The numbers confirm the gap. Over 80% of digital healthcare data is unstructured, meaning it lives in physician notes, discharge summaries, and operative reports that machines can't easily read. Despite this, over 70% of US healthcare leaders surveyed by McKinsey in 2024 were already pursuing or implementing generative AI - a clear signal that the industry is betting on a new approach.
This post explains not just that generative AI addresses healthcare interoperability, but specifically how - through four core mechanisms that make it fundamentally different from traditional integration approaches.
Key Takeaways
- Most clinical data is unstructured, EMR vendors use proprietary schemas, and PHI governance limits open integration.
- Gen AI understands language and clinical meaning, not just data fields - enabling it to connect systems never designed to communicate.
- Four mechanisms make this work: unstructured data processing, intelligent format translation, RAG-based retrieval, and agentic workflows.
- HIPAA compliance must be embedded at the architectural level, not bolted on after deployment.
What Is Healthcare Data Interoperability - And Why Does It Stay Broken?
Interoperability, as HIMSS defines it, is the ability of different systems, devices, and applications to access, exchange, integrate, and cooperatively use data across organizational boundaries. But that definition contains an important distinction that gets glossed over in most conversations:
- Syntactic interoperability - data can be transferred between systems
- Semantic interoperability - data is understood and usable in context on the receiving end
Most healthcare organizations have achieved some version of the first. Very few have achieved the second at scale - and none reliably across organizational boundaries.
Why the Problem Persists Despite HL7 and FHIR
Three structural barriers explain why interoperability remains broken despite years of standards adoption:
Unstructured data dominance. The majority of clinically actionable information - notes, summaries, radiology reports - is free-text, not structured data fields that standard formats can simply pick up and move.
Proprietary EMR schemas. EMR vendors build on architectures that create technical and contractual barriers for third-party data access. ONC's 2024 HITECH report found that 72% of hospitals reported challenges exchanging data across different EHR vendor platforms, and 57% cited patient matching as an ongoing difficulty.
PHI governance constraints. The regulatory sensitivity of protected health information limits the kind of open API integrations that are routine in other industries.

The operational result: even organizations with FHIR-compliant systems still receive data that varies in structure, source reliability, and timing. Resolving that requires active interpretation - something transmission standards alone were never designed to provide.
How Generative AI Bridges Healthcare Data Interoperability Gaps
Traditional integration approaches rely on predefined rules and rigid schema mappings - they work when data arrives in expected formats and break when it doesn't. Generative AI brings a different capability: it learns from data to understand language, meaning, and clinical context, functioning as an intelligent translation and interpretation layer between systems that were never designed to talk to each other.
Four mechanisms make this work in practice.
Processing Unstructured Clinical Data at Scale
The majority of clinically actionable information exists as free-text. Physician notes, discharge summaries, operative reports, and patient histories don't arrive as structured fields that downstream systems can ingest - they arrive as prose.
Large language models trained on clinical language can read, interpret, and extract structured information from this text: mapping a physician's note into discrete diagnosis codes, medication records, or procedure logs that downstream systems can use. This eliminates the manual abstraction work that currently requires trained medical coders or HIM specialists, and makes previously inaccessible data visible and usable across systems.
One important qualification: accuracy depends on model specialization. Healthcare language is dense with abbreviations, context-dependent terminology, and domain-specific patterns. Domain-specific or fine-tuned models consistently outperform general-purpose LLMs in clinical text extraction - a key consideration when evaluating solutions.
Intelligent Data Mapping and Format Translation
When data does arrive in structured form, it rarely arrives in the right structure. Different EMRs label the same clinical concept differently. Device manufacturers use proprietary parameter names. Coding systems vary by site.
Gen AI performs semantic data mapping - automatically identifying equivalent fields across different schemas and translating between formats. This includes converting proprietary EMR data into FHIR R4 format, or mapping non-standard device parameters to standardized nomenclatures like SNOMED or LOINC. Unlike rule-based ETL tools, it handles ambiguity and context-dependent field names without breaking.
The benchmark evidence is concrete. A 2025 PMC study found that a sentence-transformer model for OMOP medication concept mapping achieved 96.5% accuracy on the 200 most common drugs, outperforming traditional mapping tools. That's a meaningful proof point - though it's worth noting that medication mapping is narrower than full enterprise semantic normalization.
The policy context makes this capability increasingly non-negotiable. CMS-0057-F, released in January 2024, requires impacted payers to meet new FHIR API requirements primarily by January 1, 2027 - covering Patient Access, Provider Directory, Payer-to-Payer, and Prior Authorization APIs. Automated, scalable format translation is no longer a nice-to-have.
Contextual Retrieval with Retrieval-Augmented Generation (RAG)
RAG combines a generative AI model with the ability to retrieve relevant data from internal systems before generating a response. Rather than relying solely on what it was trained on, the model actively queries EMR records, lab systems, or imaging databases to ground its outputs in real, current patient data.
This directly addresses the interoperability problem. A single AI layer can pull context from multiple disconnected systems - different EMRs, care sites, historical records - and synthesize a coherent, patient-specific response, without requiring those systems to be fully integrated at the database level.
The evidence for hallucination reduction is meaningful. MEGA-RAG, evaluated in a 2025 public health study, reported over 40% hallucination-rate reduction compared to standalone LLM baselines, with 0.7904 F1 performance. Grounding outputs in retrieved records rather than training data alone is the core mechanism.
PHI-laden retrieval workflows should not run through public cloud LLM APIs. Self-hosted or private-cloud RAG deployments keep sensitive data within a governed perimeter and preserve HIPAA eligibility.
Cybic builds governed RAG pipelines on AWS, Azure, and Google Cloud - including hybrid and on-premises environments - with RBAC, encrypted data handling, and audit trails built into the architecture, ensuring data stays within a controlled boundary.
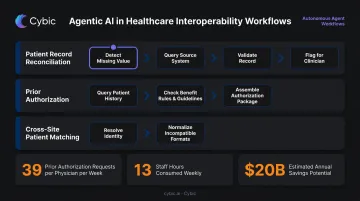
Agentic AI for Multi-Step Interoperability Workflows
Where a single LLM query answers a question, an AI agent executes an entire workflow.
Agentic AI can plan a sequence of steps, choose which data sources or tools to call at each step, evaluate intermediate results, and adapt its approach - all without human intervention at each stage. Applied to healthcare interoperability, this enables workflows like:
- Patient record reconciliation: Identifying a missing lab value, querying the originating system, validating against the patient record, and flagging a discrepancy for clinician review
- Prior authorization processing: Querying patient history, benefit rules, and clinical guidelines in sequence to assemble a complete authorization package
- Cross-site patient matching: Resolving identity across care sites where records exist in incompatible formats
The prior authorization use case illustrates the operational opportunity clearly. Physicians handle an average of 39 prior authorization requests per week, consuming 13 staff hours weekly, according to AMA survey data. CAQH has estimated $20 billion in additional savings available from fully electronic administrative workflows. Agentic AI is where Gen AI moves from a data translation tool to an active participant in administrative operations.
Where Gen AI Interoperability Is Applied Across Healthcare
Clinical Operations
At the point of care, Gen AI surfaces complete patient histories from fragmented records - including data held in external systems the treating clinician has no direct access to. Ambient documentation tools, now deployed across US health systems, depend on this interoperable data foundation to function accurately. Without reliable data retrieval across systems, ambient documentation produces incomplete or contextually incorrect outputs.
Patient matching is a related pressure point. AHIMA has cited research indicating accurate patient matching can be as low as 80% within a single care site - a safety issue, not just an efficiency one. AI-driven identity resolution across fragmented records addresses this directly.
Administrative and Revenue Cycle Workflows
Billing, coding, release of information, and prior authorization all require data to flow accurately between EMRs, payer systems, and administrative platforms built on incompatible architectures. Gen AI addresses the interoperability layer at each step:
- Cross-referencing clinical documentation with coding requirements across systems
- Automating the assembly of prior authorization packages from multiple data sources
- Processing release of information requests that require pulling records from multiple sites
The CMS FY2024 Medicare fee-for-service improper payment rate held at approximately 7.38% - a persistent problem that accurate, AI-assisted data exchange between clinical and billing systems can directly reduce.
Clinical Research and Population Health
Converting heterogeneous clinical data into standardized research formats like OMOP is one of the more labor-intensive tasks in health data management. Gen AI automates the extraction, transformation, and normalization of data from multiple source systems.
One reported OMOP conversion effort facilitated more than 45,000 mapping rules and converted over 5 million patient records, with roughly 75% of mappings generated automatically from recognized vocabularies. At that volume, the difference between manual and automated semantic mapping isn't a process improvement - it's what makes the research pipeline viable at all.
Governing Gen AI in Healthcare: PHI, Compliance, and Security by Design
HIPAA compliance in a Gen AI deployment isn't a policy layer added after the architecture is built. It has to be embedded from the start - the architecture itself should make non-compliance structurally difficult to achieve, not merely discouraged.
Critical Architecture Requirements
Every healthcare Gen AI deployment should include:
- Encryption in transit and at rest for all patient data
- Role-based access controls (RBAC) that limit which AI functions can access which patient records
- Full audit trails of every AI-driven action, queryable for compliance review
- Prohibition on using proprietary patient data to train or fine-tune external models
- Business Associate Agreements (BAAs) with any cloud service provider that creates, receives, maintains, or transmits ePHI - required under HHS guidance

Deployment Model: The Core Tradeoff
| Deployment Model | Speed to Deploy | PHI Risk | HIPAA Suitability |
|---|---|---|---|
| Commercial public LLM APIs | Fast | High - data may leave perimeter | Requires specific BAA + controls |
| Private cloud (AWS/Azure/GCP, isolated) | Moderate | Controlled | HIPAA-eligible with BAA |
| Self-hosted / on-premises | Slower | Lowest | HIPAA-eligible |
For US health systems handling identifiable patient data, the private or self-hosted deployment model is the safer default. Commercial public LLM APIs carry the risk of PHI being transmitted to external servers, potential use of that data in model improvement cycles, and insufficient audit controls for HIPAA compliance.
Cybic's approach to this is infrastructure-agnostic by design - solutions operate across cloud, hybrid, and on-premises environments, with governance controls embedded at the architectural level rather than layered on top.
Compliance isn't a configuration option that can be misconfigured. It's a structural property of how the system is built.
The ONC HTI-1 Final Rule adds another layer: it establishes transparency requirements for AI and predictive algorithms embedded in certified health IT - meaning auditability of AI-driven decisions is now a regulatory expectation, not just a best practice.
Conclusion
Generative AI changes what interoperability can actually achieve. By understanding language and inferring meaning across EHRs, claims systems, and lab platforms that were never standardized together, it enables health systems to bridge data silos without requiring full structural integration at the database level.
Healthcare leaders who understand how these mechanisms actually work - unstructured data processing, semantic mapping, RAG-based retrieval, and agentic workflow orchestration - are better positioned to evaluate solutions critically and ask sharper questions about governance and deployment architecture.
Organizations that deploy Gen AI as a point solution tend to solve one problem while leaving the underlying fragmentation intact. Treating it as an architectural commitment - embedded into data pipelines, access controls, and workflow logic - is what produces durable gains in clinical efficiency and operational data quality.
Frequently Asked Questions
What is the difference between HL7, FHIR, and generative AI in healthcare interoperability?
HL7 and FHIR are data exchange standards - they define the syntax, structure, and format for transferring health information between systems. Generative AI adds semantic understanding: the ability to interpret meaning, handle unstructured free-text, and bridge systems that don't conform to any standard format at all.
Can generative AI reliably process unstructured healthcare data like physician notes?
LLMs fine-tuned on clinical language can extract structured information from free-text with high accuracy for common clinical concepts. Human validation remains important for high-stakes decisions - AI extraction works best as a first-pass layer that surfaces data for clinical review, rather than a fully autonomous system.
Is generative AI HIPAA-compliant for handling patient data?
Compliance depends on deployment architecture. Self-hosted or private-cloud models with encrypted data handling, RBAC, audit trails, and BAAs can meet HIPAA requirements. Commercial public LLM APIs generally cannot - PHI exposure risk requires careful architectural review before any clinical use.
What is RAG and why does it matter for healthcare data interoperability?
RAG (Retrieval-Augmented Generation) allows an AI model to retrieve real-time data from internal systems before generating a response. This grounds outputs in actual patient records rather than training data alone - critical for clinical accuracy and hallucination reduction when querying across fragmented healthcare systems.
What is the difference between traditional API-based EMR integration and AI-driven interoperability?
API integrations require both systems to share a defined schema and structured data. Gen AI-driven approaches can interpret, translate, and normalize data even when systems use incompatible formats or unstructured content - making integration feasible without costly custom development for every system pair.
What are the risks of using commercial LLMs like ChatGPT for healthcare interoperability workflows?
The primary risks are PHI transmission to external servers, potential use of that data in model training, and insufficient audit controls for HIPAA compliance. For clinical environments, self-hosted or governance-embedded private deployments are the required architectural baseline - not an optional upgrade.


