
Introduction
Banks process billions of documents annually: loan applications, KYC packets, compliance filings, trade finance contracts, and account opening forms. Despite the volume, manual handling remains the norm and the cost shows it. According to a blog post citing Gartner research via glib.ai, banks spend up to $400 million annually correcting human errors in financial documents, with data entry error rates averaging 1% under normal conditions and spiking to 18-40% under time pressure.
Regulatory pressure compounds the problem. A 2024 Bank Policy Institute survey found that employee hours dedicated to regulatory compliance increased by 61% between 2016 and 2023 leaving already-stretched teams even thinner.
Intelligent document processing (IDP) offers a solution. By combining OCR, machine learning, NLP, and generative AI, IDP automates document capture, classification, extraction, and validation transforming unstructured data into structured, actionable information. What follows covers how IDP works in banking, where it delivers the clearest ROI, and what separates a production-ready solution from one that stalls at the pilot stage.
Key Takeaways
- IDP uses OCR, NLP, machine learning, and generative AI to automatically extract and validate data from banking documents
- Banks deploy IDP across loan processing, KYC onboarding, compliance, and trade finance cutting processing time by up to 75%
- Fewer manual errors, faster customer decisions, and built-in audit trails for regulatory compliance
- Selecting a banking IDP solution requires evaluating governance architecture, integration capability, and security and not just extraction accuracy
What Is IDP And Why Banking Has a Document Problem
Intelligent document processing (IDP) is a technology layer that goes beyond basic OCR by using AI to understand, classify, and extract meaning from structured and unstructured documents (rather than simply converting text to digital format). Gartner defines IDP as "specialized data integration tools that enable automated extraction of data from multiple formats and various layouts of document content."
The Scale of Banking's Document Burden
Banks operate across enormous document categories: account applications, loan files, regulatory submissions, trade finance records, and customer correspondence. Much of this arrives in inconsistent formats handwritten, scanned, or multi-page PDFs. The International Chamber of Commerce estimates that 4 billion pages of trade and trade finance documents are currently in circulation, while SWIFT reports that 65% of payment messages still contain unstructured addresses.
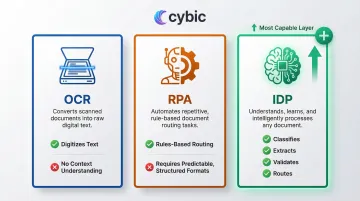
How IDP Differs from OCR and RPA
Traditional OCR recognizes text; RPA executes rules-based workflows. IDP bridges both by understanding document context, validating extracted data, and routing documents to the right workflow. Each technology has a ceiling and banking documents routinely hit all three.
Consider processing a loan packet with mixed document types: pay stubs, tax returns, bank statements, and appraisals, each with different layouts. OCR alone would digitize the text but couldn't identify which document is which or extract a specific field like "gross monthly income" from a pay stub. RPA could route documents, but only if they arrive in predictable formats. IDP handles the entire workflow classifying each document type, extracting relevant financial data, validating it against lending criteria, and routing the completed packet for underwriting.
Document Types Banks Process with IDP
Banks regularly process a wide range of document types across operations and compliance functions:
- Identity documents and KYC/AML records
- Bank statements and credit reports
- Mortgage applications and loan files
- Regulatory filings and audit documentation
- Contracts and customer correspondence
IDP is designed to handle all of these across formats, layouts, and languages without requiring a separate template for each.
The Evolution to LLM-Powered IDP
Modern IDP has evolved from rule-based document capture systems to LLM-powered platforms. IDC notes that vendors are increasingly integrating GenAI and LLMs to deliver advanced capabilities including semantic understanding, document querying, and advanced entity extraction. These newer systems no longer need extensive template training. A modern LLM-powered IDP platform can process a new document type it has never seen before extracting the right fields, flagging anomalies, and routing appropriately without engineering intervention between each new format.
How IDP Works: The AI Stack Behind Intelligent Document Processing
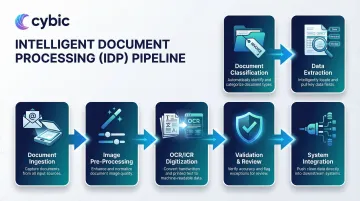
The Five-Stage Processing Pipeline
IDP operates through a standardized pipeline:
- Document ingestion : Capture from email, scanner, portal, or API
- Image pre-processing : De-skew, remove noise, enhance quality
- OCR/ICR digitization : Convert images to searchable text, including handwriting
- Document classification : AI identifies document type based on layout and content
- Data extraction : Computer vision and NLP extract specific fields
- Validation : Business rules verify data and assign confidence scores
- Integration : Validated data flows to downstream systems via APIs
Core AI Components
Each stage relies on specific AI capabilities:
- OCR/ICR : Text recognition including handwriting through intelligent character recognition
- NLP : Understanding context and meaning within extracted text
- Machine learning : Classification and pattern recognition to identify document types
- Computer vision : Layout and structure analysis to locate fields regardless of format variations
- LLMs/GenAI : Handling unstructured or complex free-form documents without requiring pre-built templates
Data Extraction and Validation
Domain-specific validation is critical for banking accuracy. After extraction, IDP cross-checks data against internal systems or reference databases using rules, fuzzy logic, and regex verifying account numbers match expected formats, matching identity fields across multiple documents, and flagging inconsistencies in financial statements.
Each extracted field receives a confidence score. High-confidence results pass through automatically; low-confidence ones are flagged for human review before moving downstream.
Human-in-the-Loop (HITL)
Those flagged extractions go to bank staff for review and correction. Each correction retrains the model through active learning, creating a continuous improvement loop that increases accuracy over time.
In regulated banking environments, HITL serves dual purposes: maintaining accuracy standards required for compliance while progressively reducing the volume of manual review as the model learns.
Downstream Integration
Once data is extracted and validated, it flows into banking systems core banking platforms, CRM, compliance tools via APIs or connectors. This enables automated decisioning, workflow routing, and agent-driven actions. The integration layer positions IDP as part of an end-to-end automated workflow, not a standalone extraction tool.
Banking Use Cases: Where IDP Creates the Most Value
KYC and Customer Onboarding
Verifying customer identity means processing passports, driver's licenses, utility bills, and proof-of-address documents at scale, without delays. Deloitte's 2024 Financial Crime case study found that applying intelligent processing to Customer Due Diligence cut average case handling times by roughly 75% and reduced costs by over 30%. That kind of throughput makes AML/KYC compliance achievable without manual review backlogs.

Loan and Mortgage Processing
Loan packets arrive as stacks of mixed documents. IDP handles them end-to-end:
- Extracts financial data from income statements, tax returns, pay stubs, and appraisals
- Validates figures against lending criteria automatically
- Routes completed packets directly to underwriting queues
One case study put the time impact in concrete terms: processing dropped from 3 minutes to 30 seconds per loan document.
Regulatory and Compliance Document Management
Banks face a constant stream of regulatory filings, audit documentation, and compliance records. IDP classifies, tags, and stores each document automatically building full audit trails that support Basel III, GDPR, and other frameworks. Teams can retrieve any document instantly during examinations, with retention schedules enforced at the system level.
Trade Finance and Contract Processing
Letters of credit, bills of lading, and trade finance contracts are dense, multi-party, and rarely standardized. The ICC outlines "Level 3" and "Level 4" automation, where AI comprehends non-standard clauses and performs non-literal comparisons. For example, matching "Amberes" to "Anvers" across document versions. IDP extracts key terms, dates, parties, and obligations while flagging discrepancies that require manual review.
Account Servicing and Correspondence
Inbound customer correspondence, dispute letters, change-of-address requests, account maintenance forms arrives in volume and varies widely in format. Rather than routing everything to manual queues, IDP classifies each document, extracts relevant data, and triggers the appropriate workflow automatically. A 2025 Cognizant case study showed a global bank processed complex documents 98% faster after deploying generative AI freeing operations teams to focus on exceptions rather than routine intake.
Conclusion
The document burden in banking is not going away. Regulatory requirements are expanding, customer volumes are growing, and the formats documents arrive in are only becoming more varied. Manual processing cannot scale to meet those pressures without compounding the error rates and compliance risks that already cost institutions hundreds of millions of dollars each year.
IDP addresses this directly. By combining OCR, NLP, machine learning, and LLMs into a unified processing pipeline, IDP converts the raw volume of unstructured banking documents into structured, validated, and audit-ready data. The gains reported across KYC onboarding, loan processing, trade finance, and compliance management are not incremental improvements; they represent a fundamental shift in how document-intensive workflows operate, with processing times cut by up to 75% and manual error exposure reduced at scale.
The distinction from earlier automation approaches matters here. OCR digitizes; RPA routes. IDP understands, classifies, and validates across document types it has never seen before, without requiring a new template for each format. Modern LLM-powered platforms extend this further, handling the ambiguity and variability that defeated earlier systems.
For banks evaluating where to start, the clearest ROI comes from high-volume, high-stakes workflows: KYC onboarding, loan origination, and compliance documentation are the natural entry points. From there, the same infrastructure extends to trade finance, account servicing, and any other process where documents are the input and delay is the cost. The path forward is less about whether to adopt IDP and more about building the governance architecture, integration layer, and human review workflows that allow it to operate reliably at production scale.
Frequently Asked Questions
What is the difference between IDP, OCR, and RPA in banking?
OCR (Optical Character Recognition) converts scanned images into machine-readable text but has no understanding of what that text means or where specific data fields are located within a document. RPA (Robotic Process Automation) executes predefined rules-based workflows but breaks down when documents arrive in variable or unexpected formats. IDP combines OCR, NLP, machine learning, and generative AI to classify documents, extract specific fields in context, validate the data against business rules, and route the output to the correct downstream system. In practice, IDP handles the full workflow that OCR and RPA can only partially address.
How does IDP improve KYC and customer onboarding in banking?
IDP automates the extraction and validation of identity information from passports, driver's licenses, utility bills, and proof-of-address documents, eliminating the manual review queue that slows onboarding. Each extracted field is cross-checked against internal records and flagged for human review only when confidence scores fall below threshold. According to a Deloitte case study, applying intelligent processing to Customer Due Diligence cut average case handling times by roughly 75% and reduced costs by over 30%, allowing compliance teams to scale AML and KYC operations without proportional headcount increases.
Can IDP handle loan and mortgage processing end-to-end?
Yes. IDP processes the mixed document stack that arrives with a loan application, including income statements, tax returns, pay stubs, bank statements, and property appraisals, each with different layouts and formats. It classifies each document type, extracts the relevant financial fields, validates the figures against lending criteria, and routes the completed packet to underwriting. One documented case study recorded processing time dropping from 3 minutes to 30 seconds per loan document, which compounds significantly at the volumes most mortgage lenders operate.
How does IDP support regulatory compliance and audit readiness?
IDP automatically classifies and tags regulatory filings, audit documentation, and compliance records at ingestion, building full audit trails without manual indexing. Retention schedules are enforced at the system level, and any document can be retrieved instantly during an examination. This directly supports compliance with frameworks like Basel III and GDPR by ensuring that every document is accounted for, traceable, and accessible on demand, reducing the manual effort that compliance teams spend on documentation management.
What should banks evaluate when selecting an IDP platform?
Beyond raw extraction accuracy, banks should assess three areas: governance architecture (how the platform handles data access controls, auditability, and regulatory alignment), integration capability (whether it connects to existing core banking platforms, CRM, and compliance systems via standard APIs without heavy custom engineering), and security (encryption in transit and at rest, role-based access controls, and data residency options). Platforms that require extensive template training for each new document type will hit operational ceilings quickly; LLM-powered systems that generalize across document formats without template engineering scale more effectively as document variety grows.
What is Human-in-the-Loop (HITL) and why does it matter for banking IDP?
Human-in-the-Loop (HITL) is the review mechanism that routes low-confidence extractions to bank staff before they move downstream. Each field the system extracts receives a confidence score; results above the threshold pass automatically, while those below are flagged for manual correction. In regulated banking environments this serves two purposes: it maintains the accuracy standards required for compliance, and each correction retrains the model through active learning, progressively reducing the volume of items that require human review over time. HITL is what makes IDP suitable for production banking environments where data errors carry regulatory and financial consequences.


