
Introduction
Most data engineering teams discover a hard truth about six months into an AI deployment: the model isn't the problem. The pipeline is.
Traditional ETL moves rows from source to destination on a schedule. That's not enough for AI. Models need source authority, semantic context, freshness signals, governance controls, and lineage - available at inference time, not just at the data destination. That requires rethinking the pipeline from the ground up.
The stakes are concrete. According to IBM research, more than one-quarter of organizations estimate annual losses above $5M from poor data quality, with 7% reporting losses of $25M or more.
That infrastructure gap also stalls scale: only 16% of AI initiatives have reached enterprise-wide deployment, per IBM's 2025 CEO Study.
Fixing that gap is what this guide is for. It's written for data engineers, enterprise architects, and technical decision-makers in manufacturing, healthcare, energy, and retail who are moving AI from pilot to production. The guide covers what "AI-ready" means architecturally, a five-stage implementation sequence, governance requirements, and the failure patterns that kill production deployments.
Key Takeaways
- An AI-ready pipeline extends traditional ETL with semantic context, inline governance, real-time ingestion, and ML-specific feature management
- Most AI project failures trace to data readiness gaps, not model quality - pipeline architecture is the highest-leverage investment before deployment
- Five implementation stages drive a production-ready pipeline: schema design and data contracts, ingestion and enrichment, storage layer, feature engineering, and ML platform integration
- Governance must be embedded architecturally from day one: retrofitting it after go-live produces context drift and compliance exposure
- Post-launch monitoring is not optional: business definitions shift, upstream systems change, and pipelines that ran fine at launch silently degrade
What Makes a Data Pipeline "AI-Ready"?
A traditional pipeline succeeds when clean rows reach their destination on schedule. An AI-ready pipeline has a harder job.
Models require more than data. They need to know where data came from, whether it's fresh, what it means in business terms, and whether training calculations match what runs at inference. Delivering rows without that context produces models that pass testing and fail in production.
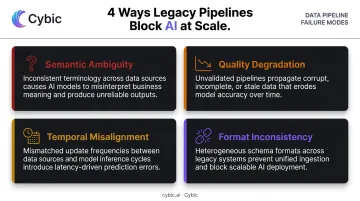
The Four Technical Barriers
Legacy pipeline infrastructure blocks AI from scaling through four specific failure modes:
- Semantic ambiguity - data is stripped of business meaning during transformation; a field called
revenuecould mean gross, net, or recognized revenue depending on which system generated it - Quality degradation - accuracy erodes through each transformation step without inline validation catching the drift
- Temporal misalignment - features assembled from different time windows introduce leakage, where data that wasn't available at prediction time contaminates training
- Format inconsistency - incompatible schemas and identifiers across source systems make joins unreliable and feature calculations unpredictable
The Data Maturity Gap
IDC's 2025 Enterprise AI Maturity Findings classified only 14% of organizations as "AI Masters" with cohesive enterprise-wide data architectures. Another 15% qualified as "AI Emergents." The remaining 71% can't yet deploy AI at scale.
"Not yet ready" looks like this in practice:
- Fragmented data flows with no single source of truth
- No established quality thresholds for critical business metrics
- No lineage tracking from raw source to transformed output
- No formal agreement on what "correct" means for key fields
Organizations in this state should not proceed directly to pipeline construction. Getting these foundations right first is what separates pipelines that support production AI from ones that don't survive contact with it.
Implementation Guide: Building an AI-Ready Data Pipeline
The implementation arc moves through five stages: schema design, ingestion, storage, transformation, and ML integration. Shortcuts in early stages compound into failures at deployment. A schema built without AI readiness in mind becomes a hard constraint on every model that runs against it - one that no downstream fix can undo.
This is also a cross-functional effort. Before a single line of code is written, you need alignment across:
- Data engineering and data science teams
- Security and compliance stakeholders
- Business owners who define what "correct" means for key metrics
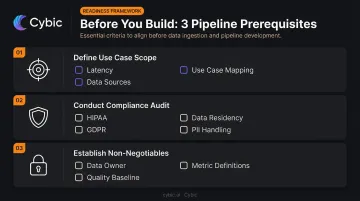
Prerequisites and Design Decisions
Before building:
Define use case scope - identify every AI use case the pipeline must serve, map required data sources and behavioral signals, and specify latency requirements. Real-time fraud detection and batch demand forecasting have very different pipeline designs; a single architecture that ignores this distinction serves neither well.
Conduct a compliance audit - identify all regulatory requirements upfront: data residency rules, PII handling, consent management, and access controls. In healthcare, HIPAA's technical safeguard categories include access controls, audit controls, integrity controls, and transmission security. GDPR Article 25 requires data protection by design, including pseudonymization and data minimization at the architecture level - not as post-processing steps.
Establish non-negotiables - pipeline construction should not proceed without: a defined data owner for every critical source, an established quality baseline, and documented agreement on what "correct" means for key business metrics.
Step 1: Schema Design and Data Contracts
Define schemas for all data sources before ingestion begins. Specify expected data types, required fields, and validation rules so bad data is caught at the boundary rather than propagated downstream.
Then establish data contracts between producers and consumers. A data contract is a formal agreement covering field definitions, acceptable value ranges, update frequency, and how schema changes will be communicated. Tools like dbt enforce model contracts at build time - if transformation logic or input data doesn't conform, the model doesn't build. That's the correct failure mode: loud and early, not silent and late.
Schema changes without contracts are a primary cause of production AI failures. Treat them as breaking changes requiring pipeline versioning.
Step 2: Data Ingestion and Enrichment
Set up connectors that collect data from all required sources in the correct format. Include enrichment at collection time - location context, session identifiers, experiment flags - rather than as a downstream fix. Enrichment added post-ingestion is harder to audit and easier to get wrong.
Integrate privacy controls at the ingestion layer: consent management, anonymization, and opt-out handling.
The 2015 DeepMind/Royal Free case - where records of 1.6 million NHS patients were shared without sufficient privacy protections - illustrates what happens when consent mechanisms are addressed after data is already flowing.
Step 3: Storage Layer Setup
Follow a layered storage architecture:
- Raw layer - immutable event store partitioned by date; never overwrite raw data in place. This preserves the ability to replay, reprocess, or audit any data point.
- Processed layer - cleaned, structured, query-optimized warehouse for transformed data
- Feature store (evaluate based on use case) - serves consistent feature values across both model training and inference environments
AWS SageMaker Feature Store, Tecton, and Databricks Feature Store all address the same core problem: ensuring what a model sees during training matches what it sees in production. Enabling both online and offline stores for a feature group keeps both synced and eliminates one of the most common sources of silent performance degradation.

Step 4: Transformation and Feature Engineering
With storage in place, transformation logic must enforce two constraints that cannot be delegated to convention or discipline:
Point-in-time correctness - every feature calculation must use only data that would have been available at prediction time. Tecton's training data API requires a timestamp key for each sample precisely because this constraint must be enforced programmatically.
Automatic lineage tracking - document which sources feed which outputs and version all transformation logic. When a model output breaks, you need to trace it to the exact pipeline release that produced it. Without versioned lineage, that investigation takes weeks instead of hours.
Step 5: ML Platform Integration and Consistency Checks
Standardize output formats for ML tooling. Apache Parquet is the standard for offline feature store data - column-oriented, compressed, and optimized for the batch reads that training jobs require. ORC serves similar purposes in Hadoop-oriented environments.
Before go-live, run consistency checks: verify that the data a model sees during training exactly matches what it will see in production. Google's Rules of Machine Learning identifies training-serving skew - a discrepancy between training and serving pipelines, data changes, or feedback loops - as a leading cause of production model failures. TFX can automate this validation, detecting skew between training and serving data before deployment.
Governance, Data Quality, and Validation
Inline Governance vs. After-the-Fact Validation
Inline governance outperforms external quality checks for one practical reason: issues caught during pipeline processing are fixed before expensive model training begins. By the time production failures surface a data problem, the damage is already done.
IBM research shows 43% of chief operations officers identify data quality as their most significant data priority, and 45% of business leaders cite data accuracy or bias concerns as a leading barrier to scaling AI. These aren't abstract concerns - Unity lost approximately $110M in revenue after inaccurate data ingestion corrupted datasets used to train ad-related ML models.
Quality Thresholds and Monitoring
Define enforceable quality standards for each data domain:
- Completeness - what percentage of required fields must be populated
- Accuracy - acceptable value ranges per field, validated at ingestion
- Freshness - maximum acceptable data age before pipeline alerts fire
- Consistency - cross-system agreement on shared identifiers and values
Configure monitoring alerts that fire when thresholds are breached - not just when pipelines fail entirely. Delta Lake enforces schema and constraint checks on write. Great Expectations treats data assertions as versioned, testable artifacts. Both catch problems before they reach models.

For enterprise-scale pipelines, the gap between data infrastructure and production AI operation is where most failures originate. Cybic's Drava platform is built specifically to close that gap - connecting data, machine learning, AI reasoning, and intelligent agents within a single governed framework rather than assembling disconnected point solutions.
Post-Launch Validation and Context Drift
Before the pipeline enters full operation, confirm:
- Schema adherence across live data
- Feature consistency between training and serving environments
- Functional testing of downstream model outputs
- Clear indicators that distinguish correct from incorrect pipeline behavior
After launch, the drift problem begins. Business definitions shift, upstream systems change, and model logic is retrained.
Pipelines without change detection on certified data sources, time-to-live rules on definitions, and feedback loops from agent outputs will silently diverge from the reality they were built to represent. No alert fires. The failure accumulates quietly until it surfaces somewhere downstream.
Common Pipeline Pitfalls and How to Fix Them
Data Leakage
Training metrics look strong - then the model falls apart in production. The culprit is usually feature calculations that use future timestamps or join windows crossing time boundaries, feeding the model data it couldn't have seen at prediction time.
To close the gap:
- Apply strict time-based partitioning to every feature calculation
- Audit each join for temporal correctness before any training run kicks off
Training-Serving Skew
Model behavior in production diverges from training performance, even when model weights haven't changed. The root cause is usually a split between environments: features are calculated one way during training and a slightly different way at serving time, or different data sources get queried at different points in the pipeline.
A feature store solves this by enforcing a single calculation path for every feature - accessed identically during both training and inference, with no room for drift to creep in.
Schema Drift
Upstream teams rename fields, change data types, or modify value enumerations - often without flagging it downstream. The result is corrupted model inputs that fail silently until a transformation breaks or predictions go sideways.
Three steps keep schema drift from compounding:
- Validate continuously at the ingestion boundary, not just at setup
- Alert automatically whenever schema deviates from the registered version
- Version the pipeline on every schema change - treat them as breaking changes, not minor updates
Best Practices for Long-Term Pipeline Success
Apply engineering discipline to pipeline code - implement CI/CD, automated testing, and version tagging that connects pipeline releases to model releases. Google's MLOps guidance applies the same standard engineering practices to ML pipelines, which makes debugging production failures tractable rather than archaeological.
Document at build time, not retrospectively. Capture schema definitions, lineage, data contracts, and transformation rationale while the pipeline is being built. Teams that defer documentation find that six months post-launch, no one can explain why a specific feature is calculated the way it is - a pattern the Sculley et al. hidden technical debt paper identified as a primary driver of ML system debt.
Know when to bring in specialists. Regulated industries add compliance constraints that go beyond standard data engineering - HIPAA for healthcare, NERC CIP-011-3 for energy infrastructure, NIST SP 800-82 for manufacturing OT environments. Cybic's engineering-led delivery is built for these contexts, where governance requirements, existing infrastructure, and operational constraints must all be satisfied before deployment.
Conclusion
Pipeline quality is the primary determinant of AI success in production. Models are only as reliable as the infrastructure feeding them, and every shortcut taken during pipeline design compounds into degraded model performance, compliance exposure, or outright production failure.
Treat AI-ready pipeline implementation as a foundational investment. These aren't optional engineering concerns - they're what separates AI systems that deliver measurable business value from proofs of concept that stall before production:
- Schema design that enforces consistency from the source
- Embedded governance that satisfies compliance requirements at the architecture level
- Feature consistency validated across training and serving environments
- Post-launch monitoring that catches drift before it reaches model outputs
Frequently Asked Questions
What is an AI-ready data pipeline?
An AI-ready pipeline delivers not just clean rows on schedule, but source authority, semantic context, governance signals, and data freshness - the full context a model needs to reason reliably at inference time. It extends traditional ETL with feature management, lineage tracking, and inline quality enforcement.
Can AI create data pipelines?
AI agents can automate pipeline creation, design transformations from natural language prompts, monitor for schema drift, and flag data quality issues. Human oversight remains required for architectural decisions, compliance requirements, and production validation, especially in regulated industries where design choices carry legal weight.
Will AI replace ETL?
AI will augment and accelerate ETL rather than eliminate it. Agentic tools reduce manual effort in transformation logic and monitoring, but the core requirement - moving, validating, and governing data from source to destination - remains a foundational engineering problem that automation assists rather than replaces.
How is an AI data pipeline different from a traditional ETL pipeline?
Traditional ETL moves data to a destination and stops. An AI pipeline extends that with feature stores, inline governance, semantic context layers, and real-time ingestion capability. It also adds training-serving consistency checks to ensure what a model sees during training matches what it encounters in production.
What is the biggest reason AI data pipelines fail in production?
Context drift is the leading cause. Business definitions shift, upstream systems change, and retrieval logic diverges while pipelines keep running - but most monitoring isn't configured to catch it. Models continue receiving inputs that no longer reflect the reality they were trained on.
How do you validate that a data pipeline is AI-ready?
Run schema adherence checks on live data, verify feature consistency between training and serving environments, and confirm lineage traceability from raw source to model output. Quality threshold alerts and functional testing of downstream predictions should both pass before go-live.


