
This guide is written for engineering leaders, architects, and technical managers facing that reality. It covers what migration actually involves, how to sequence it, which patterns work in practice, and - just as importantly - when not to migrate at all.
Key Takeaways
- Migration is incremental service extraction from a coupled codebase, not a rewrite
- Do it to solve specific, measurable problems - deployment speed, team autonomy, selective scaling - not for its own sake
- The Strangler Fig, Branch by Abstraction, and Parallel Run are the three patterns that hold up in production
- Shared databases produce distributed monoliths - data decomposition is where most migrations stall
- Stop before full decomposition if your team is small, your domains are unclear, or your product is still taking shape
What Monolith-to-Microservices Migration Actually Means
Migration is the systematic process of decomposing a single, tightly coupled application into independently deployable services - each owning its own logic and its own data, communicating through well-defined APIs.
The goal is not "having microservices." That's a means. The actual targets are operational:
- Faster delivery cycles with fewer cross-team bottlenecks
- Fault isolation so one service failure doesn't cascade
- Independent scaling for high-demand components
- Reduced dependencies between teams shipping features
Without defined success criteria tied to those outcomes, migration has no finish line.
Incremental Extraction, Not Replacement
The monolith keeps serving traffic throughout the transition. Services are extracted one at a time. Old code paths are retired as new ones are validated. This is evolutionary architecture, not a parallel rebuild.
Martin Fowler's migration guidance frames decomposition around three conditions: scale of operation is increasing, pace of change is accelerating, and the cost of modifying the monolith is growing. When those conditions aren't present, migration is hard to justify.
Why Organizations Migrate - Signs Your Monolith Is Breaking Down
Monoliths fail at scale in predictable ways. The structural problems are well-documented by practitioners:
- Deployment coupling - one small change forces a full-system redeploy, making every release high-stakes regardless of scope
- Scaling constraints - you can't scale the payment processor independently from the reporting module; everything scales together or not at all
- Delivery contention - multiple teams working in the same codebase block each other's releases, creating coordination overhead that compounds as team size grows
- High cost of change - even minor features require understanding (and not breaking) unrelated subsystems
Business-Level Triggers Worth Paying Attention To
These aren't technical symptoms - they're business symptoms with technical root causes:
- Release cycles stay long even after repeated process improvements
- Scaling one high-traffic feature forces the entire application to scale with it
- Team growth has made single-codebase coordination unsustainable
- Small features ship slowly because they touch too many teams to coordinate
When Migration Is Not Justified
Vague goals, peer pressure, and "everyone else is doing it" don't justify the operational complexity of distributed systems. ThoughtWorks' guidance is explicit: a modular monolith - organizing code into clearly separated modules within the same deployable unit - is often preferable.
Before committing to a distributed architecture, ask two questions:
- Are your domain boundaries actually clear, or are you still discovering them?
- Are the problems organizational, or genuinely architectural?
If the answer to either points inward, enforcing module boundaries inside a single deployable is the right call - not a stepping stone, but a valid destination.
How Migration Works, Step by Step
Migration follows an atomic, incremental pattern. Each extraction step must be fully completed (new service built, all consumers redirected, old code path retired) before moving to the next. Leaving parallel implementations active doubles maintenance surface and accumulates technical debt. The architecture should improve after every step, not just at the end.
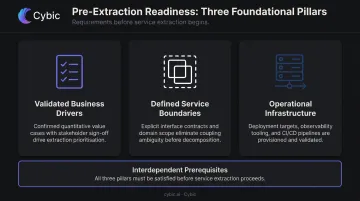
The Three Preparation Pillars
Before extracting a single service, three things must be in place:
- Validated business drivers - confirm the monolith is a genuine decomposition candidate based on operational evidence, not assumption
- Defined service boundaries - use Domain-Driven Design to identify bounded contexts through event storming sessions and dependency mapping
- Operational infrastructure - CI/CD pipelines, containerization, API gateway, distributed logging, and monitoring must exist before the first service ships
On service boundaries: a bounded context is an area of the domain with distinct business logic and minimal external overlap. AWS recommends decomposing by business capability - what a business does to generate value - rather than by technical layer.
Cutting services by UI layer, data layer, or business logic layer preserves coupling under a different name. The result is tightly coupled microservices that are harder to change than the original monolith.
Phase 1: Extract a Low-Risk, Peripheral Service First
Start with something non-critical : authentication, notification handling, or reporting. Choose a service with minimal upstream and downstream dependencies.
The objective here isn't business value from this service alone. It's validation: do the deployment pipelines work? Does monitoring surface failures correctly? Can the team execute a rollback cleanly under real conditions? These questions need answers before touching core functionality.
Phase 2: Extract Core Business Capabilities Vertically
Once the team has proven the deployment and rollback mechanisms work, move to capabilities that matter operationally. Prioritize based on two factors: what's changing most frequently, creating delivery bottlenecks, and what needs to scale independently.
Extract capabilities vertically : the capability and its data together. Building facade services that still share the monolith's database produces the distributed monolith anti-pattern: all the complexity of distributed systems, none of the data independence that makes them worthwhile.
Phase 3: Retire Old Code Paths Completely
Each extraction is only finished when the monolith's original code path is decommissioned and all consumers are on the new service. Retiring old code is not optional cleanup. It's a mandatory part of each increment.
Leaving both implementations active defeats the purpose of decomposition and guarantees long-term maintenance burden.
Proven Migration Patterns and Data Decomposition
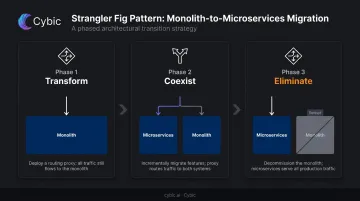
Strangler Fig Pattern
A proxy or API gateway sits in front of the monolith and intercepts inbound requests. Initially, all traffic routes to the monolith. As new microservices are built and validated, routing rules redirect specific calls. Over time, the monolith handles less and less until it can be retired entirely.
AWS describes the transition as three phases: transform, coexist, eliminate. Best suited for externally-facing functionality where routing can be intercepted cleanly at the boundary.
Branch by Abstraction
Create an abstraction layer inside the monolith around the functionality being extracted. Both the existing implementation and the new microservice exist behind this abstraction, with feature flags controlling which is active.
Fowler's definition describes it as making large-scale changes while continuing regular releases - add the abstraction, migrate callers, build the new implementation, remove the old one. Best suited for functionality deeply embedded in the monolith that can't be intercepted from outside.
Parallel Run Pattern
Both the monolith and the new microservice process the same requests simultaneously. Only the monolith's response is returned initially. Results are compared to verify behavioral equivalence before any traffic shifts.
Zalando's engineering team used this pattern to decompose a high-traffic monolith into smaller microservices. Both systems ran in parallel until the new services demonstrated consistent, reliable behavior under production load. Use this approach for mission-critical functionality where even subtle behavioral differences carry real risk.
Data Decomposition - The Hardest Part
Shared databases are the most common reason migrations stall. The Tracer Write pattern (detailed in Sam Newman's Monolith to Microservices) migrates data incrementally - one table or aggregate at a time - while keeping both sources in sync during the transition.
For operations that span multiple services, Sagas replace cross-service ACID transactions. As defined on microservices.io, a Saga is a sequence of local transactions where each updates its own database and triggers the next step. If a step fails, compensating transactions roll back prior changes. AWS supports both choreography and orchestration approaches to Saga coordination.
Both patterns depend on one non-negotiable principle: each service must own and manage its own data store. Without that boundary, data decomposition never completes.
Mistakes to Avoid - and When Not to Migrate
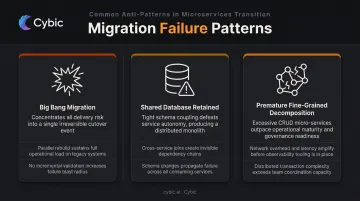
Common Mistakes
Three patterns account for most failed migrations:
- Big bang migration: Rebuilding the entire system in parallel before replacing the monolith eliminates incremental rollback, concentrates all risk at cutover, and is the most common reason large efforts stall or get abandoned.
- Shared database retained: Decoupling at the application layer while leaving services on a common database produces a distributed monolith - operational complexity without the data independence that justifies it.
- Premature fine-grained decomposition: Dozens of small CRUD services before the team has operational maturity creates debugging nightmares and unclear ownership. Start with macro-services aligned to full business domains; subdivide only when each service can be independently operated and monitored.
When Migration Is the Wrong Call
| Signal | Implication |
|---|---|
| Unclear domain boundaries | Wrong cuts create tightly coupled microservices harder to change than the original monolith |
| Early-stage product | Rapid domain shifts make stable service boundaries impractical |
| Small team | Distributed systems require operational capacity most small teams don't yet have |
| No specific operational problem | Without a defined pain point, there's no success criterion |
A well-structured modular monolith is not a consolation prize - for many teams, it's the right call.
Closing Thoughts
Successful migration requires three things: clear business goals, an incremental approach, and the discipline to retire old code paths when each step is done. Microservices are a tool for achieving operational outcomes - not an architectural destination.
For enterprises in regulated environments - manufacturing, energy, healthcare, BFSI - migration must be executed with governance, security controls, and infrastructure integration considered from the start, not retrofitted. Compliance requirements don't pause during the migration.
Cybic's legacy modernization practice is built around this reality. Engagements span the full lifecycle: assessment, architecture design, build, integration, and post-deployment support - with governance controls like RBAC, encrypted data handling, and audit trails embedded at the architectural level across cloud, hybrid, and on-premises environments.
The goal is working systems in production, not a stack of architecture documents.
Frequently Asked Questions
What is the difference between a monolith and microservices architecture?
A monolith is a single deployable unit with a shared codebase and typically a shared database. Microservices are independently deployable services that each own their own logic and data, communicating through APIs. The key difference isn't size - it's deployment independence and data ownership.
How long does a monolith-to-microservices migration typically take?
Timelines depend on monolith complexity, team capacity, and data migration scope - ranging from several months to a few years for large systems. Incremental migration means value is delivered continuously throughout, rather than at the end of a fixed project.
What is the Strangler Fig pattern in microservices migration?
The Strangler Fig pattern replaces a monolith incrementally by routing traffic through a proxy to new microservices as they're built, while the monolith handles everything else. As more services are extracted, the monolith's traffic share shrinks until it can be decommissioned - without disrupting the live system.
Should every company migrate from a monolith to microservices?
No. Microservices introduce real operational complexity. A well-structured monolith or modular monolith is often the better choice for small teams, early-stage products, or systems without clear domain boundaries. Migrate when you have a specific operational problem that decomposition actually solves.
How do you handle database migration when moving to microservices?
Data must be decoupled alongside the service, not left shared. The Tracer Write pattern handles incremental migration by keeping sources synchronized during the transition. For distributed transactions, Sagas coordinate state changes across services using local transactions with compensating rollback steps.
What is the biggest challenge in a monolith-to-microservices migration?
Database decomposition and organizational change are consistently the hardest parts. Technical patterns exist for the data side. The harder problem is cultural: teams need to shift from shared-codebase collaboration to independent service ownership, which requires different skills, accountability structures, and operational habits.


