks for CDC-style change tracking).
Phase 5: Validation, Testing, and Deployment
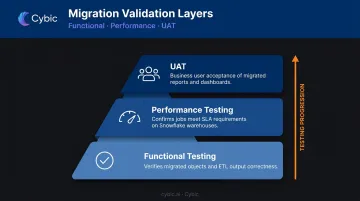
Three testing layers are required before cutover:
| Layer | What It Tests |
|---|---|
| Functional testing | Do migrated objects and ETL jobs produce correct output? |
| Performance testing | Do jobs meet SLA requirements on Snowflake warehouses? |
| UAT | Do business users accept migrated reports and dashboards? |
For phased migrations, a bridging table strategy is used: tables are synchronized from Teradata to Snowflake daily so migrated applications don't block on unmigrated dependencies.
The cutover checklist should include: stakeholder sign-offs, surrogate key synchronization, licensing deadline alignment, and formal system-of-record handover documentation.
Key Technical Challenges to Anticipate
SQL Dialect and Behavioral Differences
The most dangerous issues are the ones that don't throw errors - they just produce wrong results silently.
- ANSI vs. TERA session mode: TERA mode defaults to NOT CASESPECIFIC string comparisons; Snowflake defaults to case-sensitive. TERA-mode workloads need explicit conversion logic
- NULL sort ordering: Snowflake's default NULL positioning differs from Teradata's - ORDER BY results may vary
- Integer division: Teradata rounds after calculation steps based on data type; Snowflake maintains full precision. SnowConvert may insert TRUNC to preserve Teradata behavior
- UNION ALL truncation: Teradata truncates values when the first SELECT has less column space; Snowflake does not ; LEFT() may be needed
Data Type Mapping Reference
Silent type mismatches are a leading cause of data integrity failures post-migration.
| Teradata Type | Snowflake Type | Key Caveat |
|---|---|---|
| BYTEINT | NUMBER(38,0) | Maps via BYTEINT alias |
| CLOB | VARCHAR | 16 MB limit |
| BLOB | BINARY | 8 MB limit |
| TIMESTAMP WITH TIME ZONE | TIMESTAMP_TZ | Generally maps cleanly |
| PERIOD types | VARCHAR | Stored as strings - no native equivalent |
| INTERVAL types | VARCHAR(20) | Date arithmetic must be rewritten as DATEDIFF or interval constants |
Performance Tuning Is Not Automatic
Most queries run faster on Snowflake. Some don't , particularly those that relied on primary index optimization for selective row access. Triage performance issues during system integration testing and parallel runs using this priority framework:
- Fix SLA-breaking queries and anything producing wrong results before cutover
- Defer queries that are slower but within acceptable range to the post-migration hardening phase
- Flag queries requiring investigation (unexpected plan changes, missing statistics) for a dedicated review sprint

Inflight Changes and Technical Debt
Schema and logic changes applied to Teradata during a live migration must be mirrored to Snowflake simultaneously. Without tight coordination, the two environments drift apart. The practical solution is freezing (or formally governing) DDL changes during the migration window with a documented change-control process.
The deeper problem is technical debt - and it's the most common source of scope creep. Common forms include:
- Undocumented tables and views with no known owners
- Orphan ETL jobs still running against decommissioned logic
- Stored procedures untouched for years with no lineage documentation
- Objects referenced in code that no longer exist in the source schema
The assessment phase exists specifically to surface this debt before it becomes a mid-project surprise.
Common Migration Mistakes and Best Practices
Mistake 1: Choosing the Wrong Strategy Mid-Project
Teams scope for lift-and-shift, then attempt redesign during execution. Timelines collapse.
Best practice: Commit to one approach before work begins. If modernization is the goal - particularly when post-migration AI workloads are planned - resource and plan it from day one, not after cutover.
Mistake 2: Engaging Business Users Too Late
Business users first encounter platform differences - report variances, changed query behavior - during UAT, with no context and no time to adapt.
Best practice: Pull UAT users in during Phase 1:
- Collect their critical queries early
- Convert those queries during the migration phase
- Run parallel training alongside technical work
Mistake 3: Treating Validation as a Final Checkbox
Errors introduced early compound across phases. A discrepancy in the conversion phase that surfaces during UAT is a far bigger problem than one caught in functional testing.
Best practice: Validate in layers:
- Schema alignment first
- Row count checks next
- Value-level data diff across critical tables last
Track defects in a structured system and report status to stakeholders throughout - not just at the end.
Frequently Asked Questions
What is Teradata migration?
Teradata migration is the process of moving data, database objects, ETL pipelines, and reporting workloads from a Teradata data warehouse to another platform (in this context, Snowflake's cloud-native environment). It is driven by cost pressures, scalability requirements, or the need to support AI and real-time workloads on modern infrastructure.
Why is Snowflake better than Teradata?
Snowflake's decoupled storage and compute architecture enables on-demand scaling without hardware constraints, supports AI and ML workloads natively via Snowpark and Cortex, and shifts costs from CapEx to consumption-based pricing. For concurrent, elastic, or AI-adjacent workloads, the architectural fit is strong - but the right choice always depends on your specific workload profile.
How long does a Teradata to Snowflake migration typically take?
Timelines vary widely based on data volume, object count, and technical complexity. Snowflake's own migration resources cite examples like Micron migrating 5,000 tables and 5 TB in under four months. Larger or more complex environments take longer. The single biggest factor in staying on schedule is the quality of the Phase 1 assessment.
Should we do a lift-and-shift or full modernization migration?
Lift-and-shift is faster and lower risk but carries forward legacy inefficiencies. Modernization delivers greater long-term value (especially if AI workloads are planned post-migration) but requires more planning and resourcing. Choose one approach before the project starts - switching mid-execution is the primary driver of cost and timeline overruns.
What is SnowConvert and how does it help?
SnowConvert AI is Snowflake's automated code conversion tool that translates Teradata DDL, DML, stored procedures, BTEQ scripts, and macros into Snowflake-compatible SQL. It reduces manual conversion effort, though human review of complex business logic is still required: SnowConvert handles mechanical translation, not judgment calls about behavioral equivalence.
What are the biggest risks in Teradata to Snowflake migration?
The top risks are SQL behavioral differences causing silent data errors, underestimating technical debt in legacy environments, inadequate testing coverage, and insufficient business user engagement. All are manageable with proper planning, a phased validation strategy, and a committed cutover checklist.


