Introduction
Law firms and in-house legal teams are adopting generative AI at a striking pace - 31% of legal professionals now use generative AI at work, with adoption at larger firms reaching 39%, according to the ABA's 2025 Legal Industry Report. RAG systems are a natural fit for legal work: connecting LLMs to contract libraries, discovery documents, and research memos to answer questions faster.
The problem is structural. Standard RAG pipelines route document text through external embedding APIs, cloud-hosted vector databases, and third-party LLMs. For general enterprise content, that's a manageable tradeoff. For legal documents, it's a different situation entirely.
When legal content flows through a misconfigured RAG pipeline, the exposure is concrete:
- Attorney-client privilege violations
- Cross-matter data contamination
- GDPR and professional conduct sanctions
A single retrieval error - surfacing one client's deal terms in another client's query response - can trigger all three at once.
This guide covers the specific privacy risks of RAG in legal contexts, the techniques that eliminate or reduce them, the deployment architectures available to legal teams, and what to look for when evaluating a solution.
Key Takeaways
- Standard RAG pipelines send privileged document text to external APIs - each step is a potential confidentiality breach
- Embedding inversion research shows high-dimensional vectors can be partially reconstructed to recover original text
- Access control gaps allow semantically similar content to cross matter and client boundaries without authorization
- Effective legal RAG requires PII de-identification, local embedding, matter-level RBAC, and immutable audit logging
- Deployment architecture (cloud, hybrid, on-premises) sets your privacy risk profile; governance must be designed in, not retrofitted
What Makes Legal Documents Uniquely Sensitive for RAG
Legal documents aren't just sensitive - they carry specific legal obligations that general enterprise content does not.
The data categories involved:
- Personally identifiable information and client identifiers
- Attorney-client privileged communications
- Work product protected under litigation strategy
- Non-public M&A terms and financial details
- Trade secrets shared under representation
- Protected health information in healthcare litigation contexts
Any of these categories surfaced in the wrong query response can trigger privilege waiver, bar disciplinary proceedings, and client loss - consequences that go well beyond a standard data breach.
The Cross-Matter Contamination Problem
A shared RAG knowledge base ingesting contracts, briefs, and discovery documents from multiple clients creates a structural hazard. Vector retrieval operates on semantic similarity. It doesn't know which client owns which document. A query about one client's contract terms can pull chunks from a different client's negotiation memo simply because the content is topically similar.
ABA Formal Opinion 512, issued in July 2024 to address generative AI directly, explicitly warns that self-learning AI tools raise a risk that information from one client's representation may be disclosed to others. No public incident has quantified exactly how often cross-matter retrieval occurs - but the ABA didn't wait for one before issuing guidance.
Professional Obligations Beyond Data Protection Law
ABA Model Rule 1.6 requires lawyers to make reasonable efforts to prevent unauthorized access to client information. This obligation extends to any technology used in legal work.
A privacy breach through a RAG system isn't purely a data security incident. It's a potential professional conduct violation - one that triggers bar disciplinary processes on top of any regulatory exposure the firm already faces.
How Standard RAG Creates Legal Privacy Risks
The Embedding API Exposure Problem
In a standard RAG pipeline, raw document text is sent to a third-party embedding service - OpenAI, Cohere, or similar - to generate vector representations. For legal documents, that means privileged communications, client identifiers, and deal terms are transmitted to an external server operator who may retain or log that data in ways that conflict with confidentiality obligations.
The transmission itself may constitute a disclosure under Rule 1.6, regardless of whether the vendor actually misuses the data.
Vector Reconstruction Risk
Embeddings are commonly assumed to be anonymous. They aren't. Research by Morris et al. demonstrated that their embedding inversion method could recover 92% of 32-token text inputs exactly, including personal information such as full names from clinical notes. A 2024 follow-up study confirmed that LLMs can further improve reconstruction of original content from embeddings.
For legal teams, this means a third-party vector database carries real re-identification risk - not just theoretical exposure.
LLM Inference-Phase Exposure
Even when document ingestion is handled locally, the retrieval step packages the highest-relevance document chunks directly into the LLM prompt. If that LLM is accessed via an external API, the most specific, most sensitive content from privileged documents is being transmitted externally - often more targeted and damaging than bulk ingestion would be.
Access Control and Audit Trail Gaps
Two structural gaps that frequently appear in RAG implementations built without legal requirements in mind:
- No matter-level access filtering: RAG retrieves on semantic similarity alone, so a junior associate can pull chunks from a senior partner's privileged strategy memo in an unrelated matter simply because the content matches.
- No retrieval audit trail: Most RAG implementations don't log which chunks were returned, to whom, or when - making privilege reviews, confidentiality investigations, and e-discovery responses involving AI outputs nearly impossible.

OWASP LLM08:2025 identifies both of these as documented security risks in RAG systems - recommending permission-aware vector stores and fine-grained access controls as mitigations.
Core Privacy-Preserving Techniques for Legal RAG
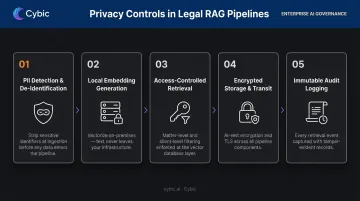
PII Detection and De-Identification at Ingestion
Before any document chunk enters the embedding pipeline, a detection layer should identify and mask or tokenize sensitive entities: names, case numbers, client identifiers, financial figures, and privilege markers. The masking needs to be context-preserving - the document must remain semantically usable for retrieval while stripping the specific identifiers that create exposure.
The EDPB's 2025 paper on AI privacy risks and LLMs explicitly addresses data minimization in RAG pipelines, calling for the exclusion of unnecessary personal identifiers and the use of privacy-screened datasets with relevance filters. Regulators have moved beyond recommending this - they are now specifying it.
Local Embedding Generation
Running the embedding model on-premises or within a private cloud environment means document text never leaves organizational infrastructure during vectorization. The trade-off is real: local models are typically smaller and less capable than API-based models. For legal use cases, that accuracy difference is generally acceptable - the privacy guarantee isn't optional.
Access-Controlled Retrieval Architecture
Each document chunk should be tagged at ingestion time with:
- Matter ID
- Client ID
- Permission level
At query time, retrieval is scoped to only the chunks the querying user is authorized to access. This filtering must be enforced at the vector database layer - not just the application UI. UI-layer filtering is easily bypassed; only database-layer enforcement is structurally sound. RBAC must be embedded in the retrieval infrastructure itself.
Encrypted Storage, Transit, and Audit Logging
Encryption baseline:
- Vector embeddings and document chunks encrypted at rest within the vector store
- TLS with proper certificate management for all data in transit between system components
These controls are non-negotiable, yet they are routinely missing from RAG prototypes that get pushed toward production before a proper security review.
Audit logging requirements for legal RAG:
- Every retrieval event logged: query, chunks returned, user identity, timestamp, generated response
- Logs stored in an immutable, access-controlled audit store
- Retention sufficient for e-discovery and bar disciplinary proceedings
Without complete audit trails, legal teams cannot conduct privilege reviews of AI outputs, investigate suspected breaches, or demonstrate governance controls to regulators. The EDPB's 2025 LLM report calls out insecure logging and caching of retrieved documents as one of the most common RAG privacy failures - making this a regulatory exposure point, not just an operational gap.
Deployment Architecture Options for Legal RAG
The right architecture depends on the sensitivity of the document categories involved and the organization's tolerance for third-party data exposure.
| Architecture | Privacy Profile | Trade-offs |
|---|---|---|
| Fully cloud-hosted | Highest exposure | Fast to deploy; requires DPAs and contractual safeguards |
| On-premises | Strongest privacy | Data stays in-house; higher infrastructure cost; typically lower LLM quality |
| Hybrid | Balanced | Sensitive operations on-premises; hosted LLM for generation only; limits exposure to chunk-level passages |
| Governance-embedded enterprise | Comprehensive | Architecture and governance combined; controls embedded structurally, not layered on afterward |
Why Architecture Alone Isn't Enough
For law firms and large legal departments, the architecture choice is necessary but insufficient. The governance framework - RBAC, encryption, audit logging, data isolation, and a firm policy of no model training on client data - must be embedded at the architectural level.

Cybic builds these controls directly into the system architecture - treating security, access controls, and auditability as structural properties, not configuration options. For organizations operating across cloud, hybrid, and on-premises environments, that consistency across deployment boundaries is what makes governance enforceable in practice.
Regulatory and Compliance Requirements for Legal RAG
GDPR Obligations
Key requirements for any RAG system processing personal data in EU-connected legal matters:
- Data minimization (Article 5): Only ingest what is necessary for the stated purpose
- Purpose limitation: Embeddings generated for RAG cannot be repurposed for model training without a separate legal basis
- Right to erasure (Article 17): A data subject's deletion request must reach the vector store layer. Pinecone, Weaviate, and Qdrant support deletion by ID or metadata filter, but legal sufficiency requires documented processes - not just technical capability
- Data Processing Agreements (Article 28): Every third-party vendor in the RAG pipeline requires a DPA
US Professional Responsibility and Privacy Framework
Bar ethics obligations:
- ABA Formal Opinion 477R: Lawyers may transmit client information over the internet with reasonable safeguards; higher-risk information requires stronger protections
- ABA Formal Opinion 512 (2024): Lawyers must understand the technology they use, including its confidentiality implications
- California COPRAC guidance: Lawyers must not input confidential client information into a generative AI tool presenting material confidentiality risks without informed client consent
- Florida Bar Opinion 24-1: Requires lawyers to research AI tool policies on data retention, sharing, and self-learning
US privacy law:
- CCPA applies to California-connected matters involving consumer personal information
- HIPAA applies where legal work involves patient data - attorneys with access to PHI can qualify as business associates, requiring written safeguards
Practical Compliance Checklist
Before deploying any RAG tool for legal work:
- Vendor data processing assessment: Document where document text goes during embedding, who can access the vector database, and whether the vendor trains on client data
- Data classification policy: Determine which document categories (privileged, work product, PHI) can enter which RAG environment
- Legal basis for processing: Document the basis for processing personal data through AI tools under applicable law
- Deletion request process: Establish a documented workflow that reaches the vector store layer, not just the application database
Evaluating a Privacy-Preserving RAG Solution for Legal Use
Key Questions for Any Vendor
- Where is embedding computed - on your infrastructure or the vendor's?
- Who can access the vector database, and how are access logs maintained?
- Does the vendor train models on your documents?
- What happens to your data if the contract is terminated?
- Can you demonstrate matter-level and client-level access partitioning?
These questions surface where accountability gaps are most likely to exist. Once you have clear answers, the next step is verifying that the solution's architecture actually enforces them.
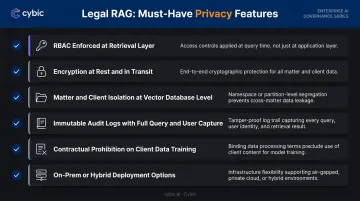
Must-Have Features
A privacy-preserving RAG solution for legal use requires:
- RBAC enforced at the retrieval layer, not only at the application UI
- Encryption applied at rest and in transit across every pipeline component
- Matter and client isolation enforced at the vector database level, not just in application logic
- Immutable audit logs that capture query, retrieved chunks, user identity, timestamp, and generated response
- Contractual prohibition on using client data for model training
- On-prem or hybrid deployment options for organizations with data residency requirements
Cybic's governed AI platform builds each of these requirements into its architecture: RBAC, encrypted data protection, full auditability of AI-driven actions, and a no-training-on-client-data policy. Deployment spans cloud, hybrid, and on-premises environments across AWS, Azure, and Google Cloud to accommodate varying data residency requirements.
Red Flags to Avoid
Not every solution that markets itself as "privacy-preserving" enforces that promise at the infrastructure level. Watch for these warning signs:
- Vendors that cannot clearly state where document text goes during the embedding phase
- RAG tools with no matter-level access partitioning in the vector store
- Solutions that log queries and responses to improve their models without explicit opt-out
- Architectures where the vector database is shared across multiple customer tenants without logical isolation
Frequently Asked Questions
Does using RAG on legal documents mean the AI is being "trained" on client data?
RAG retrieval does not by default train the model - documents are used as runtime context, not for model weight updates. However, some vendors log interactions for model improvement, making it critical to verify contractually that no client data is used for training before deployment.
How does privacy-preserving RAG protect attorney-client privilege?
Privilege protection depends on three controls: RBAC and matter-level isolation to restrict who can retrieve privileged chunks, safeguards preventing those chunks from reaching external APIs, and audit records showing privileged materials were handled appropriately.
Can legal RAG systems be deployed entirely on-premises?
Yes. Fully on-premises RAG is achievable using locally-hosted embedding models, self-managed vector databases, and on-premises LLM inference. The trade-offs are higher infrastructure cost and typically lower model capability for complex legal reasoning compared to cloud-hosted alternatives.
What is the risk of one client's data appearing in another client's RAG response?
Cross-matter contamination occurs when a shared vector store lacks client-level access filtering - retrieval returns semantically similar chunks regardless of matter assignment. The solution is namespace isolation and mandatory metadata-based access filtering enforced at query time, not just at the application layer.
How does GDPR affect the use of RAG for legal documents?
Three GDPR obligations directly constrain RAG design: data minimization limits what can be ingested, purpose limitation restricts how embeddings can be used, and the right to erasure requires deletion mechanisms that reach the vector store layer. Every third-party vendor in the pipeline also requires a Data Processing Agreement under Article 28.
How can I verify what data my RAG system retrieved and surfaced in a response?
This requires immutable audit logging at the retrieval layer: the query, the exact chunks retrieved, the user identity, and the generated response must all be captured. Without this capability, legal teams cannot conduct privilege reviews of AI outputs or investigate potential confidentiality incidents.