
Introduction
The average enterprise now runs 342 SaaS applications, yet only 3% of IT leaders have complete real-time visibility into their stack. Data sits in CRMs, ERPs, cloud warehouses, and dozens of SaaS tools - siloed, inconsistent, and quietly draining value from every system it touches.
Poor data quality costs organizations an average of $12.9M per year, according to Gartner. But in 2026, the real cost isn't just bad reports - it's missed AI opportunities. Every ML model, AI agent, and automated workflow your organization wants to deploy depends on clean, governed, fresh data moving reliably between systems.
This guide covers 15 data integration tools across ETL, ELT, iPaaS, enterprise, and cloud-native categories. Each tool is evaluated on:
- Connector quality and breadth
- Pricing transparency
- Real-time capability
- Governance and compliance features
- Fit for different team types and stack sizes
Use it to match the right platform to your infrastructure, team, and actual use case.
Key Takeaways
- Data integration tools connect, move, and synchronize data across systems for analytics, automation, and AI.
- ETL transforms before loading; ELT loads raw data first - modern cloud stacks favor ELT.
- Selection should be driven by connector quality, pricing predictability, team ownership, and governance requirements - not a vendor's demo feature list.
- These 15 tools span cloud-native ELT, iPaaS automation, enterprise governance platforms, and developer-first stacks.
- Pick the tool your team can operate, scale, and afford without pipelines turning into a maintenance burden.
What Are Data Integration Tools? ETL, ELT, and Real-Time Explained
Data integration is the process of collecting data from multiple systems, transforming it into a consistent format, and delivering it to a destination for analytics, reporting, AI, or operational use. As organizations deploy AI and ML models that depend on clean, governed pipelines, this has become infrastructure-critical work, not just a back-end concern.
The Three Core Integration Paradigms
| Pattern | How It Works | Best For |
|---|---|---|
| ETL | Transform data before loading into the destination | Legacy warehouses with strict schemas |
| ELT | Load raw data first, transform inside the warehouse | Cloud-native stacks (Snowflake, BigQuery) where compute is cheap and schemas change often |
| CDC (Change Data Capture) | Stream row-level changes as they happen | Fraud detection, live ML models, inventory - when freshness is measured in seconds |
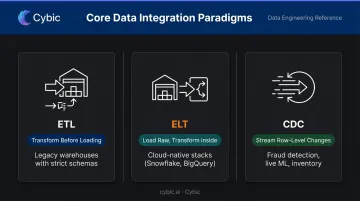
Google BigQuery recommends ELT for most customers because the warehouse itself handles transformation at scale. Snowflake's documentation similarly positions ELT as the standard approach for cloud data integration. If your stack is cloud-first, ELT is almost certainly the right model.
Reverse ETL: Closing the Loop
Reverse ETL pushes cleaned warehouse data back into operational tools - Salesforce, HubSpot, Marketo - so teams act on insights where they already work. In 2026, more teams use this pattern to power AI agents that need current warehouse data to function.
This data-to-action pipeline pattern sits directly upstream of platforms like Cybic's Drava, which connects warehouse data to machine learning, AI reasoning, and intelligent agents for workflow automation.
How to Choose the Right Data Integration Tool in 2026
Start With Your Connectors
Before evaluating any tool, list your exact sources and destinations. There's a real difference between "we support databases" and "we support your specific Salesforce instance, NetSuite, Shopify, and SFTP source with maintained, non-beta connectors."
A 700-connector catalog is meaningless if the three connectors you actually need are in beta. Connector maintainability - how well a tool handles schema drift, API changes, and incremental syncs - predicts your long-term operating cost far better than raw connector count.
Match the Tool to Who Will Own It
This is a people question, not a technical one.
- Data engineers own it? Python/SQL-first tools like Airbyte and AWS Glue unlock more control and flexibility.
- RevOps, analytics, or ops teams own it? No-code interfaces aren't a preference - they're a requirement for sustainable pipeline ownership.
Ask yourself who maintains this six months from now, not who demos it today.
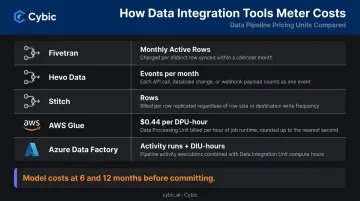
Model Your Pricing at Scale
Volume-based pricing sounds affordable early. It rarely stays that way. Different tools meter costs very differently:
- Fivetran: Monthly Active Rows (MAR)
- Hevo Data: Events per month
- Stitch: Rows
- AWS Glue: DPU-hours ($0.44 per DPU-hour)
- Azure Data Factory: Activity runs + DIU-hours
Model your pricing at 6 and 12 months of expected data growth before committing. Connector-based or workload-based pricing is typically more predictable for budget planning.
Governance Is Non-Negotiable in Regulated Industries
For healthcare (HIPAA), financial services (FTC Safeguards Rule), or energy (NERC CIP), the integration layer needs these controls built in from the start - not added manually as environments scale:
- Role-based access controls
- Audit trails and data lineage
- Encryption in transit and at rest
- Compliance reporting hooks
Tools that lack these features push governance work onto your team - and that gap compounds risk as data volumes and user counts grow.
Real-Time vs. Batch: Resist the Default
Batch integration is reliable, predictable, and sufficient for most reporting and analytics workflows. Real-time CDC adds operational complexity and cost that only pays off when data freshness directly impacts business outcomes - fraud detection, inventory management, live ML inference, and similar latency-sensitive use cases. If your downstream consumers can tolerate a 15-minute delay, batch is almost always the right call.
15 Best Data Integration Tools in 2026
Tools were evaluated on connector breadth and quality, pricing transparency, ease of setup, real-time capability, governance features, and fit across team types. No single tool wins every category.
Category 1: Cloud-Native ELT Leaders
Built for modern data stacks with automated, low-maintenance pipelines into Snowflake, BigQuery, and Redshift. Choose this category if your priority is reliable warehouse ingestion with minimal pipeline maintenance.
Fivetran
A fully managed ELT platform built for reliable, hands-off ingestion - 700+ prebuilt connectors, automatic schema drift handling, and deep warehouse integrations with minimal pipeline maintenance. Named a Challenger in the 2025 Gartner Magic Quadrant for Data Integration Tools.
| Attribute | Detail |
|---|---|
| Best For | Teams with high data volumes who want ELT to be invisible |
| Pricing Model | Monthly Active Rows (MAR) - usage-based, scales with data volume |
| Key Differentiator | Log-based CDC with near-zero source impact and automatic schema migration |
Airbyte
An open-source ELT platform with 600+ replication connectors and a Connector Development Kit for building or modifying connectors. Self-hosted is free; Airbyte Cloud is usage-based with volume and Data Worker pricing tiers.
| Attribute | Detail |
|---|---|
| Best For | Developer teams who want extensibility and no vendor lock-in |
| Pricing Model | Free (self-hosted Core); usage-based on Airbyte Cloud |
| Key Differentiator | Open-source connector ecosystem with transparent, debuggable CDC behavior |
Matillion
A cloud ELT and transformation platform that pushes transformation logic directly into Snowflake, BigQuery, or Redshift. Its visual job builder suits SQL-heavy analytics teams who want precise control over in-database transformation with version control and dependency management.
| Attribute | Detail |
|---|---|
| Best For | Data engineering teams running complex warehouse-centric transformations |
| Pricing Model | Consumption-based credit system - scales with job execution frequency |
| Key Differentiator | Warehouse-pushdown ELT with Git integration built for governed production environments |
Hevo Data
A no-code ELT platform for teams who want near-real-time warehouse ingestion without owning pipeline logic. The free plan includes 1M events/month and 50+ connectors; the Starter plan begins at $239/month for 20M events and 150+ connectors.
| Attribute | Detail |
|---|---|
| Best For | Smaller analytics teams needing reliable SaaS-to-warehouse pipelines with minimal setup |
| Pricing Model | Event-based tiers with a free entry plan |
| Key Differentiator | Automated schema handling and built-in transformations reduce time-to-dashboard |
Stitch (by Qlik)
A lightweight, developer-friendly ELT tool connecting 130+ data sources. Qlik-owned and built for startups and SMBs who need fast, stable ingestion into cloud warehouses. Standard pricing starts at $100/month on a row-based model.
| Attribute | Detail |
|---|---|
| Best For | Startups and SMBs who need fast SaaS-to-warehouse ELT without setup complexity |
| Pricing Model | Row-based; Standard starts at $100/month |
| Key Differentiator | Simple, predictable ingestion with 130+ maintained connectors for common SaaS sources |
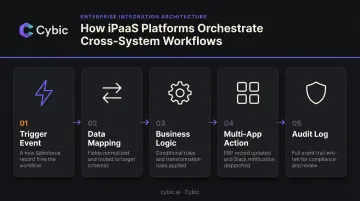
Category 2: iPaaS & Automation Platforms
These tools go beyond data movement to connect applications, automate business workflows, and orchestrate multi-step processes. Choose this category if you need cross-system automation - not just pipeline replication.
Workato
An enterprise automation and integration platform with 1,200+ native connectors. Its low-code recipe builder lets business and IT teams build sophisticated cross-app workflows. Agent Studio builds, deploys, and governs AI agents ("Genies") on top of integrated data. Valued at $5.7B in its 2021 Series E.
| Attribute | Detail |
|---|---|
| Best For | Cross-functional teams building governed automation workflows across SaaS, ERP, and databases |
| Pricing Model | Recipe/Business Action-based |
| Key Differentiator | AI-integrated architecture with Agent Studio for building intelligent automation agents |
SnapLogic
A visual enterprise integration platform with AI-assisted pipeline development via SnapGPT (generative AI copilot) and AgentCreator 3.0 for building AI agents on governed integration pipelines. Demo-led pricing with Business and Enterprise bundles.
| Attribute | Detail |
|---|---|
| Best For | Enterprise teams who want AI-assisted pipeline development with visual governance |
| Pricing Model | Quote-based subscription - contact sales |
| Key Differentiator | SnapGPT integration copilot and AgentCreator for autonomous AI workforce deployment |
Celigo
An iPaaS purpose-built for NetSuite and e-commerce operations, trusted by 5,000+ NetSuite customers. Its prebuilt flows for order management, inventory, fulfillment, billing, and refunds eliminate rebuilding standard business logic from scratch. Flat-rate pricing based on endpoints and flows - not per transaction.
| Attribute | Detail |
|---|---|
| Best For | Ops and finance teams running NetSuite, Salesforce, or Shopify-to-ERP workflows |
| Pricing Model | Endpoint and flow-based - not per task or transaction |
| Key Differentiator | Purpose-built prebuilt flows for order management and finance operations |
Dell Boomi
An enterprise iPaaS serving 30,000+ global customers across cloud-to-on-prem connectivity, EDI, API management, and workflow automation. Best for organizations where legacy systems need to coexist with modern SaaS tools without a full migration.
| Attribute | Detail |
|---|---|
| Best For | IT teams managing hybrid cloud and legacy systems with complex connectivity requirements |
| Pricing Model | Tiered subscription with pay-as-you-go option |
| Key Differentiator | Native B2B and EDI handling alongside broad connector coverage for hybrid environments |
Category 3: Enterprise & Governance-First Platforms
Designed for large organizations where data integration is formal infrastructure. Choose this category when scale, data lineage, compliance, and operational stability outweigh speed of setup.
Informatica
Informatica's Intelligent Data Management Cloud (IDMC) covers ETL, ELT, data quality, governance, master data management, and AI-powered metadata discovery via the CLAIRE AI engine. Named a Leader in the 2025 Gartner Magic Quadrant for Data Integration Tools for the 20th consecutive year.
| Attribute | Detail |
|---|---|
| Best For | Large enterprises with dedicated data teams in regulated industries |
| Pricing Model | Consumption-based via Informatica Processing Units (IPUs) - custom enterprise quotes |
| Key Differentiator | CLAIRE AI engine for automated metadata discovery, lineage, and data quality at enterprise scale |
MuleSoft (Salesforce)
MuleSoft's Anypoint Platform is built around API-led connectivity and serves as Salesforce's integration spine across 150,000+ Salesforce customers. Its DataWeave transformation language and MCP (Model Context Protocol) support make it the standard for enterprises treating integration as shared, reusable API infrastructure - including agentic AI workflows.
| Attribute | Detail |
|---|---|
| Best For | Enterprises building API-first architectures with Salesforce at the center |
| Pricing Model | Flow and traffic-based - custom enterprise quotes |
| Key Differentiator | API lifecycle management with MCP support for agentic AI and enterprise automation |
IBM DataStage
An enterprise ETL platform within IBM Cloud Pak for Data, built around a high-performance parallel processing engine for large, complex batch workloads. Pricing is Capacity Unit-Hour based ($1.75/CUH). Best suited for organizations running IBM infrastructure with legacy mainframes and mission-critical pipelines.
| Attribute | Detail |
|---|---|
| Best For | Large enterprises with IBM stack investments running complex, high-volume batch ETL |
| Pricing Model | Capacity Unit-Hour (CUH) within Cloud Pak for Data - SaaS and on-prem options |
| Key Differentiator | Parallel processing engine for legacy-heavy environments within IBM's broader data ecosystem |
Category 4: Cloud Provider & Developer-First Tools
Best for teams already invested in a specific cloud ecosystem or building code-first pipelines with granular control. If your stack is AWS, Azure, or you need sub-second CDC, start here.
Azure Data Factory
Microsoft's enterprise ETL and data orchestration service, natively integrated with Azure Synapse, Microsoft Purview for lineage, and Logic Apps. The default choice for organizations standardized on Azure who need scalable hybrid pipelines without leaving the Microsoft ecosystem. Pay-as-you-go pricing by pipeline run, activity, and data movement (DIU-hours).
| Attribute | Detail |
|---|---|
| Best For | Enterprises leveraging Microsoft Azure with hybrid on-prem-to-cloud pipeline needs |
| Pricing Model | Pay-as-you-go by activity runs, IR hours, and DIU-hours |
| Key Differentiator | Tight Azure ecosystem - Synapse for analytics, Purview for governance, Integration Runtime for hybrid connectivity |
AWS Glue
AWS's serverless ETL service for data engineering teams comfortable in Python/Spark. Its Data Catalog and crawler-based schema discovery suit teams building data lake pipelines. Pay-as-you-go pricing at $0.44 per DPU-hour. Requires coding proficiency and AWS-native orientation.
| Attribute | Detail |
|---|---|
| Best For | AWS-native data engineering teams building serverless ETL for big data and data lake workloads |
| Pricing Model | Pay-as-you-go - $0.44 per DPU-hour |
| Key Differentiator | Serverless, auto-scaling architecture with built-in Data Catalog for schema discovery and evolution |
Estuary
A real-time data platform built for CDC-first workloads. Estuary captures and delivers row-level changes as they happen, not on a scheduled timer, with exactly-once delivery and support for both streaming and batch in a single pipeline model. Free proof-of-concept deployment available; private/BYOC requires contact.
| Attribute | Detail |
|---|---|
| Best For | Engineering teams running ML features, fraud detection, or operational views where latency directly impacts outcomes |
| Pricing Model | Data-volume-based with a free public deployment tier |
| Key Differentiator | Unified streaming-and-batch pipeline model with sub-second CDC and BYOC deployment |
Key Trends Shaping Data Integration in 2026
AI-Assisted Pipeline Management Is Becoming Standard
Modern platforms now ship with schema drift detection, intelligent field mapping suggestions, and automated anomaly alerts. Workato's Agent Studio, SnapLogic's SnapGPT, and Informatica's CLAIRE engine are all production features - not cosmetic UX additions. As data pipelines increasingly feed AI models and agents, consistent and trusted inputs become requirements, not optional quality improvements.

The practical question isn't whether a platform has AI features. It's whether those features enforce governed execution or just make building pipelines faster.
Data-to-AI Pipelines as Strategic Infrastructure
Data integration is no longer evaluated in isolation. Organizations are choosing platforms that serve as the foundation for AI and ML workloads. Governance, lineage, and real-time freshness are now prerequisites for AI readiness.
Gartner notes that high-quality traditional data is not automatically AI-ready. AI models require representative data: outliers, edge cases, and consistent schema evolution handling are all part of that picture.
For organizations in healthcare, manufacturing, oil and gas, and retail, this distinction matters most. The gap between "data that reports well" and "data that trains and feeds AI reliably" is what separates a data warehouse from an AI-ready data platform - and it's the gap Cybic regularly bridges when connecting integration infrastructure to AI systems in these sectors.
Platform Consolidation Over Point-Solution Sprawl
The fragmentation of separate ETL, orchestration, and transformation tools is pushing organizations toward unified platforms that handle ingestion, transformation, governance, and reverse ETL in one environment. The drivers are practical:
- Fewer vendor relationships to manage and audit
- Simpler, more defensible security perimeters
- Reduced operational overhead across engineering teams
For mid-to-large enterprises running five pipeline tools across two teams, consolidation isn't just efficiency, it's risk reduction.
How We Chose the 15 Best Data Integration Tools
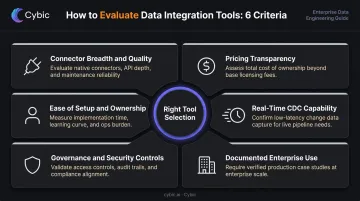
Tools were assessed across six criteria:
- Connector breadth and quality - native vs. beta, schema drift handling, API resilience
- Pricing model transparency - predictability at scale, not just entry-level cost
- Ease of setup and ownership - across different team types, not just engineering
- Real-time or CDC capability - method, latency, and delivery guarantees
- Governance and security controls - RBAC, audit trails, lineage, encryption
- Documented use across enterprise and mid-market environments
Three factors are consistently underweighted by buyers:
- Implementation, maintenance, and engineering time add up - total cost of ownership rarely appears on a pricing page
- A 700-connector catalog means little if your three critical connectors are in beta or break on schema changes - quality matters more than count
- Governance gaps rarely show up in a demo - they appear once the tool is carrying real workloads in a regulated environment
Selecting a tool based on a demo feature list is the most common mistake. The real question is how it performs at three times your current data volume, with the team you actually have.
Conclusion
Choosing a data integration tool in 2026 is a decision about what kind of data operations your organization can realistically sustain.
- Enterprise platforms like Informatica and MuleSoft offer unmatched governance and scale but assume dedicated teams and longer implementation cycles
- Cloud-native ELT tools like Fivetran and Airbyte prioritize low-maintenance speed for modern warehouse stacks
- iPaaS platforms like Workato and SnapLogic extend integration into AI-powered automation and business process orchestration
- Developer-first tools like AWS Glue and Estuary give engineering teams precise control within their cloud ecosystems
Most tool failures come down to fit, not quality. A platform built for a 500-person enterprise with a dedicated data team will underperform in a 20-person shop, and vice versa. Matching the tool to your team's actual capacity - not your aspirational roadmap - is where the decision gets made.
Once your integration layer is solid, the next question becomes what systems it can support. For enterprises looking to extend clean, integrated data into AI automation, Cybic's Drava platform connects data pipelines to machine learning models, AI reasoning layers, and autonomous agents - turning integrated data into operational workflows that run without manual intervention. Organizations in healthcare, manufacturing, oil and gas, and retail use it to move beyond reporting and into AI systems that act on data directly.
The right question isn't only which tool moves your data. It's which platform will support the AI systems you intend to build on top of it.
Frequently Asked Questions
What is the difference between ETL and ELT in data integration?
ETL transforms data before loading it into the destination - the right fit for legacy warehouses with strict, stable schemas. ELT loads raw data first and transforms it inside the warehouse using native compute. Most cloud-first teams use ELT because platforms like Snowflake and BigQuery handle transformation at scale, and schemas evolve too frequently for pre-load processing to keep up.
What is Change Data Capture (CDC) and when do I need it?
CDC tracks and captures row-level changes in a source system as they occur - inserts, updates, deletes - and streams them to the destination in near-real-time. It's most valuable when data freshness directly impacts outcomes like fraud detection, inventory management, or live ML model inference. For standard analytics and reporting, scheduled batch loads are usually sufficient and significantly simpler to operate.
Do I need coding skills to use a data integration tool?
It depends entirely on the tool. No-code tools like Hevo Data, Fivetran, and Workato are designed for business and analytics teams without engineering backgrounds. Developer-first tools like Airbyte and AWS Glue require SQL or Python proficiency. Match the tool's technical requirements to the team that will own it long-term - not the team setting it up during a proof of concept.
What is Reverse ETL and why does it matter in 2026?
Reverse ETL pushes cleaned, transformed data from a warehouse back into operational tools like Salesforce or HubSpot, so sales and marketing teams act on insights without pulling reports manually. In 2026, it also powers AI agents and automated workflows that depend on current warehouse data - making it a critical layer between analytics and action.
Is open-source data integration better than a managed SaaS solution?
Open-source tools like Airbyte offer flexibility and no licensing cost, but require engineering time for deployment, maintenance, upgrades, and monitoring. Managed SaaS platforms like Fivetran or Hevo trade that control for reliability and reduced overhead. Choose open-source when budget is the constraint; choose managed SaaS when engineering bandwidth is.
How do I know if a data integration tool is AI-ready?
An AI-ready integration platform delivers:
- Real-time or near-real-time data freshness
- End-to-end data lineage and governance
- Automatic schema evolution handling
- Support for vector databases and ML inference pipelines
Teams building AI agents or LLM applications need infrastructure that guarantees data quality and access controls. Pipelines that only move rows won't cut it.


