
Introduction
Financial services firms are under real pressure to move beyond AI pilots and into production systems that deliver measurable value. Building custom AI in this environment means navigating data governance, regulatory alignment, legacy integration, and model explainability all at once.
The failure rate reflects this complexity. Gartner projects that 60% of enterprise AI projects will be abandoned through 2026 due to a lack of AI-ready data. In financial services specifically, 30% of GenAI projects are abandoned after proof of concept most often because of poor data quality and inadequate risk controls.
What separates deployments that ship from those that stall is preparation. This guide covers when custom AI is the right call, what must be in place before you build, the step-by-step process, and the variables that most often determine success or failure.
Key Takeaways
- Custom AI delivers 2-3x stronger ROI for high-volume, domain-specific workflows and not every use case
- Success hinges on data quality, governance architecture, model selection, and integration depth
- The build process follows four phases: use case definition, data/compliance audit, architecture design, and governed deployment
- Governance must be embedded at the architectural level from day one, not added after the fact especially in regulated environments
- Most failures start with technology choices before defining the problem clearly
When Does Custom AI Make Sense in Financial Services?
Custom AI isn't the right solution for every financial workflow. The decision should be driven by workflow complexity, data specificity, and transaction volume and not technology enthusiasm or competitive pressure.
High-ROI Use Cases for Custom AI
Custom AI delivers measurable returns in specific scenarios:
- High-volume document extraction : Processing thousands of contracts, loan applications, or compliance filings where proprietary document structures make generic OCR tools ineffective
- Automated reconciliation : Matching transactions across multiple systems where business rules are firm-specific and error rates directly impact capital requirements
- Portfolio monitoring : Tracking risk exposures across complex instruments where proprietary risk models and real-time data feeds are competitive advantages
- Compliance reporting : Generating regulatory submissions where data must be traced to source systems and audit trails are mandatory
- Fraud detection : Identifying suspicious patterns in transaction data where false positive rates directly impact customer experience and operational costs
Custom AI models deliver 2 to 3 times stronger ROI than generic vendor models by leveraging proprietary data for precision. HSBC's custom AI solution for anti-money laundering identified 2 to 4 times more suspicious activity while reducing false positive alerts by 60% compared to legacy systems.
When Custom AI Underperforms
Custom AI isn't justified in several scenarios:
- Low-transaction workflows where Processes handling fewer than 1,000 transactions monthly where development costs exceed efficiency gains
- Fully autonomous credit decisions where Mid-market deals requiring relationship context and judgment that AI cannot replicate
- Regulated review requirements where Workflows where compliance obligations mandate human sign-off regardless of automation capability
Three Build Approaches
Organizations typically choose between three paths, each with different tradeoffs:
- Off-the-shelf SaaS : Fast to deploy, but limited customization and rarely built for firm-specific data structures or compliance requirements
- Internal build : Full control over architecture, but demands ML engineering talent that most mid-market firms don't have in-house
- AI engineering partner : Combines speed with customization; the right fit when regulatory alignment, audit trails, and legacy system integration are non-negotiable
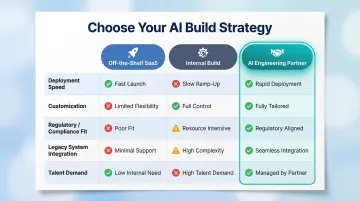
For financial services teams where governance is embedded into every layer of the solution and not bolted on after working with a firm like Cybic, which builds security controls and auditability directly into the architecture, reduces the compliance risk that internal builds and off-the-shelf tools often leave unaddressed.
What You Need Before Building a Custom AI Solution
Preparation determines deployment outcomes. Firms that skip the readiness phase encounter compliance failures, integration bottlenecks, and model performance issues after launch.
Data and Infrastructure Readiness
"Data ready" in financial services means three things:
- Accessible, labeled, and clean historical data which is usable by models without extensive pre-processing
- Defined data pipelines which is structured flows that move data from source to model reliably
- Documented data governance , a clear map of where sensitive data lives and how it's controlled
63% of organizations either do not have or are unsure if they have the right data management practices for AI. Data scientists spend 60-70% of their time just trying to find the right data due to organizational silos. That lost time cascades: delayed pipelines, stalled model training, and missed deployment windows.
Platforms designed to connect enterprise data, ML pipelines, and AI agents such as Cybic's Drava platform provide the governed data infrastructure layer that most firms lack before they build.
Regulatory and Compliance Groundwork
Compliance prerequisites must be assessed before architecture decisions are made:
- Applicable regulations like GDPR, SOX, Basel III, or sector-specific frameworks that govern data use and model outputs
- Explainability requirements Whether model decisions require human-interpretable explanations for auditors or customers
- Audit trail mandates Logging requirements for model inputs, outputs, and decision logic
- Data residency constraints Geographic restrictions on where data can be processed or stored
The CFPB warns that creditors cannot justify noncompliance with ECOA adverse action notice requirements based on the fact that the technology employed is too complicated or opaque to understand. Regulators expect explainability regardless of model complexity.
Team and Expertise Requirements
Core roles required for a custom AI build in financial services:
- ML engineers who design, train, and validate models
- Data engineers who build pipelines and ensure data quality
- A compliance or governance lead who maps regulatory requirements to technical controls
- Domain experts who understand the financial workflow being automated
Many mid-market firms lack in-house ML talent and must choose between hiring, training, or partnering. Hiring cycles are long and competitive against well-funded tech companies. Partnering with an AI engineering firm accelerates deployment while keeping ownership of the system firmly with the client.
How to Build a Custom AI Solution for Financial Services
This process assumes you've completed your readiness assessment. Rushing into architecture decisions without the prerequisites in place is one of the most common failure modes.
Step 1: Define the Use Case and Success Metrics
Map the specific workflow to be automated:
- Inputs : What data enters the process
- Outputs : What decisions or documents the system produces
- Decision points : Where human judgment currently occurs
- Current baseline : Time, cost, and error rate
Without a measurable baseline, it's impossible to evaluate whether the AI solution delivers value.
Establish clear success criteria before model work begins:
- Accuracy thresholds : Minimum acceptable performance levels
- Latency requirements : Maximum processing time
- Compliance checkpoints : Where regulatory review is required
- Human-in-the-loop triggers : Conditions that escalate to human review
Step 2: Audit Your Data and Compliance Posture
Conduct a data audit to assess volume, quality, labeling status, and accessibility. Identify gaps between what data exists and what the model needs to perform reliably in production.
94% of banking and capital markets respondents named data accuracy and reliability as a top priority, while 86% cited ease of access and use as a top concern. Data readiness isn't optional, it's the foundation.

Map regulatory requirements to the specific workflow:
- Which outputs require explainability
- What logging and auditability standards apply
- Whether the model architecture needs to support model cards or documentation for regulatory review
SR 11-7 guidance sets the standard for model risk management in banking: rigorous data quality assessment, clear documentation of limitations, and enough transparency that an unfamiliar reviewer can understand how the model operates and what assumptions it makes.
Step 3: Design the Architecture and Select the Model Approach
The primary architectural decision is model type. Match the approach to what the use case actually requires:
- Traditional ML : Structured data, predictive scoring, credit risk
- Fine-tuned LLM : Document intelligence, report generation, contract review
- Agentic workflow : Multi-step automated decisions with conditional logic
- Hybrid : Combinations where different tasks need different approaches
Integration requirements must be defined early. Financial environments typically involve legacy core banking systems, data warehouses (Snowflake, Databricks), and cloud infrastructure (AWS, Azure, GCP). Infrastructure-agnostic architectures avoid vendor lock-in and allow deployment across cloud, hybrid, or on-prem environments.
Governance controls to embed at the architecture level:
- Role-based access controls (RBAC)
- Encrypted data handling in transit and at rest
- No model training on proprietary enterprise data
- Full auditability of AI-driven decisions
Cybic embeds these controls during architecture design, not as a post-deployment patch. Retrofitting governance after the fact typically leaves gaps that surface during regulatory review.
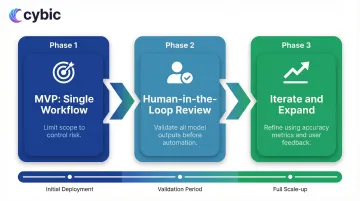
Step 4: Build, Integrate, Deploy, and Monitor
Deploy using a phased approach:
- MVP scoped to a single workflow : Limit initial scope to control risk
- Human-in-the-loop review on all outputs : Validate model decisions before full automation
- Iterate based on accuracy metrics and user feedback : Refine before expanding scope
Production-ready deployment requires more than the model:
- Logging infrastructure : Capture all inputs, outputs, and decisions
- Monitoring dashboards : Track model performance, drift, and error rates in real time
- Incident response protocols : Define escalation paths when the model behaves unexpectedly
- Retraining triggers : Set thresholds that prompt model updates as data distributions shift
Conclusion
Building a custom AI solution for financial services is a multi-phase engineering challenge that spans data infrastructure, model selection, system integration, and ongoing operational oversight. Each phase carries its own failure modes: poorly defined use cases produce systems that can't be measured, under-prepared data pipelines stall model training, and architecture decisions made without regulatory input create compliance debt that surfaces at the worst possible time.
The firms that ship production AI and sustain it long-term share one trait: governance and compliance are not afterthoughts. Regulatory alignment with frameworks like SOX, FINRA, and GDPR, full auditability of model inputs and outputs, and embedded risk controls are not features you retrofit. They are architectural decisions made in Step 1, not Step 4. When those controls are built in from the start, the system can withstand regulatory scrutiny, scale without introducing new risk surfaces, and earn the operational trust required for real automation. When they are missing, even well-performing models get pulled from production.
The pipeline matters. The model matters. The deployment process matters. But in financial services, governance is the deciding factor between a custom AI system that runs your organization and one that gets shut down before it delivers value.
Frequently Asked Questions
What makes a custom AI solution different for financial services compared to other industries?
Financial services AI operates under a uniquely demanding combination of regulatory obligations, auditability requirements, and data sensitivity constraints. Unlike most industries, financial institutions must demonstrate model explainability to regulators, maintain full audit trails of AI-driven decisions, and ensure data residency compliance - all while integrating into legacy core banking systems that were not designed for modern ML workloads. Generic AI tools are rarely built to satisfy these requirements out of the box, which is why custom solutions designed with compliance and governance at the architectural level consistently outperform off-the-shelf alternatives in regulated environments.
How should financial institutions approach data security and compliance when building AI systems?
Compliance work must begin before any architecture decisions are finalized, not after. The first step is mapping applicable regulatory frameworks - GDPR, SOX, Basel III, FINRA requirements, and sector-specific guidance like SR 11-7 - to the specific workflow being automated, so that data handling rules, explainability requirements, and audit trail mandates are known inputs to the design. At the infrastructure level, this means embedding role-based access controls, encrypted data handling in transit and at rest, and strict policies against training models on proprietary enterprise data directly into the architecture. Institutions that treat these as post-deployment checkboxes routinely encounter gaps that require expensive remediation or delay go-live.
What is a realistic timeline for building and deploying a custom AI solution in financial services?
Timelines vary significantly based on data readiness and workflow complexity, but a realistic end-to-end build for a production-grade solution typically runs three to nine months. Simple, well-scoped workflows with clean historical data and existing pipelines can move faster; solutions requiring substantial data preparation, legacy system integration, or novel compliance documentation take longer. The most common timeline killers are data quality gaps discovered during the audit phase and compliance review cycles that weren't accounted for in the project plan - both of which are avoidable with a thorough readiness assessment before architecture work begins.
How should teams handle model drift and ongoing monitoring after deployment?
Model drift in financial services is not a hypothetical - data distributions shift as market conditions change, customer behavior evolves, and regulatory requirements are updated, and a model that performed well at launch will degrade without active maintenance. Production deployments require logging infrastructure that captures all model inputs, outputs, and decision logic; monitoring dashboards that track accuracy, confidence distributions, and error rates in real time; and clearly defined retraining triggers that prompt model updates when performance crosses a threshold. Incident response protocols must be established before go-live so that unexpected model behavior has a defined escalation path, and regular model reviews should be built into operational cadences rather than treated as reactive events.


